Hello, I have shiny apps running on RStudio Connect that are published with data in feather files.
I have an RMarkdown that I run separately to connect to a database to create the feather files that are published with the App. I would now like to move to daily automated updates so I'd like to schedule the RMarkdown file to run in the early AM hours to create the feather files, then have the app read those feather files. So....
I'm struggling to find an example of exactly how to go about this, not sure if there's a good reference for a setup like this somewhere?
From the reading I've done, I'm still not sure where I should write the files to on the server so I would appreciate thoughts on that.
Also it sounds like i would need to restart the shiny app post data update to pick up those changes, I'm not sure if there's a way to schedule your shiny app to restart via Connect somehow?
I am assume the data is saved in a location where both the RMarkdown and Shiny app can read from and all on connect. You shouldn't need to restart the shiny app, but rather the shiny app should be looking for changes in the file itself. Take a look at https://shiny.rstudio.com/reference/shiny/1.0.0/reactiveFileReader.html
I suggest finding an "absolute file path" that has read/write privileges on your connect server. The relative file path is based on the deployed package.
That was the plan. I read the article about using absolute path and the sample showed putting a csv in /app-data/. I guess I wasn’t sure if that’s the recommended location or if it doesn’t really matter where it ends up as long as the permissions are correct. I’m thinking separate folders for each app. Thanks.
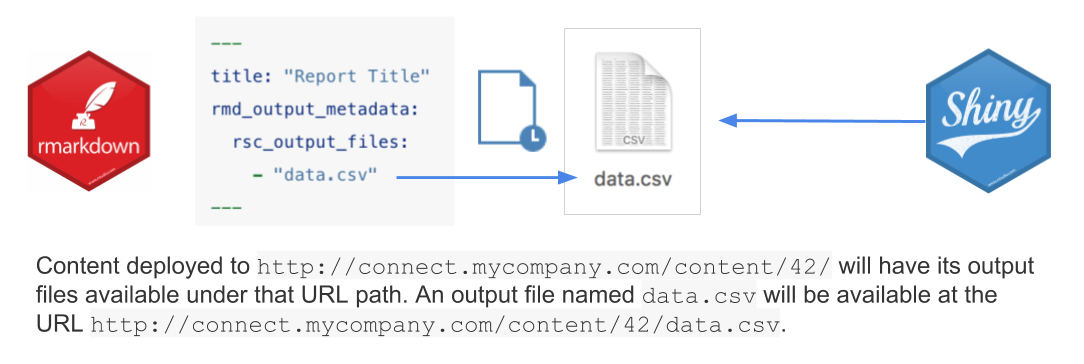
This CSV file is subject to the same authorization as your report. Your Shiny application can perform an authenticated HTTP request using a Connect API key.
The last piece is updating that data in the Shiny app after each Rmd render. Use shiny::reactivePoll to detect when the data.csv changes. The Last-Modified information of the HTTP request indicates if the data file has been updated. If the feather file is large, I recommend performing a HEAD request for the Last-Modified data. Once you know the file has changed, issue a GET request.
This approach means you can develop your Shiny application using the Connect-generated Rmd output without relying on the local file system. Connect also maintains each version of your data.csv alongside the historical rendered output.
In summary:
Have your Rmd declare and produce some number of output files.
Load those output files over HTTP from your Shiny application.
I've worked up a basic framework example for using R Markdown output files in an ETL process to feed a shiny application (gist). It doesn't cover the shiny::reactivePoll piece that @aron mentioned above, but it's a start.
@aron and @kellobri,
Wow thank you so much for your response on this. I think this should get me most of what I need. Apologies in the delay I was at a conference and traveling. Really appreciate the insights, documentation references and example, this will be a significant time saver!