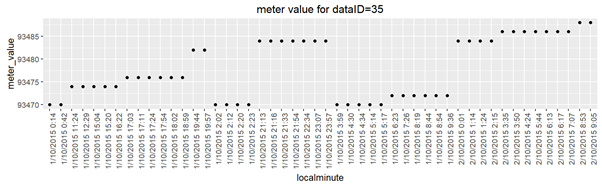
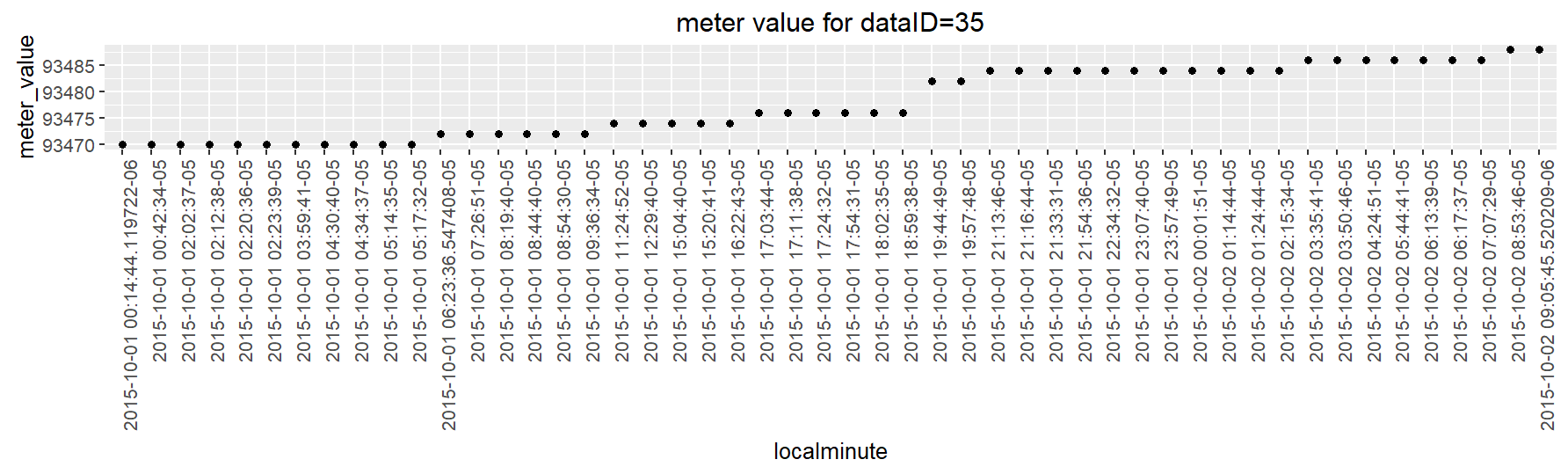
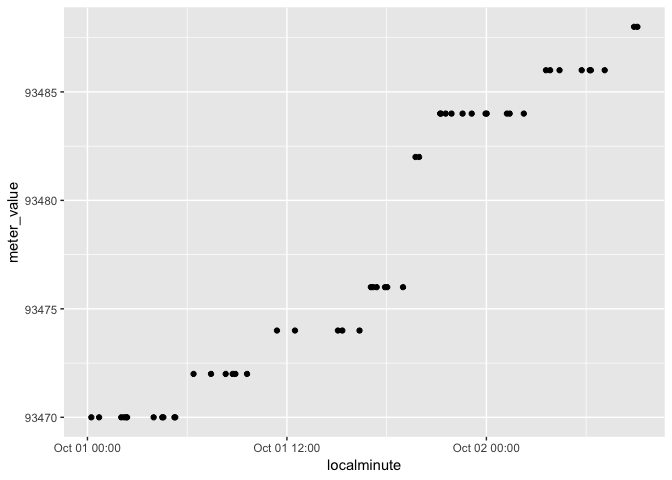
You need to adapt the parsing string to the data. You presented a couple versions of the data which each require different parsing strings.
For the Markdown table/pipe-delimited version, you can use lubridate::ymd_hm (there are no seconds), which is equivalent to lubridate::parse_date_time with "Ymd HM" for the orders parameter. No time zones are supplied with this data, so this may be off from the real-world data:
library(tidyverse)
PlotD <- structure(list(localminute = c("1/10/2015 0:14", "1/10/2015 0:42", "1/10/2015 2:02", "1/10/2015 2:12", "1/10/2015 2:20", "1/10/2015 2:23", "1/10/2015 3:59", "1/10/2015 4:30", "1/10/2015 4:34", "1/10/2015 5:14", "1/10/2015 5:17", "1/10/2015 6:23", "1/10/2015 7:26", "1/10/2015 8:19", "1/10/2015 8:44", "1/10/2015 8:54", "1/10/2015 9:36", "1/10/2015 11:24", "1/10/2015 12:29", "1/10/2015 15:04", "1/10/2015 15:20", "1/10/2015 16:22", "1/10/2015 17:03", "1/10/2015 17:11", "1/10/2015 17:24", "1/10/2015 17:54", "1/10/2015 18:02", "1/10/2015 18:59", "1/10/2015 19:44", "1/10/2015 19:57", "1/10/2015 21:13", "1/10/2015 21:16", "1/10/2015 21:33", "1/10/2015 21:54", "1/10/2015 22:34", "1/10/2015 23:07", "1/10/2015 23:57", "2/10/2015 0:01", "2/10/2015 1:14", "2/10/2015 1:24", "2/10/2015 2:15", "2/10/2015 3:35", "2/10/2015 3:50", "2/10/2015 4:24", "2/10/2015 5:44", "2/10/2015 6:13", "2/10/2015 6:17", "2/10/2015 7:07", "2/10/2015 8:53", "2/10/2015 9:05"),
dataid = c(35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L),
meter_value = c(93470L, 93470L, 93470L, 93470L, 93470L, 93470L, 93470L, 93470L, 93470L, 93470L, 93470L, 93472L, 93472L, 93472L, 93472L, 93472L, 93472L, 93474L, 93474L, 93474L, 93474L, 93474L, 93476L, 93476L, 93476L, 93476L, 93476L, 93476L, 93482L, 93482L, 93484L, 93484L, 93484L, 93484L, 93484L, 93484L, 93484L, 93484L, 93484L, 93484L, 93484L, 93486L, 93486L, 93486L, 93486L, 93486L, 93486L, 93486L, 93488L, 93488L)),
class = "data.frame", row.names = c(NA, -50L))
PlotD %>%
mutate(localminute = lubridate::dmy_hm(localminute)) %>%
ggplot(aes(x = localminute, y = meter_value)) +
geom_point()
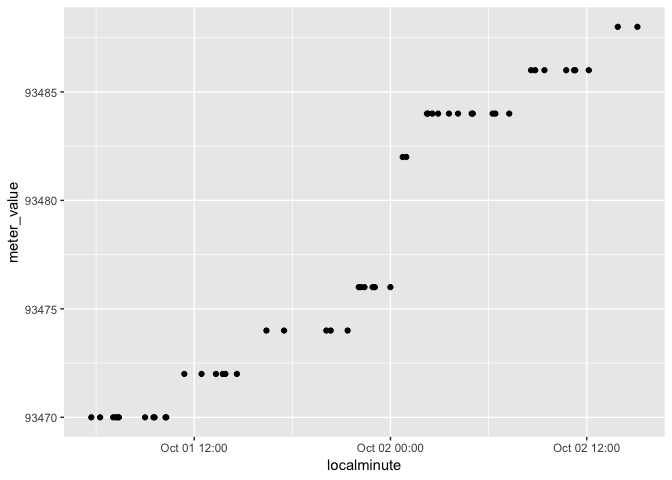
For the CSV formatted one, you need to use decimal seconds and a timezone offset, which lubridate's shortcut parsers can't do, but its full-bore parse_date_time can:
library(tidyverse)
PlotD <- structure(list(localminute = c("2015-10-01 00:14:44.119722-06", "2015-10-01 00:42:34-05", "2015-10-01 02:02:37-05", "2015-10-01 02:12:38-05", "2015-10-01 02:20:36-05", "2015-10-01 02:23:39-05", "2015-10-01 03:59:41-05", "2015-10-01 04:30:40-05", "2015-10-01 04:34:37-05", "2015-10-01 05:14:35-05", "2015-10-01 05:17:32-05", "2015-10-01 06:23:36.547408-05", "2015-10-01 07:26:51-05", "2015-10-01 08:19:40-05", "2015-10-01 08:44:40-05", "2015-10-01 08:54:30-05", "2015-10-01 09:36:34-05", "2015-10-01 11:24:52-05", "2015-10-01 12:29:40-05", "2015-10-01 15:04:40-05", "2015-10-01 15:20:41-05", "2015-10-01 16:22:43-05", "2015-10-01 17:03:44-05", "2015-10-01 17:11:38-05", "2015-10-01 17:24:32-05", "2015-10-01 17:54:31-05", "2015-10-01 18:02:35-05", "2015-10-01 18:59:38-05", "2015-10-01 19:44:49-05", "2015-10-01 19:57:48-05", "2015-10-01 21:13:46-05", "2015-10-01 21:16:44-05", "2015-10-01 21:33:31-05", "2015-10-01 21:54:36-05", "2015-10-01 22:34:32-05", "2015-10-01 23:07:40-05", "2015-10-01 23:57:49-05", "2015-10-02 00:01:51-05", "2015-10-02 01:14:44-05", "2015-10-02 01:24:44-05", "2015-10-02 02:15:34-05", "2015-10-02 03:35:41-05", "2015-10-02 03:50:46-05", "2015-10-02 04:24:51-05", "2015-10-02 05:44:41-05", "2015-10-02 06:13:39-05", "2015-10-02 06:17:37-05", "2015-10-02 07:07:29-05", "2015-10-02 08:53:46-05", "2015-10-02 09:05:45.520209-06"),
dataid = c(35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L),
meter_value = c(93470L, 93470L, 93470L, 93470L, 93470L, 93470L, 93470L, 93470L, 93470L, 93470L, 93470L, 93472L, 93472L, 93472L, 93472L, 93472L, 93472L, 93474L, 93474L, 93474L, 93474L, 93474L, 93476L, 93476L, 93476L, 93476L, 93476L, 93476L, 93482L, 93482L, 93484L, 93484L, 93484L, 93484L, 93484L, 93484L, 93484L, 93484L, 93484L, 93484L, 93484L, 93486L, 93486L, 93486L, 93486L, 93486L, 93486L, 93486L, 93488L, 93488L)),
class = "data.frame", row.names = c(NA, -50L))
PlotD %>%
mutate(localminute = lubridate::parse_date_time(localminute, 'Ymd HMS!z!')) %>%
ggplot(aes(x = localminute, y = meter_value)) +
geom_point()
For documentation, start with ?strptime. That function doesn't get used much anymore (it returns POSIXlt class, which [deliberately] doesn't play nice in tibbles), but it is where base R's date-time parsing token system (used in as.POSIXct and as.Date, as well) is documented. Next read ?lubridate::parse_date_time, which shows that lubridate is a riff on the basic strptime format that in some contexts does not require the % and delimiter characters to be supplied. It also includes some other special tokens, including the %S! and %z! used above.