I haven't looked through the entire thread, but seeing localminute as a factor raised alarm bells.
You should try this instead:
PlotD <- read.csv("test_R.csv", stringsAsFactors = FALSE)
Apologies if this has already been addressed in the thread.
I haven't looked through the entire thread, but seeing localminute as a factor raised alarm bells.
You should try this instead:
PlotD <- read.csv("test_R.csv", stringsAsFactors = FALSE)
Apologies if this has already been addressed in the thread.
Hi Martin,
what does the "stringsAsFactors = FALSE" mean?
I tried as u suggested, but the X-axis, display time format is yyyy-mm-dd hh:mm:ss.xxxxx-nnn (xx are decimal of second, and -nn is timezone offset).
I want to set X-axis as "yyyy-mm-dd hh:mm:ss" only.
It means the data is read in as a string, rather than a factor.
You can then convert the string into your desired datetime format, which some of the previous posts addressed.
Hi All,
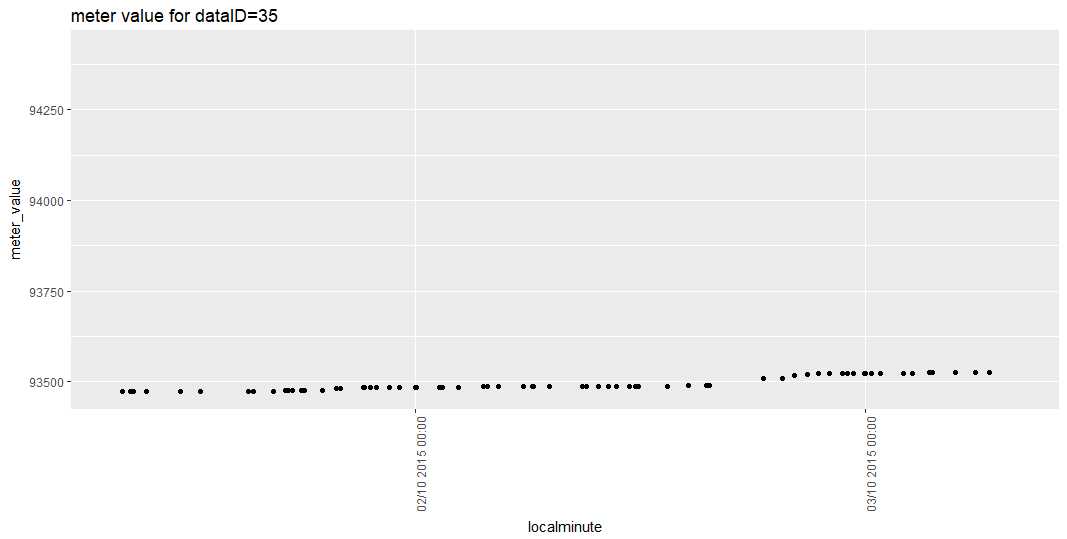
I have to plot 11872 data, (data is same as my earlier post), I also attached the data file, actual file is in csv but i only can upload pdf version. i used "ggplot" comment but got error "error in usemethod("depth") :...
test_35-copy.pdf (961.2 KB)
> test <- read.csv("test_35.csv") #read data in csv file, to plot data
> ggplot(test, aes(x = localminute, y = meter_value)) + geom_point() + ggtitle("meter value for dataID=35") + theme(axis.text.x = element_text(angle = 90, hjust = 1))
Error in UseMethod("depth") :
no applicable method for 'depth' applied to an object of class "NULL"Hi May,
Your question to @jcblum yesterday may have clarified an area of misunderstanding.
I am concerned that, we could not see the X-axis, if I plot all data (1,584,823 data). How should I plot all data, by scaling X-axis (24 hour gap), as the image below, that I plotted in excel.
It sounds like you are wondering about the axis labels, and how to make sure there aren't so many that they overlap. A few people have suggested you change localtime into a datetime format. These ideas are related.
The reason is that ggplot assumes that strings and factors are discrete categories, where all of them should be labeled on the axis. (For instance, jelly bean flavors. It's not obvious what the point halfway between "cherry" and "licorice" would be. So you usually have to label the axis with every flavor you want to show.) As you're finding, this doesn't work well if you have more categories than whose names can fit.
But numbers and dates are interpreted differently, as continuous variables that live on a quantifiable spectrum. ggplot knows (like Excel) to only label a few significant points, since the reader will know how to interpolate between the labels to get a reasonable guess of the values in between.
So we should convert the localminute text into a datetime variable, Then ggplot will know where to place the data point. It will also place some regular datetime labels on the x-axis.
If you specifically want a label each 24 hours, you could add the line
scale_x_datetime(date_breaks = "1 day") +
or add some more options to make the date labels more like your Excel example:
scale_x_datetime(date_breaks = "1 day", date_labels = "%d/%m/%Y", minor_breaks = NULL) +
Here's the code I suggested before for interpreting the localminute string as a datetime, with the x axis labeled at the start of each new day.
library(tidyverse)
data_20180415 <- data.frame(
localminute = c("2015-09-30 00:14:44.119722-06", "2015-10-01 00:42:34-05",
"2015-10-01 02:02:37-05", "2015-10-01 02:12:38-05",
"2015-10-01 02:20:36-05", "2015-10-01 02:23:39-05",
"2015-10-01 03:59:41-05", "2015-10-01 04:30:40-05", "2015-10-01 04:34:37-05",
"2015-10-01 05:14:35-05", "2015-10-01 05:17:32-05",
"2015-10-01 06:23:36.547408-05", "2015-10-01 07:26:51-05",
"2015-10-01 08:19:40-05", "2015-10-01 08:44:40-05", "2015-10-01 08:54:30-05",
"2015-10-01 09:36:34-05", "2015-10-01 11:24:52-05",
"2015-10-01 12:29:40-05", "2015-10-01 15:04:40-05",
"2015-10-01 15:20:41-05", "2015-10-01 16:22:43-05", "2015-10-01 17:03:44-05",
"2015-10-01 17:11:38-05", "2015-10-01 17:24:32-05",
"2015-10-01 17:54:31-05", "2015-10-01 18:02:35-05",
"2015-10-01 18:59:38-05", "2015-10-01 19:44:49-05", "2015-10-01 19:57:48-05",
"2015-10-01 21:13:46-05", "2015-10-01 21:16:44-05",
"2015-10-01 21:33:31-05", "2015-10-01 21:54:36-05", "2015-10-01 22:34:32-05",
"2015-10-01 23:07:40-05", "2015-10-01 23:57:49-05",
"2015-10-02 00:01:51-05", "2015-10-02 01:14:44-05",
"2015-10-02 01:24:44-05", "2015-10-02 02:15:34-05", "2015-10-02 03:35:41-05",
"2015-10-02 03:50:46-05", "2015-10-02 04:24:51-05",
"2015-10-02 05:44:41-05", "2015-10-02 06:13:39-05", "2015-10-02 06:17:37-05",
"2015-10-02 07:07:29-05", "2015-10-02 08:53:46-05",
"2015-10-03 09:05:45.520209-06"),
dataid = c(35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L,
35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L,
35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L,
35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L, 35L,
35L),
meter_value = c(93470L, 93470L, 93470L, 93470L, 93470L, 93470L, 93470L,
93470L, 93470L, 93470L, 93470L, 93472L, 93472L, 93472L,
93472L, 93472L, 93472L, 93474L, 93474L, 93474L, 93474L, 93474L,
93476L, 93476L, 93476L, 93476L, 93476L, 93476L, 93482L, 93482L,
93484L, 93484L, 93484L, 93484L, 93484L, 93484L, 93484L,
93484L, 93484L, 93484L, 93484L, 93486L, 93486L, 93486L, 93486L,
93486L, 93486L, 93486L, 93488L, 93488L)
)
data_20180415_split <-
data_20180415 %>%
mutate(lm_length = nchar(localminute %>% as.character()),
lm_base = localminute %>% substr(0, lm_length-3),
lm_offset = localminute %>% substr(lm_length-1, lm_length) %>% as.integer) %>%
mutate(lm_norm = lubridate::ymd_hms(lm_base) + lubridate::dhours(lm_offset))
ggplot(data_20180415_split,
aes(x = lm_norm, y = meter_value)) +
geom_point() + ggtitle("meter value for dataID=35") +
scale_x_datetime(date_breaks = "1 day", date_labels = "%d/%m %Y", minor_breaks = NULL) +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
Hi JonSpring,
I can get the plot from your suggested code. I can see the plot with x-axis is in dd/mm/yyyy format with 24hr gap.
from your suggested code, localminute is put in data frame "data_20180415"
I have some enquiry, if you dont mind.
Why put "35L" in the dataid?
will this data frame, be useful for large data set (1million data)? as I have to copy, paste all the data in local minute, dataID and meter_value.
Could explain this code below? I didnt understand the function: mutate(lm_length, lm_base, lm_offset, lm_norm)
data_20180415_split <- data_20180415 %>%
mutate(lm_length = nchar(localminute %>% as.character()),
lm_base = localminute %>% substr(0, lm_length-3),
lm_offset = localminute %>% substr(lm_length-1, lm_length) %>% as.integer) %>%
mutate(lm_norm = lubridate::ymd_hms(lm_base) + lubridate::dhours(lm_offset))
The data frame "data_20180415" is a copy of your earlier post's data. I made it using the datapasta addin, which assumed all the dataid's were integers. The addin added the L's, which tell R to interpret the number as an integer. I bet it would be fine with or without.
side note: Perhaps you're not using the "dataid" field downstream, but in case you are, it's worth understanding how different types will sort in R. Integers and other numeric numbers will sort in order of size (so 35 will come before 100), characters will sort alphanumerically (so 100 will come before 35), and factors can be given a sort order of your choosing. That might be useful if you wanted to show different "dataid" plots as different facets in ggplot, perhaps arranged in order of meter values or some other metric.
I added that data frame as code so that you or anyone else on this thread could it to load that same sample data frame. Most of the time in R, we load data through some other means, like you did to get your PlotD data. As long as you have that data table loaded, you should be good to go to use the subsequent code, which transforms the data into the formats that we need for plotting.
So you should be able to plot your whole data set in the same fashion. Let's step through an application of that code to your full data. Perhaps something like:
PlotD_timestamped <- # This creates a new table PlotD_timestamped, that will...
# start from PlotD...
PlotD %>%
# Add a new column called lm_length with the length of the localminute character string.
# This may be useful for debugging so we can see that it's working right.
# Note that localminute has varying precision, sometimes with fractional seconds.
# "2015-10-03 09:05:45.520209-06" or "2015-10-01 08:19:40-05" are both valid.
mutate(lm_length = nchar(localminute %>% as.character()),
# add a new column that is everything but the last 3 characters of localminute
lm_base = localminute %>% substr(0, lm_length-3),
# add a new column that is the last two characters of localminute and make them an integer
lm_offset = localminute %>% substr(lm_length-1, lm_length) %>% as.integer) %>%
# add a new column that transforms the first segment into a datetime, and adds
# an offset number of hours based on the last segment.
mutate(lm_norm = lubridate::ymd_hms(lm_base) + lubridate::dhours(lm_offset))
# Now there should be a new dataframe where localminute will be understood
# as a datetime, which will help for plotting.
# Then it should be possible to feed this new table into your code
ggplot(PlotD_timestamped,
aes(x = lm_norm, y = meter_value)) +
geom_point() + ggtitle("meter value for dataID=35") +
scale_x_datetime(date_breaks = "1 day", date_labels = "%d/%m %Y", minor_breaks = NULL) +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
Hi JonSpring,
Thanks alot for your explaination. I can plot the 11872 meter values of dataID=35.
I used your suggested codes-using 30days gap at X-axis, and the output plot is as below.
I noticed there is discrete point, unlike other points in the plot that I highlighted in the attached png file.
Is it possible to zoom in, the plot and find out where is it. I use the X-axis gap to 5 days, but still can see the discrete points.
Secondly, I would like to display that this graph has plotted "11872 data". May I know what function should I use?
I have tried this code and I got same plot as your suggested code.
Is it colClasses function recommended to use for analyzing data?
by using colClasses function, I can straightaway use ggplot command after read the csv file.
Only difference is the output of str().
> test3 <- read.csv("test_35.csv")
> str(test3)
'data.frame': 11872 obs. of 3 variables:
$ localminute: Factor w/ 11872 levels "2015-10-01 00:14:44-05",..: 1 2 3 4 5 6 7 8 9 10 ...
$ dataid : int 35 35 35 35 35 35 35 35 35 35 ...
$ meter_value: int 93470 93470 93470 93470 93470 93470 93470 93470 93470 93470 ...
> test3a <- read.csv('test_35.csv', colClasses = c('POSIXct', 'integer', 'integer')) #specify variable format
> str(test3a)
'data.frame': 11872 obs. of 3 variables:
$ localminute: POSIXct, format: "2015-10-01 00:14:44" "2015-10-01 00:42:34" "2015-10-01 02:02:37" "2015-10-01 02:12:38" ...
$ dataid : int 35 35 35 35 35 35 35 35 35 35 ...
$ meter_value: int 93470 93470 93470 93470 93470 93470 93470 93470 93470 93470 ...Yes, using colClasses inside read.csv seems like a good solution to get the datetime in correctly from the start. My only concern would be those time zone offsets that came up in your sample...
You can also use 1 month breaks if you prefer vs. 30 days:
scale_x_datetime(date_breaks = "1 month", date_labels = "%d/%M/%Y", date_minor_breaks = NULL) +
It looks like there's a missing point in your data. If that's to be expected and you just want the chart to look clean, I'd suggest using geom_line() for your plot instead of geom_point.
If the missing point is of concern, you might like to use the plotly package, which lets you literally zoom in and explore the chart interactively. There's a great function that will take your ggplot and convert it into a plotly object.
library(plotly)
a <- ggplot(test3a, # Note, this is assigning the ggplot object to "a", but not displaying it.
aes(x = localminute, meter_value)) +
geom_point() + ggtitle("meter value for dataID=35") +
scale_x_datetime(date_breaks = "30 days", date_labels = "%d/%m %Y", minor_breaks = NULL) +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
a # This isn't necessary but will print the ggplot object "a" normally, just for demonstration.
plotly::ggplotly(a) # this will convert the ggplot object "a" into an interactive plotly chart.
If the gap is of concern and you're repeating this analysis for many meters, it might be preferable to approach it algorithmically so it can be automated. For instance, it might be helpful to take the test3a data and identify the gaps that are longer than some threshold, to understand outages.
gaps <-
test3a %>%
group_by(dataid) %>% # for each meter...
arrange(localminute) %>% # arrange chronologically..
# ...and then show how many hours have passed since the prior reading
mutate(gap_hrs = (localminute - lag(localminute)) / lubridate::dhours(1)) %>%
# ...and just keep the ones that are (this is arbitrary) 4x the median gap length
filter(gap_hrs > 4 * median(gap_hrs, na.rm = TRUE))
# 2018-05-24 edit: replaced "median(gap" with "median(gap_hrs" in last line.
Hi Jonspring,
Just to confirm, using the colClasses inside read.csv will ignore the time zone and the decimal part for seconds? I dont mind, time zone offsets in my sample, since I do not want to display and use it for data processing.
for "scale_x_datetime" function: if I want to add hh:mm:ss in the X-axis, shall I add like this?
scale_x_datetime(date_breaks = "1 month", date_labels = "%d/%M/%Y %h %m %s", date_minor_breaks = NULL) +
I tried plotly, but the "R studio" software is not responding when I wants to zoom in the certain part of plot. I can see the zoom icon, but the software is hang which I guess, due to large data in the plot.
Is there any alternative ways to zoom, certain part in the plot?
What function should I use, if I want to plot certain period (eg. only from 01-Oct-2015 to 31-Oct-2015)?
I tried your suggested gap codes, but I got error. that's the flow of code
> library(tidyverse)
> library(lubridate)
> test <- read.csv('test_35.csv', colClasses = c('POSIXct', 'integer', 'integer'))
> gaps <- test %>%
+ group_by(dataid) %>% # for each meter...
+ arrange(localminute) %>% # arrange chronologically..
+ # ...and then show how many hours have passed since the prior reading
+ mutate(gap_hrs = (localminute - lag(localminute)) / lubridate::dhours(1)) %>%
+ # ...and just keep the ones that are (this is arbitrary) 4x the median gap length
+ filter(gap_hrs > 4 * median(gap, na.rm = TRUE))
#error message below:
Error in filter_impl(.data, quo) :
Evaluation error: object 'gap' not found.The encoding for the pieces of datetimes is tricky! For times, you want capital letters: %H %M %S, otherwise you get other stuff: month name abbreviated, decimal month, and "seconds since epoch" (!).
https://www.stat.berkeley.edu/~s133/dates.html
https://stat.ethz.ch/R-manual/R-devel/library/base/html/strptime.html
This should work:
scale_x_datetime(date_breaks = "1 day", date_labels = "%d/%m/%Y %H:%M:%S", minor_breaks = NULL) +
If plotly isn't working, there are a few ways you could zoom in on your data.
a <- ggplot(test3a %>%
filter(localminute >= ymd(20151001),
localminute <= ymd(20151031)),
aes(x = localminute, y = meter_value)) +
scale_x_datetime(date_breaks = "1 day", date_labels = "%d/%m %Y %H:%M:%S", minor_breaks = NULL,
limits = c(ymd_hm(201510010000), ymd_hm(201510022359))) +
coord_cartesian(xlim = c(ymd_hm(201510010000), ymd_hm(201510011000))) +
Finally, it looks like I accidentally wrote "median(gap" in that last line where I mean "median(gap_hrs".
Hi jonspring,
Thanks for info. I tried your suggested code.
scale_x_datetime(date_breaks = "10 days", date_labels = "%d/%m/%Y %H:%M:%s", minor_breaks = NULL) + # to display dd/mm/yyyy hh:mm:ss but the X-axis display 10 digits of seconds.
well, if the encoding for second is tricky then, I will remove second in output plot.
for filtering source, the output plot X-axis only show two days.
a <- ggplot(test3a %>%
+ filter(localminute >= ymd(20151001),
+ localminute <= ymd(20151031)),
+ aes(x = localminute, y = meter_value)) + geom_point() + ggtitle("meter value for dataID=35") + scale_x_datetime(date_breaks = "1 day", date_labels = "%d/%m %Y %H:%M", minor_breaks = NULL,limits = c(ymd_hm(201510010000), ymd_hm(201510022359))) + theme(axis.text.x = element_text(angle = 90, hjust = 1))
> plot(a)
Warning message:
Removed 1495 rows containing missing values (geom_point).
As I have plotted 11872 meter values of dataID=35, and I would like to display message that "11872 data" has plotted.
so that it verify that we have no missing data in plot. how should I verify?
The warning message before your plot suggests that the localminute and/or the meter_value can't be plotted for 1,495 of the rows in test3a. That could be a sign that some of the data is not getting imported or interpreted the way you expected. Maybe the localminute isn't getting parsed for those rows, or the meter_value is NA for those?
If you run summary(test3a), what output do you get? Are there NAs in localminute or meter_value?
Hi Jonspring,
I checked the csv file, there is no NA in localminute and meter value. I am curious that, I can plot all data, with colClasses when reading the csv file, but could not plot if I want to plot certain period for local minute .
Correct me, if I am wrong. the output of summary(test3a), just give the minimum data and max data, which just showing 1st and last data.
Is there any other functions to verify 11872, data was plotted.
> summary(test3a) #output below, after run
localminute dataid meter_value
Min. :2015-10-01 00:14:44 Min. :35 Min. : 93470
1st Qu.:2015-11-20 21:55:00 1st Qu.:35 1st Qu.: 95402
Median :2016-01-02 05:59:22 Median :35 Median : 98397
Mean :2016-01-01 23:03:12 Mean :35 Mean : 98800
3rd Qu.:2016-02-12 06:53:31 3rd Qu.:35 3rd Qu.:102309
Max. :2016-03-31 23:22:09 Max. :35 Max. :104692