(as suggested, related to this thread
Thoughts and tips on organizing models for a machine learning project - #19 by rquintino)
This specific need/concern keeps on top of my mind, and still to know a productive solution for this... how to save/track models, including all params, ,code, ex:git commits, data? enable team sharing? results comparison/evaluation, including between different metadata/pipeline options?
I've been researching a lot ![]() , so would be very fond of working on this concepts &thread.
, so would be very fond of working on this concepts &thread.
Not specifically for production tracking models, but on dev/prototype phase, how to proper save/track/compare/evaluate different results in the ml project, for each possible path on the dag, tend to see ml projects as a groups of dags (pipeline, params, algorithms, hyperparams)?
Why are teams wasting so much cpu training things that get "lost"? never properly compared/evaluated? never shared with the team?
When anyone reaches a model result, kind of be able to just do track(model,any_additional_metadata_I_may_add) to team shared storage (for me, should to be that dead simple... see openml publish), it would be able to track final result from the dag path, adding each node params/parent node params, something like that. So everything can be comparable. And reload/compare whenever needed. Persisted. Not for every model, but for specific model milestones, or models we want to just compare with previous ones.
small experiment just to illustrate:
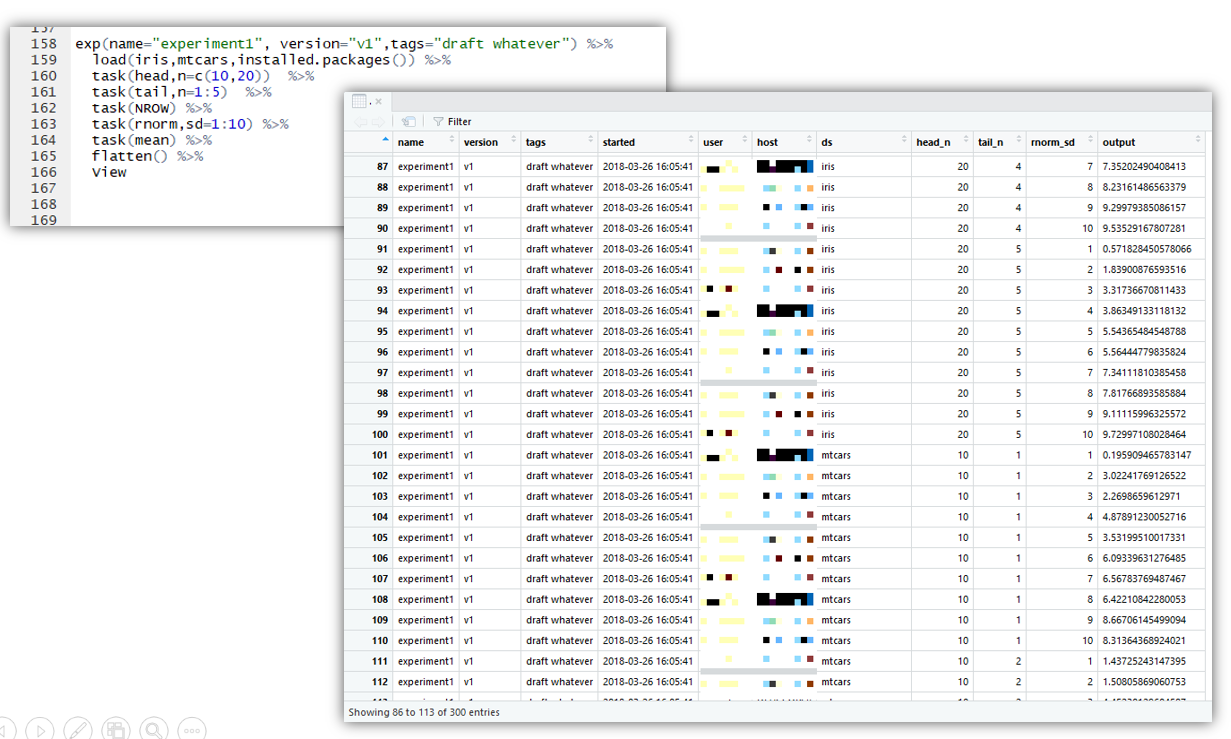
(not persisting any to filesystem though, now I would like something to track the dag result nodes. note: this served just to ask on twitter if there are similar packages already, Steph Locke shared recipes with me, which is amazing note: python has GitHub - scikit-learn-contrib/sklearn-pandas: Pandas integration with sklearn)
Also why can't we jointly compare R/python models? At least results/prediction wise should be possible, openml/mlr actually has very good concepts here (namely concept of agnostic machine learning task, as the root node in the dag).
But in a kind of private/team openml server, ex: one for project? Preference for filesystem based storage (no server), ex: csv for metadata, predictions, datasets, resample fold info, binary only for actual models. So mostly everything could be reused R/python/others. (ex: just start a docker image on the results folder to get an model UI eval tool, like openml)
Ideas? Quick alternatives? Does this already exist? Thanks for the brainstorm!
Rui
ps-some references
https://mitdbg.github.io/modeldb/
http://modeldb.csail.mit.edu:3000/projects
https://kaixhin.github.io/FGLab/
https://docs.microsoft.com/en-us/azure/machine-learning/preview/how-to-use-run-history-model-metrics