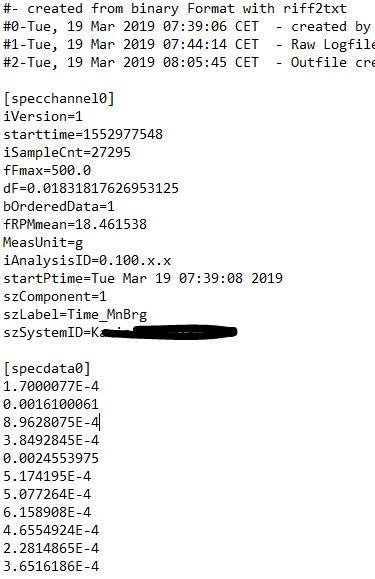
This is the simplest implementation, and will only work if there is one [specdata0] and one #--finish-- but can be changed if there are more in the file and one or all are needed
Your code definitely works,
but I do need data lines containing value of dF, fRPMmean and also szSystemID.
As I have formula to detrmine number of data to be used for analysis,
formula = (fRPMmean * 4) / dF ............................ this gives me number of data elements I need to consider.
I extended the code to generalize and create a list which contains all data in the format as you present it. It should work if the structure of your file is not deviating too much from your example
library(stringr)
library(readr)
myFile = readLines("test.txt")
myResult = list()
#Find the position of the variables that are between []
#We add the last line number as a position as well
vars = c(which(str_detect(myFile, "^\\[.*\\]\\s*$") == T), length(myFile))
#Get the content for each variable
for(i in 1:(length(vars)-1)){
myData = myFile[vars[i]:(vars[i +1] - 1)]
#Remove lines that are comments or blank
myData = myData[!str_detect(myData, "^\\s*#|^\\s*$")]
#If the content is a list of variables, create them as a list
if(str_detect(myData[2], "=")){
content = str_split(myData[-1], "=")
result = lapply(lapply(content, "[", 2), parse_guess)
names(result) = sapply(content, "[", 1)
} else {
#If the content just a vector of data, extract it
result = parse_guess(myData[-1])
}
#Create the variable as a list item and assign the content
myResult[[str_remove_all(myData[1], "\\[|\\]")]] = result
}
This code generates a list in which every variable between square brackets is a sublist and the content of each sublist is either a list of variables or a vector of data.
Thanks for your code, it creates the sub-lists. But I need to create some kind of loop which extracts the value of dF, fRPMmean for calculating number of data values (which is mainly data values between [specdata0] and ##--finish--) to be considered for analysis. The value of dF and fRPMmean occur just once in this file.
Formula to calulate number of data va;ues to be considered for analysis = (fRPMmean *4)/dF.
I don't know what you need extra here, because my result exactly gives you that...
If you need the value for dF, you access it by result$specchannel10$dF same for fRPMean which is result$specchannel10$fRPMean so in your formula that would be:
Now i wanted to use split function to split the data into 3 parts of 1000 each and remaining data outside 3 group will be in 4th group. This grouping should take place without sorting of data.
But how can I use split function ? or any other function can be used.
We suggest you open a new topic if your initial question has been answered and you have a new one given the title only refers to the first question and things can become messy afterwards.
Since this question is relatively easy and was recently posted by another member on this forum, I'll just forward the topic link: