Here when we use "sort" command dose it rearrange the data and than split them into 3 sets ?
I mean sorting in ascending or descending. Because I don't want data to be sorted before splitting.
No the sort is before we assign the column. It just ensures that we have first 9000 1, then 9000 2, ... as the rep function generates a list of 1,2,3,1,2,3,1,2,3,... so I sort it into first all 1 then 2 then 3
You probably don't need it, but since I was thinking that the previous method would only work if indeed the data could be evenly split into the exact number of groups, I created a little function that lets you assign groups to data, even if you can't split it perfectly
In the example, if you like to split 18 rows in 4 groups, the best way is in two groups of 5 rows and 2 of 4. If the split can be done perfectly, it does of course.
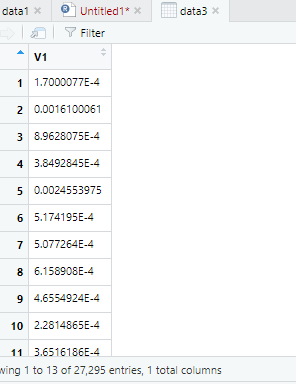
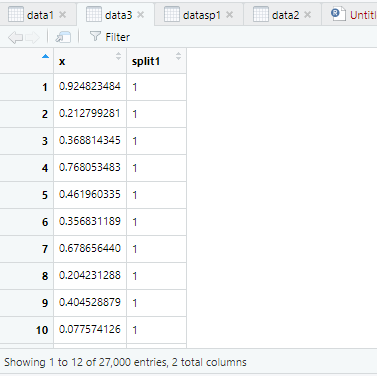
I followed the code which you suggested definitely it works, but I see that my initial data and data values after dividing them into 3 sets aren't same. Please check my previous picture and present picture after dividing them into 3.
I thought of using them as well, but the split function requires a factor to split on, and in this case there is none, only a list of values to split. Unless I'm missing something here then please correct me
Oh I get it now! Indeed it's much better to split the data-frame with a function. I was just focusing on the column with the split indices. Also, I did not know the rep's 'each' argument!
Anyway I think @Shri1506 got enough code now to solve the issue