How to extract validation- and training error from tune:tune_grid() in R using glmnet?
I read this but still cant get it, I know it is an optimistic estimate involved:
How to extract validation- and training error from tune:tune_grid() in R using glmnet?
I read this but still cant get it, I know it is an optimistic estimate involved:
From the documentations, seems not clear which prediction-types are meant (train/test):
collect_predictions() can summarize the various results over replicate out-of-sample predictions. For example, when using the bootstrap, each row in the original training set has multiple holdout predictions (across assessment sets). To convert these results to a format where every training set same has a single predicted value, the results are averaged over replicate predictions.
For regression cases, the numeric predictions are simply averaged.
Try to compare different approaches:
model_spec <-parsnip::linear_reg(
penalty =tune::tune()
,mixture=1
) %>% parsnip::set_engine("glmnet") %>% parsnip::set_mode("regression")
model_wfl <-workflows::workflow() %>%
workflows::add_model(model_spec) %>%
workflows::add_recipe(model_rec)
trainPreds <-tune::collect_extracts(trainRes)
trainPreds <-trainPreds %>% tidyr::unnest(cols=.extracts)
testPreds <-trainRes$.metrics
testPreds1 <-do.call(data.table::rbindlist,list(testPreds,fill=TRUE,idcol=FALSE))
testPreds2 <-tune::collect_predictions(trainRes,summarize=TRUE)
On 5 Folds:
trainPreds= 4365 rows per config
testPreds1= 5 rows per .config (out-of-sample, means?)
testPreds2= 895 rows per .config (out-of-sample, means?)
What is what?
"[...] Comparing performance metrics for configurations averaged with different resamples is likely to lead to inappropriate results. [...]"
And now?
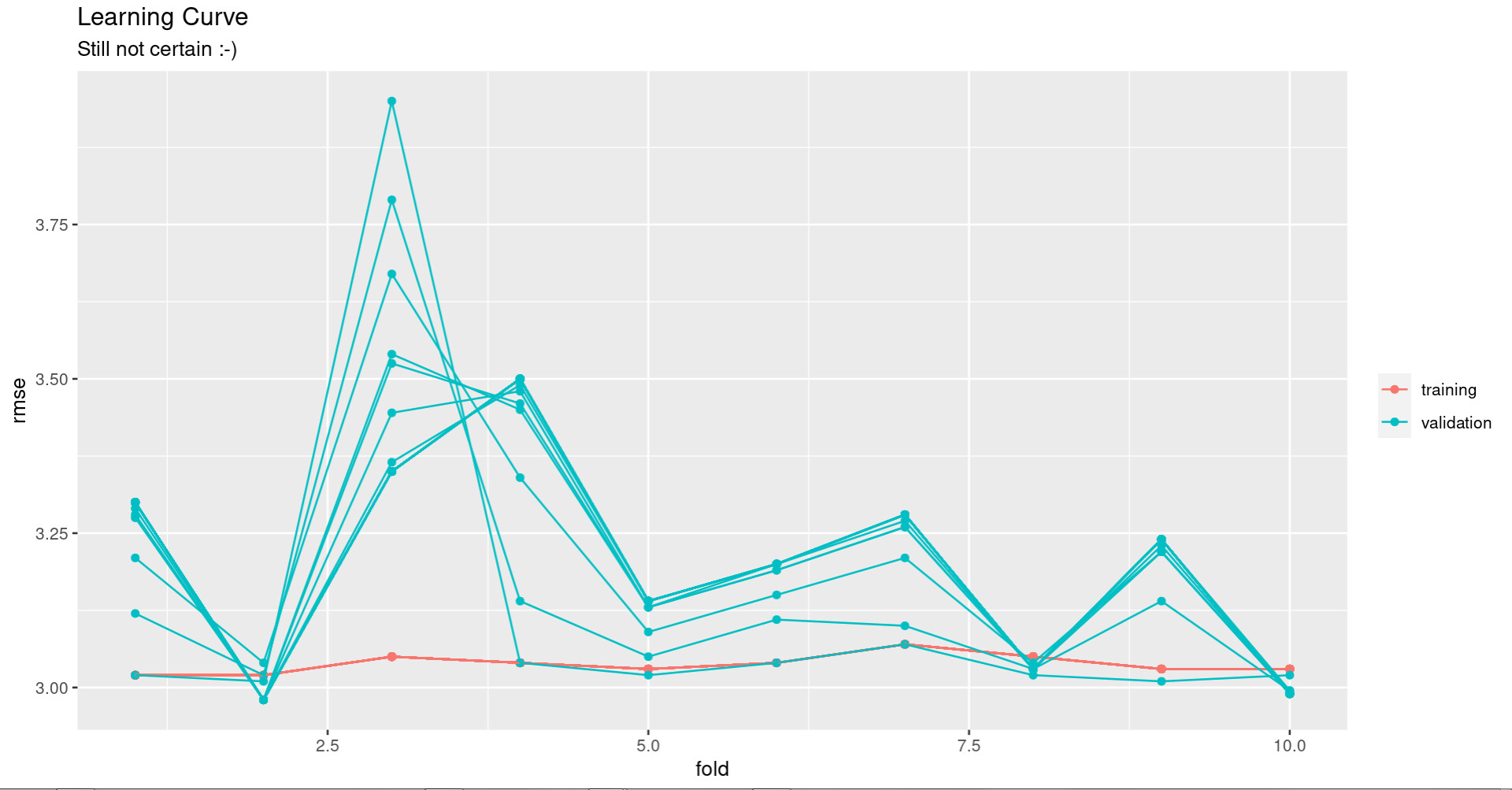
Too bad there are no ready to use functions/tags to produce learning curves, because of "pedagogical reasons". ;-). Learning curves are essential to detect over/underfitting.
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.
If you have a query related to it or one of the replies, start a new topic and refer back with a link.