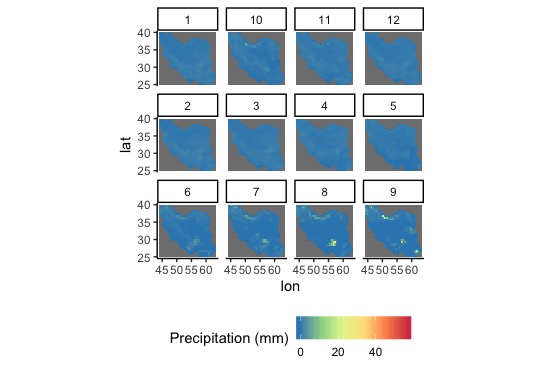
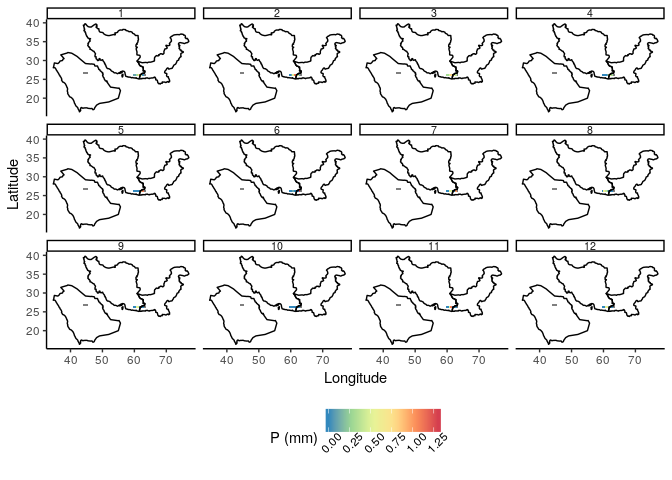
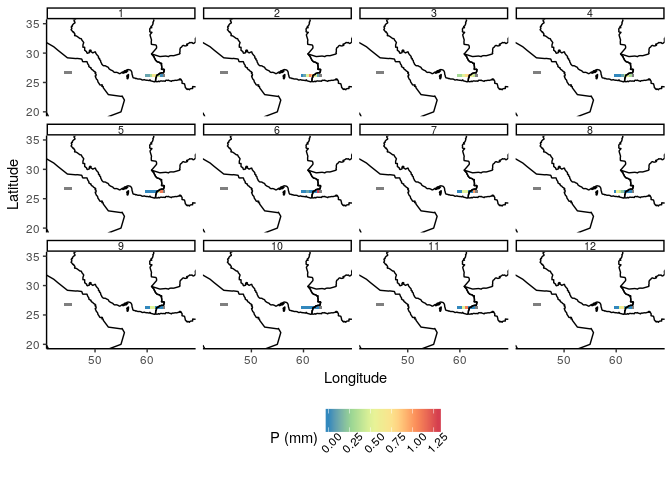
Here are the datasets for the 12 months.
df1 = data.frame( lon= c(59.75, 60.25, 60.75, 61.25, 61.75, 62.25 ,62.75, 63.25, 44.25, 44.75, 45.25),
lat = c(26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.75, 26.75, 26.75),
P = c(0.1, 0.1, 0.3, 0.7, 0.6, 0.4, 0.02, NA, NA, NA, NA) )
df2 = data.frame( lon= c(59.75, 60.25, 60.75, 61.25, 61.75, 62.25 ,62.75, 63.25, 44.25, 44.75, 45.25),
lat = c(26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.75, 26.75, 26.75),
P= c(0, 0.1, 0.5, 1.1, 0.9, 0.5, 0.1, NA, NA, NA, NA) )
df3= data.frame( lon= c(59.75, 60.25, 60.75, 61.25, 61.75, 62.25 ,62.75, 63.25, 44.25, 44.75, 45.25),
lat = c(26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.75, 26.75, 26.75),
P= c(0.3, 0.3, 0.5, 0.8, 0.9, 0.6, 0.4, NA, NA, NA, NA))
df4= data.frame( lon =c(59.75, 60.25, 60.75, 61.25, 61.75, 62.25 ,62.75, 63.25, 44.25, 44.75, 45.25),
lat= c(26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.75, 26.75, 26.75),
P= c(0, 0, 0, 0.1, 0.4, 0.6, 0.3, NA, NA, NA, NA))
df5= data.frame( lon =c(59.75, 60.25, 60.75, 61.25, 61.75, 62.25 ,62.75, 63.25, 44.25, 44.75, 45.25),
lat= c(26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.75, 26.75, 26.75),
P= c(0, 0, 0, 0, 0, 0.7, 1.1, NA, NA, NA, NA))
df6 = data.frame( lon =c(59.75, 60.25, 60.75, 61.25, 61.75, 62.25 ,62.75, 63.25, 44.25, 44.75, 45.25),
lat= c(26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.75, 26.75, 26.75),
P= c(0, 0, 0.1, 0, 0, 0, 1.3, NA, NA, NA, NA))
df7= data.frame( lon =c(59.75, 60.25, 60.75, 61.25, 61.75, 62.25 ,62.75, 63.25, 44.25, 44.75, 45.25),
lat= c(26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.75, 26.75, 26.75),
P= c(0, 0, 0.5, 0.5, 0, 0, 1, NA, NA, NA, NA))
df8 = data.frame( lon =c(59.75, 60.25, 60.75, 61.25, 61.75, 62.25 ,62.75, 63.25, 44.25, 44.75, 45.25),
lat= c(26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.75, 26.75, 26.75),
P= c(0, 0.6, 0.4, 0.2, 0, 0, 0, NA, NA, NA, NA))
df9= data.frame( lon =c(59.75, 60.25, 60.75, 61.25, 61.75, 62.25 ,62.75, 63.25, 44.25, 44.75, 45.25),
lat= c(26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.75, 26.75, 26.75),
P= c(0, 0, 0.5, 0.5, 0, 0, 0, NA, NA, NA, NA))
df10 = data.frame( lon =c(59.75, 60.25, 60.75, 61.25, 61.75, 62.25 ,62.75, 63.25, 44.25, 44.75, 45.25),
lat= c(26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.75, 26.75, 26.75),
P= c(0, 0, 0, 0, 0, 0, 0, NA, NA, NA, NA))
df11 = data.frame( lon =c(59.75, 60.25, 60.75, 61.25, 61.75, 62.25 ,62.75, 63.25, 44.25, 44.75, 45.25),
lat= c(26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.75, 26.75, 26.75),
P= c(0, 0, 0.5, 1.1, 0, 0, 0, NA, NA, NA, NA))
df12= data.frame( lon =c(59.75, 60.25, 60.75, 61.25, 61.75, 62.25 ,62.75, 63.25, 44.25, 44.75, 45.25),
lat= c(26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.25, 26.75, 26.75, 26.75),
P= c(0, 0, 0.5, 0.7, 0.1, 0.1, 0, NA, NA, NA, NA))
In the resulting figure that I pasted above, the 'Month' ID appears in the order:
row 1: 1, 10, 11, 12
row 2: 2, 3, 4, 5
row 3: 6, 7, 8, 9
The second question is how to decrease the size of the boxes that have the number: 1, 10, 11, 12, 2, 3, 4, 5, etc? and then enlarge the ggplot size? Thanks to anyone who can help.