Thank you so much!
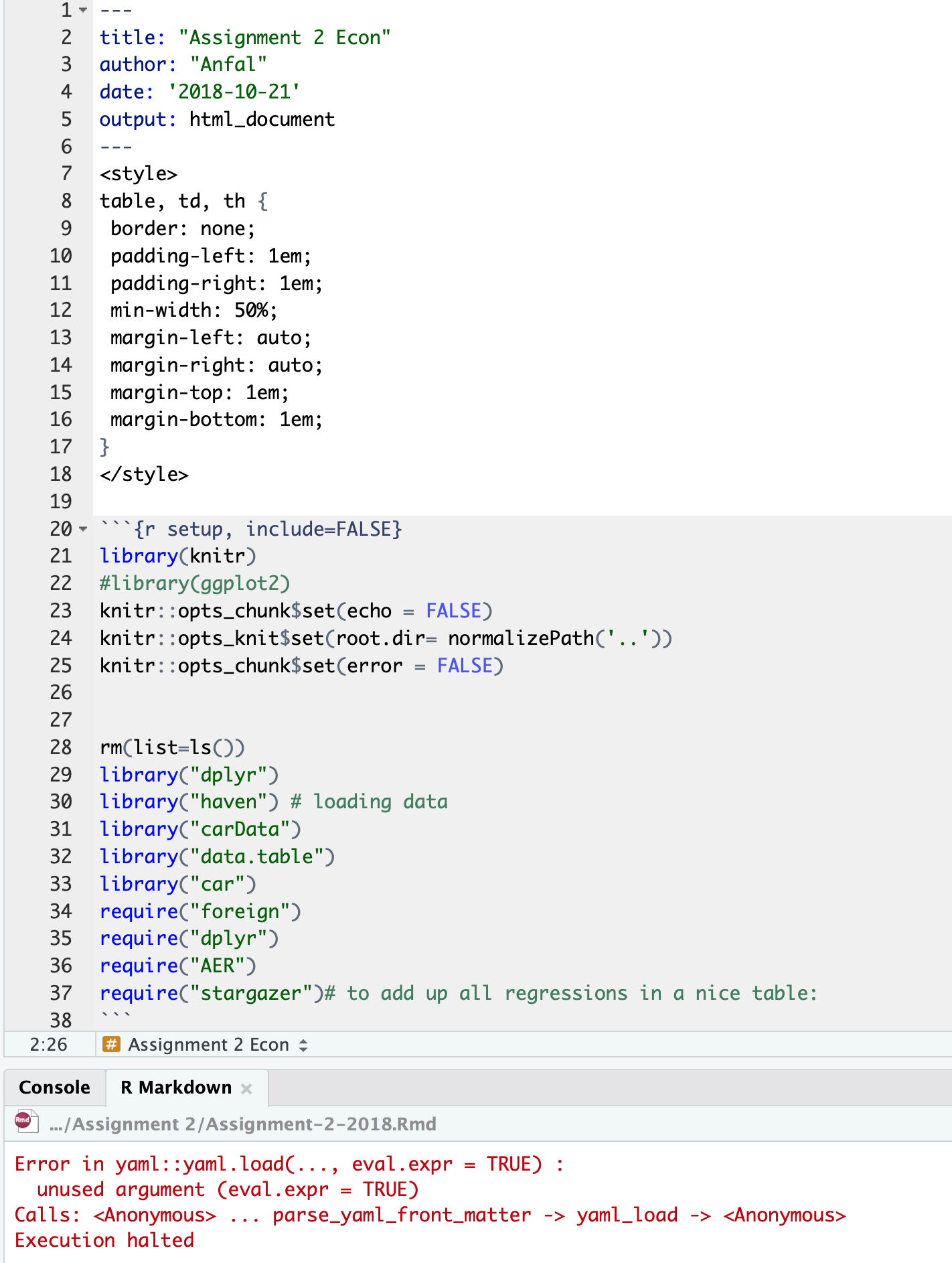
---
title: "Assignment 2 Econ"
author: "Anfal "
date: '2018-10-21'
output: html_document
---
<style>
table, td, th {
border: none;
padding-left: 1em;
padding-right: 1em;
min-width: 50%;
margin-left: auto;
margin-right: auto;
margin-top: 1em;
margin-bottom: 1em;
}
</style>
```{r setup, include=FALSE}
rm(list=ls())
knitr::opts_chunk$set(echo = TRUE)
library("dplyr")
library("haven") # loading data
library("carData")
library("data.table")
library("car")
require("foreign")
require("dplyr")
require("AER")
require("stargazer")# to add up all regressions in a nice table:
```
## Outline
This assignment requires you to read the following notes. The first two notes are just for your general knowledge. The last one contains a paper, and the assignment requires you to replicate the main findings of this paper.
1. [Note 1](http://econ.lse.ac.uk/staff/spischke/ec524/evaluation1_07.pdf) - Evaluation and Randomization
2. [Note 2](http://econ.lse.ac.uk/staff/spischke/ec524/evaluation2_07.pdf) - Evaluation and Regression
3. [paper](https://www150.statcan.gc.ca/n1/en/pub/11f0019m/11f0019m1998126-eng.pdf?st=IIGv0ZAG) - Do computers make workers more productive.
## Details
In order to replicate the results from the paper, you need to go to the york data library and download the data set called "General Social Survey, Cycle 9, 1994 [Canada]: Education, Work and Retirement" from ODESI. [Start here](http://researchguides.library.yorku.ca/c.php?g=679400&p=4789750).
You can download the data in any format you want. I normally download the data in STATA format, and use the "haven" package to load it into R. The paper contains an appendix with the details of their data construction. To get you started, I providd some code below to calculate hourly wages. The rest is up to you.
The Main table to replicate is Table 4.
Once you replicate the table, you will:
1. Submit your table and code via an html document produced in R markdown.
2. Provide a very brief write-up of your results in the context of the language used in Note 2, linked above. In particular, pay close attention to the section on "falsification." Can you relate this discussion to the output in the table?
## Due date
November 20th
## General social survey, 1994 - Canada- Replication of Table 4:
```{r, include=FALSE}
df <- read_dta("/Users/anfal/Dropbox/PhD/fall 2018/Econ 7100/Assignments/Assignment 2/gss-12M0009-E-1994-c-9/gss-12M0009-E-1994-c-9_F1.dta")
# DVPERCAP is emplyment income
# DVAGEGR is Age of respondent and we are choosing ages 15-64 which corresponds to groups 1 to 11
# G10 is Worked at a job last week and the value 1 means yes
# DVINDB is respondents who are students at time of survey and we want that to be a no which equals 2
# H2 is numbers of hours worked per week(unique job)
# H4 is numbers of hours worked per week (job with most hours)
# G9 is number of weeks worked(all jobs ) last 12 months
# DVPERNEW is wage or salery schedule for value in DVPERINC (Employment income in $)
# DVSEX is Sex of respondent, 2 means female and 1 means male
# hours = weekly hours worked
# Weeks = numbers of weeks worked per year
# female = dummy female
# hourly.wage
df <- df %>%
filter(DVPERCAP %in% 1:10000000 & between(DVAGEGR, 1 , 11) & G10==1 & DVINDB == 2) %>% # sample
mutate(hours = ifelse(!is.na(H2),H2,
ifelse(!is.na(H4),H4,
NA)), # weekly hours
weeks = G9, # weeks per year
hourly.wage = ifelse(DVPERNEW == 1, DVPERCAP/100, # hourly wages
ifelse(DVPERNEW == 2, DVPERCAP/100/hours/5, # daily wages
ifelse(DVPERNEW == 3, DVPERCAP/100/hours, # weekly
ifelse(DVPERNEW %in% 4:5, DVPERCAP/100/(hours*2), # twice per month
ifelse(DVPERNEW == 6, DVPERCAP/100/(hours*4) , # monthly
ifelse(DVPERNEW == 7, DVPERCAP/100/(hours*weeks), # annual
NA)))))),
female = ifelse(DVSEX==2,1,0)) # female dummy
# Create any other variables you deem necessary, and use the "select" command to reduce
# the dimension of the data.
# our y = ln(hourly.wage)
# df.f = creating a new data set with female only
# df.m = creating a new data set with male only
df.f <- filter(df, DVSEX==2)
df.m <- filter(df,DVSEX==1)
# DVH20 = number of years spend performing the same functions
# DVA19 = highest degree, diplima or certificate completed, we can do a postgrad = above bacholar = catagory 1-4 ,
# we can create uni = bacholar and university = catagory 5-6,
# we can create a coll= diploma and collage = catagory 7-8,
# we can creat a high_sch= high school = catagory 9
# we can creat a lhigh_sch= less than high school = catagory 10
# creaating dummy variables for schooling in both female and male data sets
head(df.f$DVA19, n=50)
df.f$d_postgrad<-as.numeric((df.f$DVA19<5))
head(df.f$d_postgrad, n=50)
head(df.m$DVA19, n=15)
df.m$d_postgrad<-as.numeric((df.m$DVA19<5))
head(df.m$d_postgrad, n=15)
head(df.f$DVA19, n=10)
df.f$d_uni<-as.numeric((df.f$DVA19==5 | df.f$DVA19==6))
head(df.f$d_uni, n=10)
head(df.m$DVA19, n=30)
df.m$d_uni<-as.numeric((df.m$DVA19==5 | df.m$DVA19==6))
head(df.m$d_uni, n=30)
head(df.f$DVA19, n=10)
df.f$d_coll<-as.numeric((df.f$DVA19==7 | df.f$DVA19==8))
head(df.f$d_coll, n=10)
head(df.m$DVA19, n=10)
df.m$d_coll<-as.numeric((df.m$DVA19==7 | df.m$DVA19==8))
head(df.m$d_coll, n=10)
df.f$d_high_sch<-as.numeric((df.f$DVA19==9))
df.f$d_lhigh_sch<-as.numeric((df.f$DVA19==10))
df.m$d_high_sch<-as.numeric((df.m$DVA19==9))
df.m$d_lhigh_sch<-as.numeric((df.m$DVA19==10))
# we decided to use d_high_sch as our dummy 1 varaible for education
# created d_prt_job = a dummy varaible for part time jobs were it takes the value 1 if the person was employed part time, we didn't use the variable K4 because it has a lot of NA responses, the variable K4 is Work mostly full-time or part-time
head(df.f$C18)
df.f$d_prt_job<-as.numeric((df.f$C18==2))
head(df.f$d_prt_job)
head(df.m$C18, n=15)
df.m$d_prt_job<-as.numeric((df.m$C18==2))
head(df.m$d_prt_job, n=15)
# H42A = Union member at work- currebt job
# prov_NL = dummy varaible that takes the value of 1 if it is Newfoundland
head(df.f$DVPROV, n=10)
df.f$prov_NL = as.numeric(df.f$DVPROV==10)
head(df.f$prov_NL, n=10)
# prov_NL = dummy varaible that takes the value of 1 if it is Newfoundland
head(df.m$DVPROV, n=10)
df.m$prov_NL = as.numeric(df.m$DVPROV==10)
head(df.m$prov_NL, n=10)
# dummy varaible that takes the value of 1 if it is Prince Edward Island
df.f$prov_PE = as.numeric(df.f$DVPROV==11)
df.f$prov_NS = as.numeric(df.f$DVPROV==12)
df.f$prov_NB = as.numeric(df.f$DVPROV==13)
df.f$prov_QC = as.numeric(df.f$DVPROV==24)
df.f$prov_ON = as.numeric(df.f$DVPROV==35)
df.f$prov_MB = as.numeric(df.f$DVPROV==46)
df.f$prov_SK = as.numeric(df.f$DVPROV==47)
df.f$prov_AB = as.numeric(df.f$DVPROV==48)
df.f$prov_BC = as.numeric(df.f$DVPROV==59)
# in our regression we choose ontario to be our dummy varaible
# dummy varaible that takes the value of 1 if it is Prince Edward Island
df.m$prov_PE = as.numeric(df.m$DVPROV==11)
df.m$prov_NS = as.numeric(df.m$DVPROV==12)
df.m$prov_NB = as.numeric(df.m$DVPROV==13)
df.m$prov_QC = as.numeric(df.m$DVPROV==24)
df.m$prov_ON = as.numeric(df.m$DVPROV==35)
df.m$prov_MB = as.numeric(df.m$DVPROV==46)
df.m$prov_SK = as.numeric(df.m$DVPROV==47)
df.m$prov_AB = as.numeric(df.m$DVPROV==48)
df.m$prov_BC = as.numeric(df.m$DVPROV==59)
# ind_1 = dummy varaible that takes the value 1 if the industry is TRADITIONAL PRIMARY SECTOR otherwise it takes the value 0
# ind_2 = dummy varaible that takes the value 1 if the industry is NON-TRADITIONAL PRIMARY SECTOR otherwise it takes the value 0
df.f$ind_1 = as.numeric(df.f$DVH12SIC==1)
df.f$ind_2 = as.numeric(df.f$DVH12SIC==2)
df.f$ind_3 = as.numeric(df.f$DVH12SIC==3)
df.f$ind_4 = as.numeric(df.f$DVH12SIC==4)
df.f$ind_5 = as.numeric(df.f$DVH12SIC==5)
df.f$ind_6 = as.numeric(df.f$DVH12SIC==6)
df.f$ind_7 = as.numeric(df.f$DVH12SIC==7)
df.f$ind_8 = as.numeric(df.f$DVH12SIC==8)
df.f$ind_9 = as.numeric(df.f$DVH12SIC==9)
df.f$ind_10 = as.numeric(df.f$DVH12SIC==10)
df.f$ind_11 = as.numeric(df.f$DVH12SIC==11)
df.f$ind_12 = as.numeric(df.f$DVH12SIC==12) # CONSUMER SERVICES:RETAIL TRADE
df.f$ind_13 = as.numeric(df.f$DVH12SIC==13)
df.f$ind_14 = as.numeric(df.f$DVH12SIC==14)
df.f$ind_15 = as.numeric(df.f$DVH12SIC==15)
df.f$ind_16 = as.numeric(df.f$DVH12SIC==16)
df.f$ind_17 = as.numeric(df.f$DVH12SIC==17)
df.f$ind_18 = as.numeric(df.f$DVH12SIC==18)
# we choose ind_12 to be our dummy varaible in the regression below
df.m$ind_1 = as.numeric(df.m$DVH12SIC==1)
df.m$ind_2 = as.numeric(df.m$DVH12SIC==2)
df.m$ind_3 = as.numeric(df.m$DVH12SIC==3)
df.m$ind_4 = as.numeric(df.m$DVH12SIC==4)
df.m$ind_5 = as.numeric(df.m$DVH12SIC==5)
df.m$ind_6 = as.numeric(df.m$DVH12SIC==6)
df.m$ind_7 = as.numeric(df.m$DVH12SIC==7)
df.m$ind_8 = as.numeric(df.m$DVH12SIC==8)
df.m$ind_9 = as.numeric(df.m$DVH12SIC==9)
df.m$ind_10 = as.numeric(df.m$DVH12SIC==10)
df.m$ind_11 = as.numeric(df.m$DVH12SIC==11)
df.m$ind_12 = as.numeric(df.m$DVH12SIC==12) # CONSUMER SERVICES:RETAIL TRADE
df.m$ind_13 = as.numeric(df.m$DVH12SIC==13)
df.m$ind_14 = as.numeric(df.m$DVH12SIC==14)
df.m$ind_15 = as.numeric(df.m$DVH12SIC==15)
df.m$ind_16 = as.numeric(df.m$DVH12SIC==16)
df.m$ind_17 = as.numeric(df.m$DVH12SIC==17)
df.m$ind_18 = as.numeric(df.m$DVH12SIC==18)
# creating dummy variables for firm size
head(df.f$DVH31H41)
df.f$firm_s = as.numeric(df.f$DVH31H41==1)
df.f$firm_m = as.numeric(df.f$DVH31H41> 1&df.f$DVH31H41<6)
df.f$firm_l = as.numeric(df.f$DVH31H41==6)
head(df.m$DVH31H41)
df.m$firm_s = as.numeric(df.m$DVH31H41==1)
df.m$firm_m = as.numeric(df.m$DVH31H41> 1&df.m$DVH31H41<6)
df.m$firm_l = as.numeric(df.m$DVH31H41==6)
# in the data set we choose firm_s to be our dummy variable
# H46 = Use computer 1== yes
df.f$cmpt = as.numeric(df.f$H46==1)
df.m$cmpt = as.numeric(df.m$H46==1)
# Quesions on fax machiene:
# N7B = Use of fax machines in past 12 months 1,2,3 yes they used it 4 means no
df.f$fax = as.numeric(df.f$N7B<4)
df.m$fax = as.numeric(df.m$N7B<4)
# occ_1 = dummy varaible that takes the value 1 if the occupation is MANAGERS/ADMINISTRATORS otherwise it takes the value 0
# occ_2 = dummy varaible that takes the value 1 if the occupation is MANAGEMENT/ADMIN. RELATED otherwise it takes the value 0
df.f$occ_1 = as.numeric(df.f$DVH13SOC==1)
df.f$occ_2 = as.numeric(df.f$DVH13SOC==2)
df.f$occ_3 = as.numeric(df.f$DVH13SOC==3)
df.f$occ_4 = as.numeric(df.f$DVH13SOC==4)
df.f$occ_5 = as.numeric(df.f$DVH13SOC==5)
df.f$occ_6 = as.numeric(df.f$DVH13SOC==6)
df.f$occ_7 = as.numeric(df.f$DVH13SOC==7)
df.f$occ_8 = as.numeric(df.f$DVH13SOC==8)
df.f$occ_9 = as.numeric(df.f$DVH13SOC==9)
df.f$occ_10 = as.numeric(df.f$DVH13SOC==10)
df.f$occ_11 = as.numeric(df.f$DVH13SOC==11)
df.f$occ_12 = as.numeric(df.f$DVH13SOC==12)
df.f$occ_13 = as.numeric(df.f$DVH13SOC==13)
df.f$occ_14 = as.numeric(df.f$DVH13SOC==14)
df.f$occ_15 = as.numeric(df.f$DVH13SOC==15)
df.f$occ_16 = as.numeric(df.f$DVH13SOC==16)
df.f$occ_17 = as.numeric(df.f$DVH13SOC==17)
df.f$occ_18 = as.numeric(df.f$DVH13SOC==18)
df.f$occ_19 = as.numeric(df.f$DVH13SOC==19)
df.f$occ_20 = as.numeric(df.f$DVH13SOC==20)
df.f$occ_21 = as.numeric(df.f$DVH13SOC==21)
df.f$occ_22 = as.numeric(df.f$DVH13SOC==22)
df.f$occ_23 = as.numeric(df.f$DVH13SOC==23)
df.f$occ_24 = as.numeric(df.f$DVH13SOC==24)
df.f$occ_25 = as.numeric(df.f$DVH13SOC==25)
df.f$occ_26 = as.numeric(df.f$DVH13SOC==26)
df.f$occ_27 = as.numeric(df.f$DVH13SOC==27)
df.f$occ_28 = as.numeric(df.f$DVH13SOC==28)
df.f$occ_29 = as.numeric(df.f$DVH13SOC==29)
df.f$occ_30 = as.numeric(df.f$DVH13SOC==30)
df.f$occ_31 = as.numeric(df.f$DVH13SOC==31)
df.f$occ_32 = as.numeric(df.f$DVH13SOC==32)
df.f$occ_33 = as.numeric(df.f$DVH13SOC==33)
df.m$occ_1 = as.numeric(df.m$DVH13SOC==1)
df.m$occ_2 = as.numeric(df.m$DVH13SOC==2)
df.m$occ_3 = as.numeric(df.m$DVH13SOC==3)
df.m$occ_4 = as.numeric(df.m$DVH13SOC==4)
df.m$occ_5 = as.numeric(df.m$DVH13SOC==5)
df.m$occ_6 = as.numeric(df.m$DVH13SOC==6)
df.m$occ_7 = as.numeric(df.m$DVH13SOC==7)
df.m$occ_8 = as.numeric(df.m$DVH13SOC==8)
df.m$occ_9 = as.numeric(df.m$DVH13SOC==9)
df.m$occ_10 = as.numeric(df.m$DVH13SOC==10)
df.m$occ_11 = as.numeric(df.m$DVH13SOC==11)
df.m$occ_12 = as.numeric(df.m$DVH13SOC==12)
df.m$occ_13 = as.numeric(df.m$DVH13SOC==13)
df.m$occ_14 = as.numeric(df.m$DVH13SOC==14)
df.m$occ_15 = as.numeric(df.m$DVH13SOC==15)
df.m$occ_16 = as.numeric(df.m$DVH13SOC==16)
df.m$occ_17 = as.numeric(df.m$DVH13SOC==17)
df.m$occ_18 = as.numeric(df.m$DVH13SOC==18)
df.m$occ_19 = as.numeric(df.m$DVH13SOC==19)
df.m$occ_20 = as.numeric(df.m$DVH13SOC==20)
df.m$occ_21 = as.numeric(df.m$DVH13SOC==21)
df.m$occ_22 = as.numeric(df.m$DVH13SOC==22)
df.m$occ_23 = as.numeric(df.m$DVH13SOC==23)
df.m$occ_24 = as.numeric(df.m$DVH13SOC==24)
df.m$occ_25 = as.numeric(df.m$DVH13SOC==25)
df.m$occ_26 = as.numeric(df.m$DVH13SOC==26)
df.m$occ_27 = as.numeric(df.m$DVH13SOC==27)
df.m$occ_28 = as.numeric(df.m$DVH13SOC==28)
df.m$occ_29 = as.numeric(df.m$DVH13SOC==29)
df.m$occ_30 = as.numeric(df.m$DVH13SOC==30)
df.m$occ_31 = as.numeric(df.m$DVH13SOC==31)
df.m$occ_32 = as.numeric(df.m$DVH13SOC==32)
df.m$occ_33 = as.numeric(df.m$DVH13SOC==33)
# we choose occ_1 to be our dummy variable
# creating a data set (mydata) with variables I need:
mydata.f<-df.f[,c( 'DVAGEGR','DVH20','d_postgrad', 'd_uni', 'd_coll', 'd_high_sch', 'd_lhigh_sch', 'H42A',
'd_prt_job', 'prov_NL', 'prov_PE', 'prov_NS', 'prov_NB', 'prov_QC', 'prov_ON', 'prov_MB', 'prov_SK', 'prov_AB', 'prov_BC', 'ind_1', 'ind_2', 'ind_3', 'ind_4', 'ind_5', 'ind_6', 'ind_7', 'ind_8', 'ind_9', 'ind_10', 'ind_11', 'ind_12', 'ind_13', 'ind_14', 'ind_15', 'ind_16', 'ind_17', 'ind_18', 'firm_s', 'firm_m', 'firm_l', 'occ_1','occ_2' ,'occ_3' ,'occ_4' ,'occ_5','occ_6' ,'occ_7','occ_8' ,'occ_9' ,'occ_10','occ_11','occ_12' ,'occ_13' ,'occ_14','occ_15','occ_16','occ_17','occ_18' ,'occ_19','occ_20','occ_21' ,'occ_22' ,'occ_23' ,'occ_24' ,'occ_25','occ_26' ,'occ_27' ,'occ_28' ,'occ_29' ,'occ_30' ,'occ_31' ,'occ_32' ,'occ_33', 'cmpt', 'fax', 'hourly.wage' )]
mydata.m<-df.m[,c( 'DVAGEGR','DVH20','d_postgrad', 'd_uni', 'd_coll', 'd_high_sch', 'd_lhigh_sch', 'H42A',
'd_prt_job', 'prov_NL', 'prov_PE', 'prov_NS', 'prov_NB', 'prov_QC', 'prov_ON', 'prov_MB', 'prov_SK', 'prov_AB', 'prov_BC', 'ind_1', 'ind_2', 'ind_3', 'ind_4', 'ind_5', 'ind_6', 'ind_7', 'ind_8', 'ind_9', 'ind_10', 'ind_11', 'ind_12', 'ind_13', 'ind_14', 'ind_15', 'ind_16', 'ind_17', 'ind_18', 'firm_s', 'firm_m', 'firm_l', 'occ_1','occ_2' ,'occ_3' ,'occ_4' ,'occ_5','occ_6' ,'occ_7','occ_8' ,'occ_9' ,'occ_10','occ_11','occ_12' ,'occ_13' ,'occ_14','occ_15','occ_16','occ_17','occ_18' ,'occ_19','occ_20','occ_21' ,'occ_22' ,'occ_23' ,'occ_24' ,'occ_25','occ_26' ,'occ_27' ,'occ_28' ,'occ_29' ,'occ_30' ,'occ_31' ,'occ_32' ,'occ_33', 'cmpt', 'fax', 'hourly.wage' )]
# creating OLS for men with no computer
mydata.f$ln.hourly.wage = log(mydata.f$hourly.wage)
mydata.m$ln.hourly.wage = log(mydata.m$hourly.wage)
```
```{r,include=FALSE, results="asis"}
m_n_cmpt <- lm(ln.hourly.wage ~ cmpt + DVAGEGR + (DVAGEGR)^2 + DVH20 + (DVH20 )^2 + d_postgrad + d_uni +d_coll+d_lhigh_sch +H42A + d_prt_job + prov_NL + prov_PE + prov_NS + prov_NB+ prov_QC + prov_MB + prov_SK + prov_AB +prov_BC + ind_1 + ind_2 + ind_3 + ind_4 + ind_5 + ind_6 + ind_7 + ind_8 + ind_9 + ind_10+ ind_11 + ind_13 + ind_14 + ind_15 + ind_16 + ind_17 + ind_18 + firm_m + firm_l, data = mydata.m)
m_y_cmpt <- lm(ln.hourly.wage ~ cmpt + DVAGEGR + (DVAGEGR)^2 + DVH20 + (DVH20 )^2 + d_postgrad + d_uni +d_coll+d_lhigh_sch +H42A + d_prt_job + prov_NL + prov_PE + prov_NS + prov_NB+ prov_QC + prov_MB + prov_SK + prov_AB +prov_BC + ind_1 + ind_2 + ind_3 + ind_4 + ind_5 + ind_6 + ind_7 + ind_8 + ind_9 + ind_10+ ind_11 + ind_13 + ind_14 + ind_15 + ind_16 + ind_17 + ind_18 + firm_m + firm_l+ occ_2 + occ_3 + occ_4 +occ_5+occ_6 +occ_7 +occ_8 + occ_9 + occ_10 +occ_11+ occ_12 + occ_13 + occ_14 +occ_15+ occ_16 +occ_17 +occ_18 + occ_19+ occ_20 +occ_21 +occ_22 + occ_23 + occ_24 +occ_25+occ_26 +occ_27 +occ_28 + occ_29 + occ_30 + occ_31 + occ_32 + occ_33, data = mydata.m)
f_n_cmpt <- lm(ln.hourly.wage ~ cmpt + DVAGEGR + (DVAGEGR)^2 + DVH20 + (DVH20 )^2 + d_postgrad + d_uni +d_coll+d_lhigh_sch +H42A + d_prt_job + prov_NL + prov_PE + prov_NS + prov_NB+ prov_QC + prov_MB + prov_SK + prov_AB +prov_BC + ind_1 + ind_2 + ind_3 + ind_4 + ind_5 + ind_6 + ind_7 + ind_8 + ind_9 + ind_10+ ind_11 + ind_13 + ind_14 + ind_15 + ind_16 + ind_17 + ind_18 + firm_m + firm_l, data = mydata.f)
f_y_cmpt <- lm(ln.hourly.wage ~ cmpt + DVAGEGR + (DVAGEGR)^2 + DVH20 + (DVH20 )^2 + d_postgrad + d_uni +d_coll+d_lhigh_sch +H42A + d_prt_job + prov_NL + prov_PE + prov_NS + prov_NB+ prov_QC + prov_MB + prov_SK + prov_AB +prov_BC + ind_1 + ind_2 + ind_3 + ind_4 + ind_5 + ind_6 + ind_7 + ind_8 + ind_9 + ind_10+ ind_11 + ind_13 + ind_14 + ind_15 + ind_16 + ind_17 + ind_18 + firm_m + firm_l+ occ_2 + occ_3 + occ_4 +occ_5+occ_6 +occ_7 +occ_8 + occ_9 + occ_10 +occ_11+ occ_12 + occ_13 + occ_14 +occ_15+ occ_16 +occ_17 +occ_18 + occ_19+ occ_20 +occ_21 +occ_22 + occ_23 + occ_24 +occ_25+occ_26 +occ_27 +occ_28 + occ_29 + occ_30 + occ_31 + occ_32 + occ_33, data = mydata.f)
m_n_fax <- lm(ln.hourly.wage ~ fax + DVAGEGR + (DVAGEGR)^2 + DVH20 + (DVH20 )^2 + d_postgrad + d_uni +d_coll+d_lhigh_sch +H42A + d_prt_job + prov_NL + prov_PE + prov_NS + prov_NB+ prov_QC + prov_MB + prov_SK + prov_AB +prov_BC + ind_1 + ind_2 + ind_3 + ind_4 + ind_5 + ind_6 + ind_7 + ind_8 + ind_9 + ind_10+ ind_11 + ind_13 + ind_14 + ind_15 + ind_16 + ind_17 + ind_18 + firm_m + firm_l, data = mydata.m)
m_y_fax <- lm(ln.hourly.wage ~ fax + DVAGEGR + (DVAGEGR)^2 + DVH20 + (DVH20 )^2 + d_postgrad + d_uni +d_coll+d_lhigh_sch +H42A + d_prt_job + prov_NL + prov_PE + prov_NS + prov_NB+ prov_QC + prov_MB + prov_SK + prov_AB +prov_BC + ind_1 + ind_2 + ind_3 + ind_4 + ind_5 + ind_6 + ind_7 + ind_8 + ind_9 + ind_10+ ind_11 + ind_13 + ind_14 + ind_15 + ind_16 + ind_17 + ind_18 + firm_m + firm_l+ occ_2 + occ_3 + occ_4 +occ_5+occ_6 +occ_7 +occ_8 + occ_9 + occ_10 +occ_11+ occ_12 + occ_13 + occ_14 +occ_15+ occ_16 +occ_17 +occ_18 + occ_19+ occ_20 +occ_21 +occ_22 + occ_23 + occ_24 +occ_25+occ_26 +occ_27 +occ_28 + occ_29 + occ_30 + occ_31 + occ_32 + occ_33, data = mydata.m)
f_n_fax <- lm(ln.hourly.wage ~ fax + DVAGEGR + (DVAGEGR)^2 + DVH20 + (DVH20 )^2 + d_postgrad + d_uni +d_coll+d_lhigh_sch +H42A + d_prt_job + prov_NL + prov_PE + prov_NS + prov_NB+ prov_QC + prov_MB + prov_SK + prov_AB +prov_BC + ind_1 + ind_2 + ind_3 + ind_4 + ind_5 + ind_6 + ind_7 + ind_8 + ind_9 + ind_10+ ind_11 + ind_13 + ind_14 + ind_15 + ind_16 + ind_17 + ind_18 + firm_m + firm_l, data = mydata.f)
f_y_fax <- lm(ln.hourly.wage ~ fax + DVAGEGR + (DVAGEGR)^2 + DVH20 + (DVH20 )^2 + d_postgrad + d_uni +d_coll+d_lhigh_sch +H42A + d_prt_job + prov_NL + prov_PE + prov_NS + prov_NB+ prov_QC + prov_MB + prov_SK + prov_AB +prov_BC + ind_1 + ind_2 + ind_3 + ind_4 + ind_5 + ind_6 + ind_7 + ind_8 + ind_9 + ind_10+ ind_11 + ind_13 + ind_14 + ind_15 + ind_16 + ind_17 + ind_18 + firm_m + firm_l+ occ_2 + occ_3 + occ_4 +occ_5+occ_6 +occ_7 +occ_8 + occ_9 + occ_10 +occ_11+ occ_12 + occ_13 + occ_14 +occ_15+ occ_16 +occ_17 +occ_18 + occ_19+ occ_20 +occ_21 +occ_22 + occ_23 + occ_24 +occ_25+occ_26 +occ_27 +occ_28 + occ_29 + occ_30 + occ_31 + occ_32 + occ_33, data = mydata.f)
m_n_cf <- lm(ln.hourly.wage ~ cmpt+fax + DVAGEGR + (DVAGEGR)^2 + DVH20 + (DVH20 )^2 + d_postgrad + d_uni +d_coll+d_lhigh_sch +H42A + d_prt_job + prov_NL + prov_PE + prov_NS + prov_NB+ prov_QC + prov_MB + prov_SK + prov_AB +prov_BC + ind_1 + ind_2 + ind_3 + ind_4 + ind_5 + ind_6 + ind_7 + ind_8 + ind_9 + ind_10+ ind_11 + ind_13 + ind_14 + ind_15 + ind_16 + ind_17 + ind_18 + firm_m + firm_l, data = mydata.m)
m_y_cf <- lm(ln.hourly.wage ~ cmpt+ fax + DVAGEGR + (DVAGEGR)^2 + DVH20 + (DVH20 )^2 + d_postgrad + d_uni +d_coll+d_lhigh_sch +H42A + d_prt_job + prov_NL + prov_PE + prov_NS + prov_NB+ prov_QC + prov_MB + prov_SK + prov_AB +prov_BC + ind_1 + ind_2 + ind_3 + ind_4 + ind_5 + ind_6 + ind_7 + ind_8 + ind_9 + ind_10+ ind_11 + ind_13 + ind_14 + ind_15 + ind_16 + ind_17 + ind_18 + firm_m + firm_l+ occ_2 + occ_3 + occ_4 +occ_5+occ_6 +occ_7 +occ_8 + occ_9 + occ_10 +occ_11+ occ_12 + occ_13 + occ_14 +occ_15+ occ_16 +occ_17 +occ_18 + occ_19+ occ_20 +occ_21 +occ_22 + occ_23 + occ_24 +occ_25+occ_26 +occ_27 +occ_28 + occ_29 + occ_30 + occ_31 + occ_32 + occ_33, data = mydata.m)
f_n_cf <- lm(ln.hourly.wage ~ cmpt+fax + DVAGEGR + (DVAGEGR)^2 + DVH20 + (DVH20 )^2 + d_postgrad + d_uni +d_coll+d_lhigh_sch +H42A + d_prt_job + prov_NL + prov_PE + prov_NS + prov_NB+ prov_QC + prov_MB + prov_SK + prov_AB +prov_BC + ind_1 + ind_2 + ind_3 + ind_4 + ind_5 + ind_6 + ind_7 + ind_8 + ind_9 + ind_10+ ind_11 + ind_13 + ind_14 + ind_15 + ind_16 + ind_17 + ind_18 + firm_m + firm_l, data = mydata.f)
f_y_cf <- lm(ln.hourly.wage ~ cmpt+ fax + DVAGEGR + (DVAGEGR)^2 + DVH20 + (DVH20 )^2 + d_postgrad + d_uni +d_coll+d_lhigh_sch +H42A + d_prt_job + prov_NL + prov_PE + prov_NS + prov_NB+ prov_QC + prov_MB + prov_SK + prov_AB +prov_BC + ind_1 + ind_2 + ind_3 + ind_4 + ind_5 + ind_6 + ind_7 + ind_8 + ind_9 + ind_10+ ind_11 + ind_13 + ind_14 + ind_15 + ind_16 + ind_17 + ind_18 + firm_m + firm_l+ occ_2 + occ_3 + occ_4 +occ_5+occ_6 +occ_7 +occ_8 + occ_9 + occ_10 +occ_11+ occ_12 + occ_13 + occ_14 +occ_15+ occ_16 +occ_17 +occ_18 + occ_19+ occ_20 +occ_21 +occ_22 + occ_23 + occ_24 +occ_25+occ_26 +occ_27 +occ_28 + occ_29 + occ_30 + occ_31 + occ_32 + occ_33, data = mydata.f)
```
The following 3 tables are testing the effect of computer or fax, along with other variables on the natural log of hourly wages:
```{r,echo=FALSE, results="asis"}
stargazer(m_n_cmpt, m_y_cmpt,f_n_cmpt, f_y_cmpt,
title="Table 1: Tools Entered Seperatly Computer",
column.labels = c("Men No Occ", "Men Yes Occ", "Women No Occ", "Women Yes Occ"),
keep = c("cmpt"),
omit.stat=c("LL","ser","f","rsq"),
report = "vc*t",
type="html"
)
stargazer(m_n_fax, m_y_fax,f_n_fax, f_y_fax,
title="Table 2: Tools Entered Seperatly Fax",
column.labels = c("Men No Occ", "Men Yes Occ", "Women No Occ", "Women Yes Occ"),
keep = c("fax"),
omit.stat=c("LL","ser","f","rsq"),
report = "vc*t",
type="html"
)
stargazer(m_n_cf, m_y_cf,f_n_cf, f_y_cf,
title="Table 3: Tools Entered Together",
column.labels = c("Men No Occ", "Men Yes Occ", "Women No Occ", "Women Yes Occ"),
keep = c("cmpt","fax"),
omit.stat=c("LL","ser","f","rsq"),
report = "vc*t",
type="html")
```
In Table 1, we have a dummy variable that takes the value 1 if the worker uses a computer and takes the value 0 otherwise. The wage premium for male computer users equals 19% (i.e. exp(0.175)-1) and it is equal to 19% (exp(0.171)-1) for women. The wage premium for men dropped to 12% when we include the occupation variables and the wage premium for women users dropped to 14% when we include the occupation variables.
In Table 2, we replaced the computer use dummy variable by a fax user dummy variable. When this is done, we find a wage premium of 19% for male fax users and 24% for female fax users. When we add the 33 occupation variables the wage premium for male fax users drop to 12% and the women users dropped to 17%.
In Table 3, we entered both fax users and computer users. The wage premium for computer users is 14% for men and it is 11% for women. On the other hand, the wage premium for fax users is 15% for men and it is 20% for women. Adding occupation variables, it dropped the computer users to 9% for men and 10% for women. The men fax users dropped to 10% and the women fax users dropped to 15%.
# Running a robustness test for the standard errors:
```{r,include=FALSE,echo=FALSE, results="asis"}
lm.1.se <- sqrt(diag(vcovHC(m_n_cmpt, type="HC1")))
lm.2.se <- sqrt(diag(vcovHC(m_y_cmpt, type="HC1")))
lm.3.se <- sqrt(diag(vcovHC(f_n_cmpt, type="HC1")))
lm.4.se <- sqrt(diag(vcovHC(f_y_cmpt, type="HC1")))
lm.11.se <- sqrt(diag(vcovHC(m_n_fax, type="HC1")))
lm.12.se <- sqrt(diag(vcovHC(m_y_fax, type="HC1")))
lm.13.se <- sqrt(diag(vcovHC(f_n_fax, type="HC1")))
lm.14.se <- sqrt(diag(vcovHC(f_y_fax, type="HC1")))
lm.21.se <- sqrt(diag(vcovHC(m_n_cf, type="HC1")))
lm.22.se <- sqrt(diag(vcovHC(m_y_cf, type="HC1")))
lm.23.se <- sqrt(diag(vcovHC(f_n_cf, type="HC1")))
lm.24.se <- sqrt(diag(vcovHC(f_y_cf, type="HC1")))
```
```{r,echo=FALSE, results="asis"}
stargazer(m_n_cmpt, m_y_cmpt,f_n_cmpt, f_y_cmpt,
se = list(lm.1.se, lm.2.se, lm.3.se,lm.4.se),
title="Table 4: Tools Entered Seperatly Computer with Robust Errors",
column.labels = c("Men No Occ", "Men Yes Occ", "Women No Occ", "Women Yes Occ"),
keep = c("cmpt"),
omit.stat=c("LL","ser","f","rsq"),
report = "vc*t",
type="html"
)
stargazer(m_n_fax, m_y_fax,f_n_fax, f_y_fax,
se = list(lm.11.se, lm.12.se, lm.13.se,lm.14.se),
title="Table 5: Tools Entered Seperatly Fax with Robust Errors",
column.labels = c("Men No Occ", "Men Yes Occ", "Women No Occ", "Women Yes Occ"),
keep = c("fax"),
omit.stat=c("LL","ser","f","rsq"),
report = "vc*t",
type="html"
)
stargazer(m_n_cf, m_y_cf,f_n_cf, f_y_cf,
se = list(lm.21.se, lm.22.se, lm.23.se,lm.24.se),
title="Table 6: Tools Entered Together with Robust Errors",
column.labels = c("Men No Occ", "Men Yes Occ", "Women No Occ", "Women Yes Occ"),
keep = c("cmpt","fax"),
omit.stat=c("LL","ser","f","rsq"),
report = "vc*t",
type="html")
```
From the robustness test we can see that all of our variables are still significant, so we can’t discuss anything regarding falsification since everything looks the same significance.