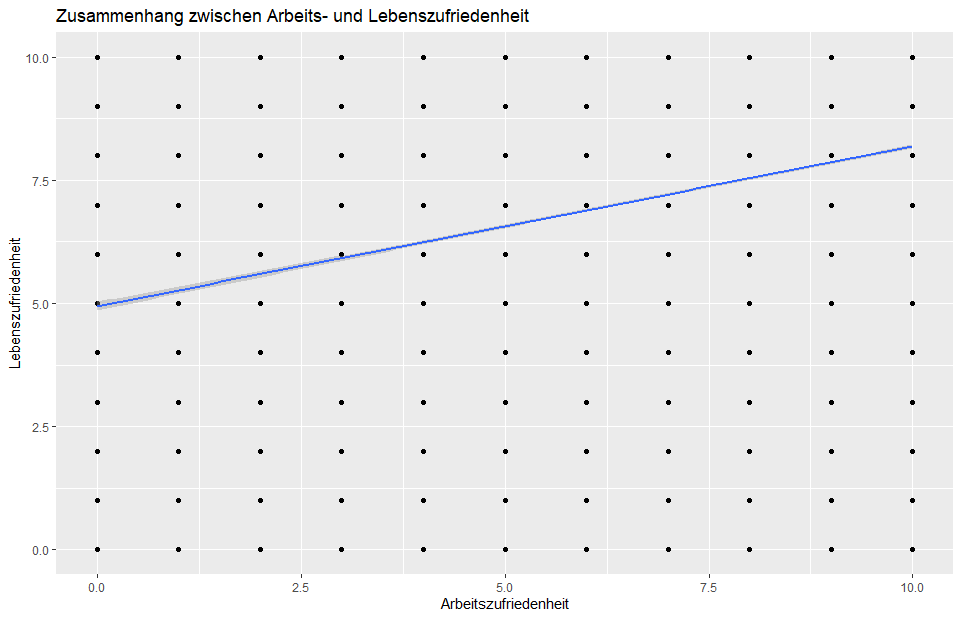
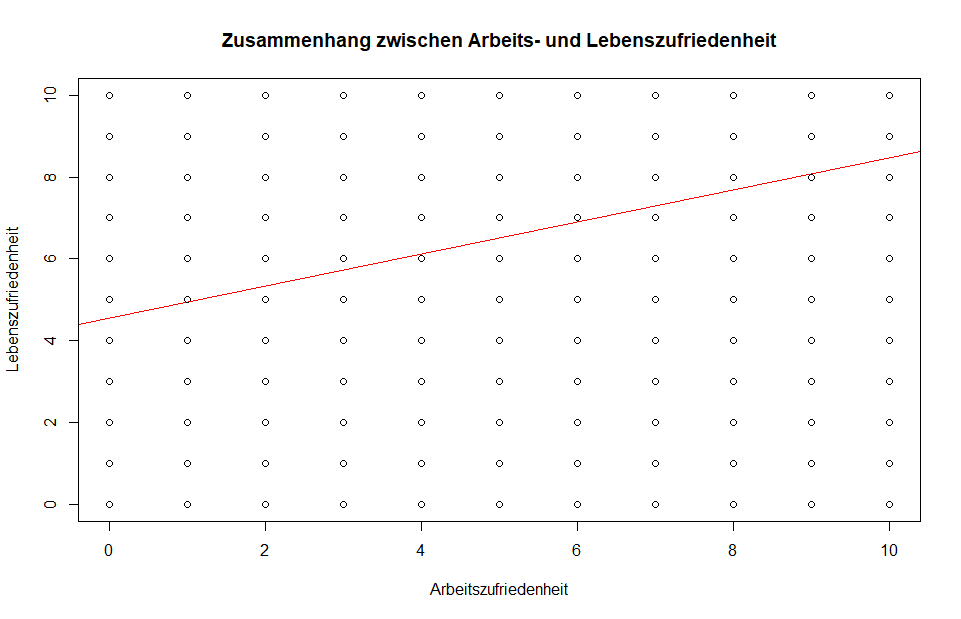
I hope you can help me out. I am doing a linear regression in RStudio for the first time and I wanted to get a nice plot of the data with a regression line.
The data I use consits out of 21.000 observations and I do not know if this is the reason, but you can not see any trends within the plot, because the amount of dots is too low or the scale is wrong?
Does anybody have an idea on how to solve this problem?
Thank you very much in advance.
This is the code I used:
plot(ESS_Datensatz_bereinigt$stfjb, ESS_Datensatz_bereinigt$happy, main= "Zusammenhang zwischen Arbeits- und Lebenszufriedenheit",
xlab= "Arbeitszufriedenheit", ylab = "Lebenszufriedenheit",
abline(lm(ESS_Datensatz_bereinigt$stfjb ~ ESS_Datensatz_bereinigt$happy), col ="red"))
I also tried it using the ggplot2- package, but that didn*t help:
To help us help you, could you please prepare a reproducible example (reprex) illustrating your issue? Please have a look at this guide, to see how to create one:
Or can you find a way to share your used data? Probably you cannot mimick this with inbuilt data set.
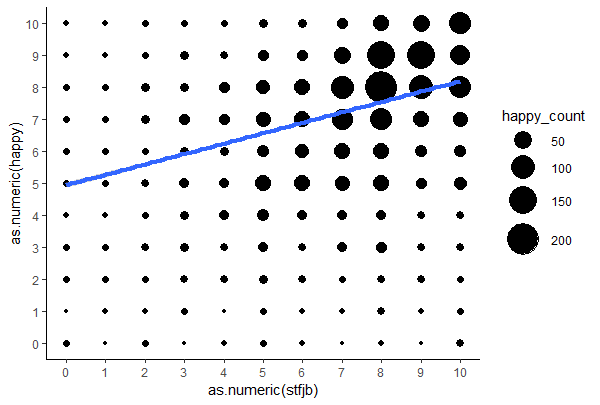
Wouldn't you agree that it's a bit strange to have datapoints spreaded equally over the whole range?
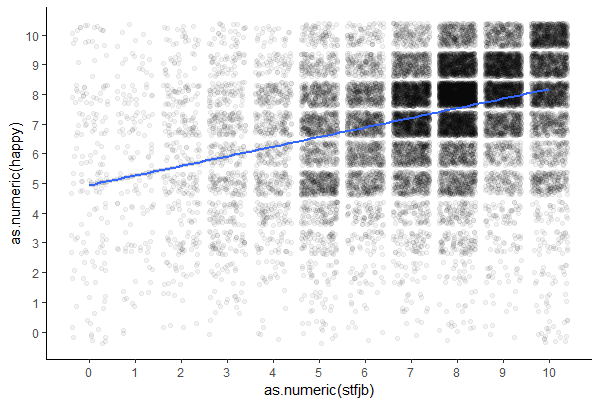
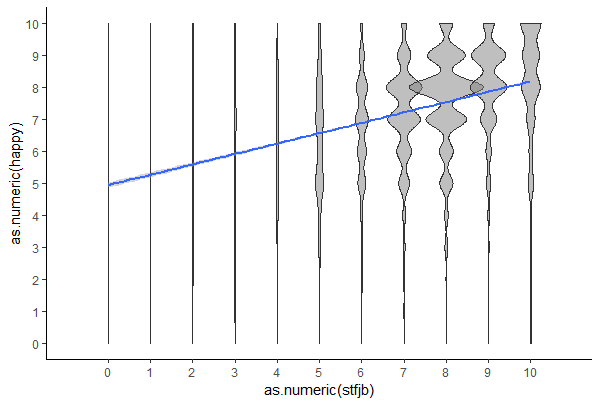
To me it seems you have just multiple readouts per datapoint, just because people chose points on a scale from 1 to 10. So actually in the plot you hide some data. You could add some jitter to show the overlap, or think if another representation might be better, e.g. a boxplot or a violin-plot. Or a ballon-plot, where the size of the point actually shows the count at this location.
You are right: The 2 variables were raised with a 11-point likert scale.
You'll probably need the "haven" package, since this is a .sav-file.
I want to do a linear regression with "happy" (General happiness) being my dependent variable and "stfjb" (job satisfaction) being my independet variable. The idea of the work is to prove the hypothesis that the more satisfied you are with your job, the more satisfied you are with life in general.
The regression itselfs works with p < 0,001, but I just can*t plot a graph showing the regression...
Option 2: Violin Plots: I purposely increased the width to show the crowding in the 8-8 area. Also the scale="count" is important to show the areas with more counts.
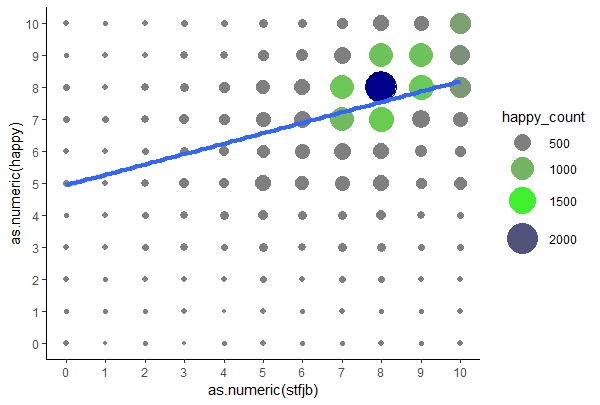
Isn't this illustrative enough? Actually I had a mistake inside, as it counted the occurrences per country so there are still many different points per position. Still you need all the points for the linear fit but at least they should have the same property.
Just remove cntry from the "group_by", then add "colour = happy_count" to the geom_point and define the colours with "scale_colour_gradientn()", here the "values = c(0.25, 0.75, 1)" defines the position of each colour on a scale from 0 to 1. 0.25 corresponds to 500, 0.75 to 1500 and 1 to the highest value (2164 actually) Therefor 2000 is not complete blue. Sorry I am not very proficient with gradient colours...