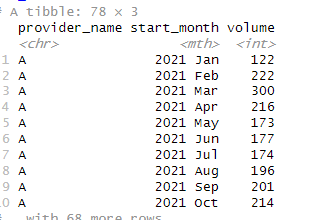
@technocrat thank you, I have used the reprex function to reproduce my full data. Right now, I am trying to forecast client volume only based on start date. Here is the full aggregated client volume data:
s_data <-tibble::tribble(
~provider_name, ~start_month, ~volume,
"A", "2021 Jan", 122L,
"A", "2021 Feb", 222L,
"A", "2021 Mar", 300L,
"A", "2021 Apr", 216L,
"A", "2021 May", 173L,
"A", "2021 Jun", 177L,
"A", "2021 Jul", 174L,
"A", "2021 Aug", 196L,
"A", "2021 Sep", 201L,
"A", "2021 Oct", 214L,
"A", "2021 Nov", 227L,
"A", "2021 Dec", 218L,
"A", "2022 Jan", 211L,
"A", "2022 Feb", 214L,
"A", "2022 Mar", 269L,
"A", "2022 Apr", 228L,
"A", "2022 May", 288L,
"A", "2022 Jun", 319L,
"A", "2022 Jul", 296L,
"A", "2022 Aug", 323L,
"A", "2022 Sep", 320L,
"A", "2022 Oct", 331L,
"A", "2022 Nov", 295L,
"A", "2022 Dec", 237L,
"A", "2023 Jan", 325L,
"A", "2023 Feb", 298L,
"B", "2021 Jan", 52L,
"B", "2021 Feb", 74L,
"B", "2021 Mar", 69L,
"B", "2021 Apr", 46L,
"B", "2021 May", 44L,
"B", "2021 Jun", 49L,
"B", "2021 Jul", 45L,
"B", "2021 Aug", 52L,
"B", "2021 Sep", 68L,
"B", "2021 Oct", 79L,
"B", "2021 Nov", 61L,
"B", "2021 Dec", 56L,
"B", "2022 Jan", 64L,
"B", "2022 Feb", 58L,
"B", "2022 Mar", 75L,
"B", "2022 Apr", 47L,
"B", "2022 May", 63L,
"B", "2022 Jun", 78L,
"B", "2022 Jul", 64L,
"B", "2022 Aug", 93L,
"B", "2022 Sep", 68L,
"B", "2022 Oct", 54L,
"B", "2022 Nov", 78L,
"B", "2022 Dec", 55L,
"B", "2023 Jan", 106L,
"B", "2023 Feb", 85L,
"C", "2021 Jan", 135L,
"C", "2021 Feb", 231L,
"C", "2021 Mar", 278L,
"C", "2021 Apr", 246L,
"C", "2021 May", 289L,
"C", "2021 Jun", 404L,
"C", "2021 Jul", 304L,
"C", "2021 Aug", 288L,
"C", "2021 Sep", 270L,
"C", "2021 Oct", 298L,
"C", "2021 Nov", 334L,
"C", "2021 Dec", 274L,
"C", "2022 Jan", 362L,
"C", "2022 Feb", 278L,
"C", "2022 Mar", 315L,
"C", "2022 Apr", 310L,
"C", "2022 May", 328L,
"C", "2022 Jun", 413L,
"C", "2022 Jul", 369L,
"C", "2022 Aug", 430L,
"C", "2022 Sep", 442L,
"C", "2022 Oct", 429L,
"C", "2022 Nov", 439L,
"C", "2022 Dec", 336L,
"C", "2023 Jan", 413L,
"C", "2023 Feb", 383L
)
I have 3 providers and I am trying to forecast the client volume for the next 1 year. I have used these forecast model and used this function to forecast client volume for the next 1 year, however, I am interested in knowing how you would forecast the data since I am having doubts about the accuracy of the model and I am getting errors about missing data:
data_stretch <- s_data %>%
stretch_tsibble(.init = 12, .step = 1) %>%
filter(.id !=max(.id))
fit <- data_stretch %>%
model(
#seasonal_naive = SNAIVE(volume),
naive_a = NAIVE(volume),
drift_a = RW(volume ~ drift()),
#rw_dr = RW(log(volume) ~ drift()),
#mean_a = MEAN(volume),
tslm_a = TSLM(volume ~ trend()),
ets = ETS(volume),
arima = ARIMA(volume)
) %>%
forecast(h = "1 year")
fit %>%
accuracy(s_data)