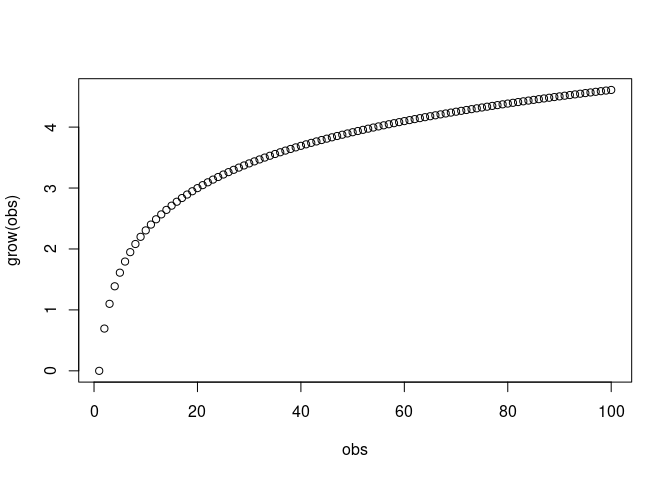
On a cohort basis (daily or weekly), cumulative revenue is logarithmic in shape. I'd like to develop a predictive model that predicts the cumulative revenue of a cohort many weeks out after a week or two since install.
Before diving in I'm trying to visualize in my mind what a training and prediction workflow could look like.
Which historic data do I use to fit a model? Lets say our app has 5 years of historic data. For each new weekly cohort, I'd like to predict out into the future e.g 3 months, 6 months, 12 months, etc. of what the cohorts cumulative revenue might look like. Do I use the 7 days spend behavior of each cohort to inform a custom prediction per cohort? Or do I Just train a model on all historic data and predict a uniform prediction on all new cohorts will have $x, $y, $z cumulative revenue after 3, 6 and 12 months?
Assuming variation in cohort behavior, presumably I want to be able to use the first e.g. 7 days of cumulative revenue for the cohort to be able to inform a future prediction, as opposed to ignoring that and using a 'main' model that is trained on all historic data.
If we want to predict out as far as 6 months or a year, then any model must surely have at least 6 months or a years worth of historic data to train with. i.e. I could not fit a new model just for a specific cohort with 7 days of revenue data and then attempt to predict what 6 months of revenue look like. So how can I combine data unique to the cohort with historic data to make a prediction?
Within the above context, what are some good cohort based approaches to cumulative revenue prediction? What's my training data? Do I use the first 7 days of spend behavior to inform my prediction?
This is a problem in the time series domain. We would not consider that observations at different frequencies as cohorts in the same sense that it would be used in panel data or other methods where cohort signifies different categories, such as male/female/other. It is possible to do cohorts by app or app type, though.
With your historical data, there is a choice of the frequency of observations, hourly,, daily, weekly, monthly, etc. As the frequency grows smaller, the potential accuracy of the forecast horizon increases. Confidence bands for time series projections quickly become so wide as to encompass negative values on the one hand, and unrealistically great positive values on the other.
Thank you for the information. Time series makes sense to me. Nevertheless, I've been re-learning about log models lately and almost want to force this problem into a log regression script. I was thinking about how to do that over the weekend. The thought I'm wrangling with is that if cumulative revenue is logarithmic and fits a logarithmic regression well, how could I use new data from 7 days of spend behavior to inform the model to make a prediction. I was thinking that I could model the growth rate from day to day since install and then, for a given cohort of installs (installs on a specific day or week) then apply to growth rates to the existing cumulative revenue from day 7 to 'predict' out to day 180, 365 etc.
Ignoring the fact that ts is more applicable here, just to satisfy my own curiosity, is there some approach where I could still use a log regression model in this scenario, such as what I describe above?
From any seven periods, the future can be projected indefinitely if that's the case.
More likely is that the log is a central tendency with variability around it and subsequent observations are taken to assess the current confidence bands. Can you gin up some data to explore this?
Here you go. Will ping you a password to access assuming I can message people on this forum.
I took my data and sampled and transformed a sample so it's anonymous, but the shape is still the same. File attached. When you take the log of tenure and plot against cumamt (cumulative amount) it's pretty straight. What do you reckon?