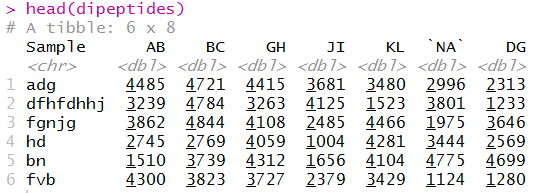
I have a data file with protein amino acids info. (actually dipeptides) as features. The dipeptide in question is "NA". To me "NA" = Asparagine + Alanine. However when R sees "NA" it calls the feature X244.
Running: colnames(cancer_human_comps)[244] <- "NA" # This does not clear the issue.
How do you get the data into R? It works when starting from an Excel sheet using read_excel from the readxl library.
This puts the NA column in backticks.
Maybe other importers can be modified as well.
For example, read_csv(readr / tidyverse) accepts definitions for NA, when you say: dipeptides = read_csv("Book2.csv", na = "")
you basically excludes "NA" as NA and then its kept as well.
When you have NA in your matrix then you have another problem.
dipeptides = read_csv("Book2.csv", na = "")
Parsed with column specification:
cols(
Sample = col_character(),
AB = col_double(),
BC = col_double(),
GH = col_double(),
JI = col_double(),
KL = col_double(),
`NA` = col_double(),
DG = col_double()
)
>