What-Stat: a shiny app which performs statistical analysis on WhatsApp data
Authors: Lucainson RAYMOND
Abstract: This based-NLP app lets users perform statistical analysis on their own WhatsApp conversations at a glance. First, users have to upload their WhatsApp conversations after exporting that from their Smartphone (android or ios). And then, automatically, the app will show some keys statistics about their messages, the top active users, the most frequent words used by users, the sentiment scoring based on emoji usage by users, the topics that dominate the conversations over time, the detection of communities formed by users in a chat group(network analysis). And at last, the app allows users to forecast the numbers of messages that will arrive in a ten (10) day horizon using a time series model.
Full Description: The number of users of the Whatsapp network around the world has already reached more than 2 billion (Whatsapp, 2019). Over 5 million businesses use Whatsapp Business services (PYMNTS, 2019). And we exchange sixty-five (65) billion messages on Whatsapp on average per day worldwide (Statista, 2019). These statistics provide no doubt that WhatsApp is a treasure trove of data that can be used to create value and explore our past, understand our present and plan for the future. In addition, the dazzling technological advances in the field of Natural Language Processing (NLP) provide us with cutting-edge tools for analyzing this kind of data (unstructured data) and to extract insights from it. Fascinated by NLP, I therefore have a Data Science (DS) project relating to the manipulation of data of this nature (WhatsApp Data). So I took the opportunity offered by Shiny Contest 2021 to make my project visible. And at the same time will serve the community.
My app lets users discover some basic statistics about their conversations:
- Number of messages exchanged over time
- Number of messages deleted over time
- Number of participants in the discussion
- Bar plot of web link shared
- And so forth
Fig.1
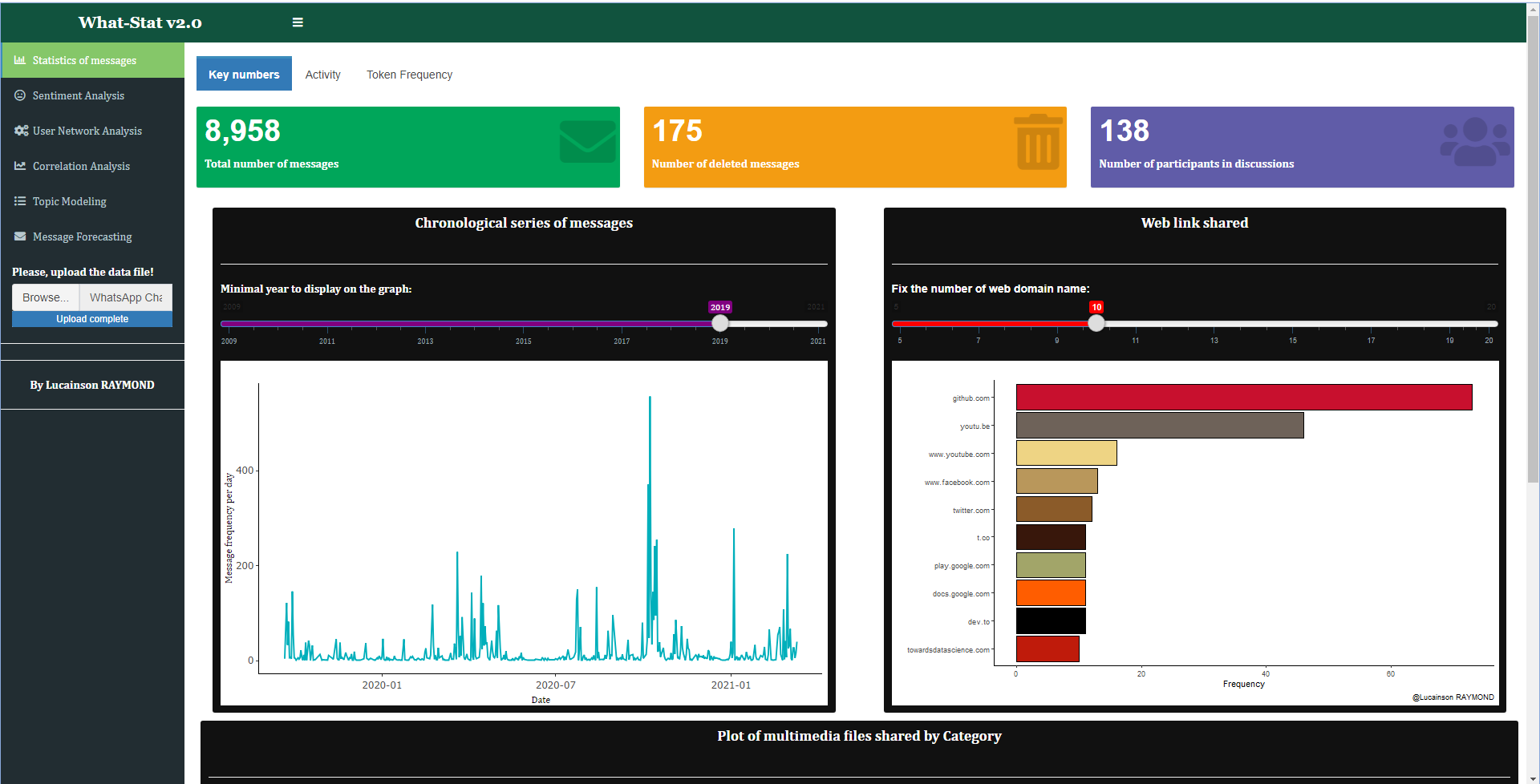
Fig.2
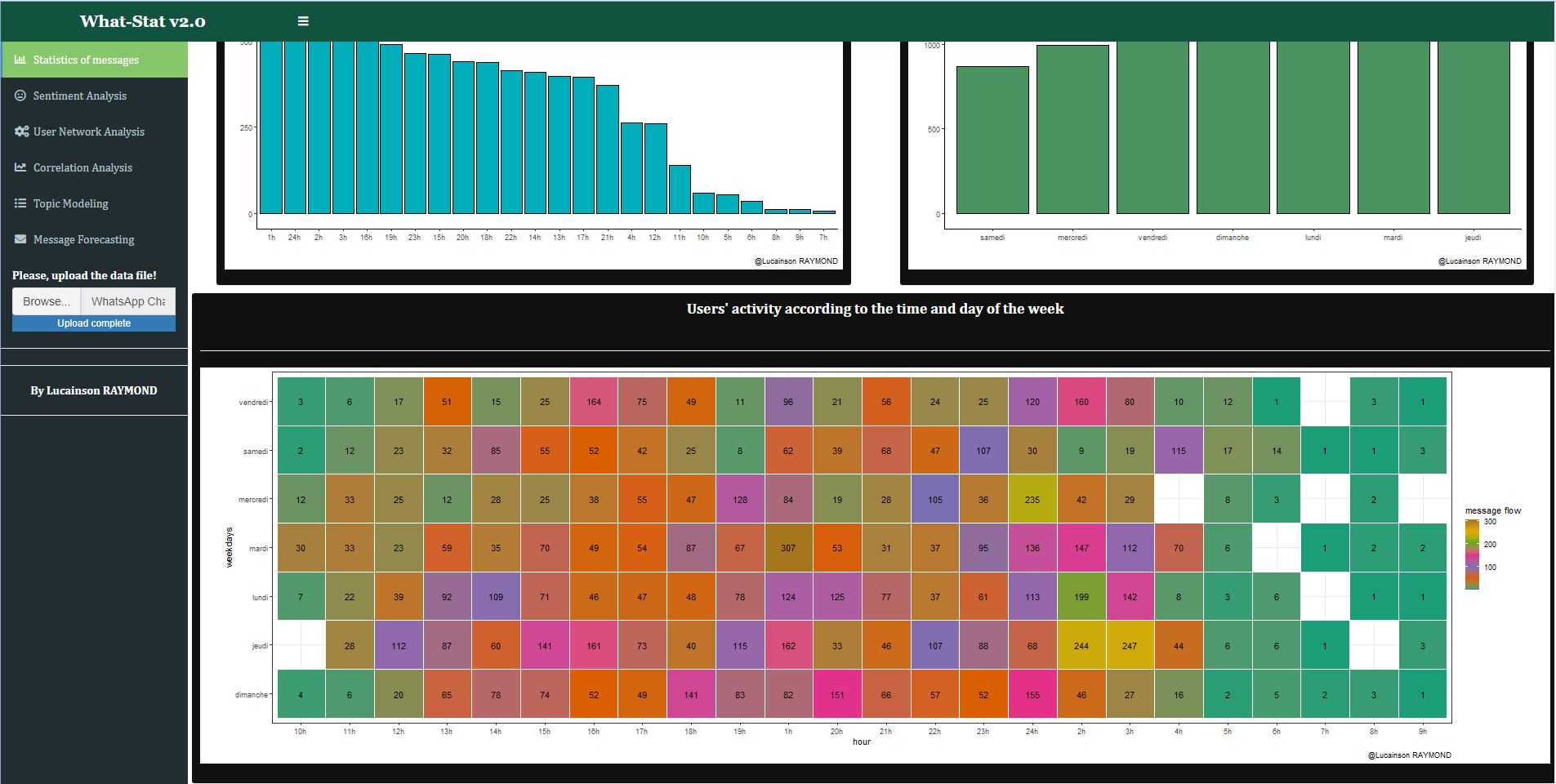
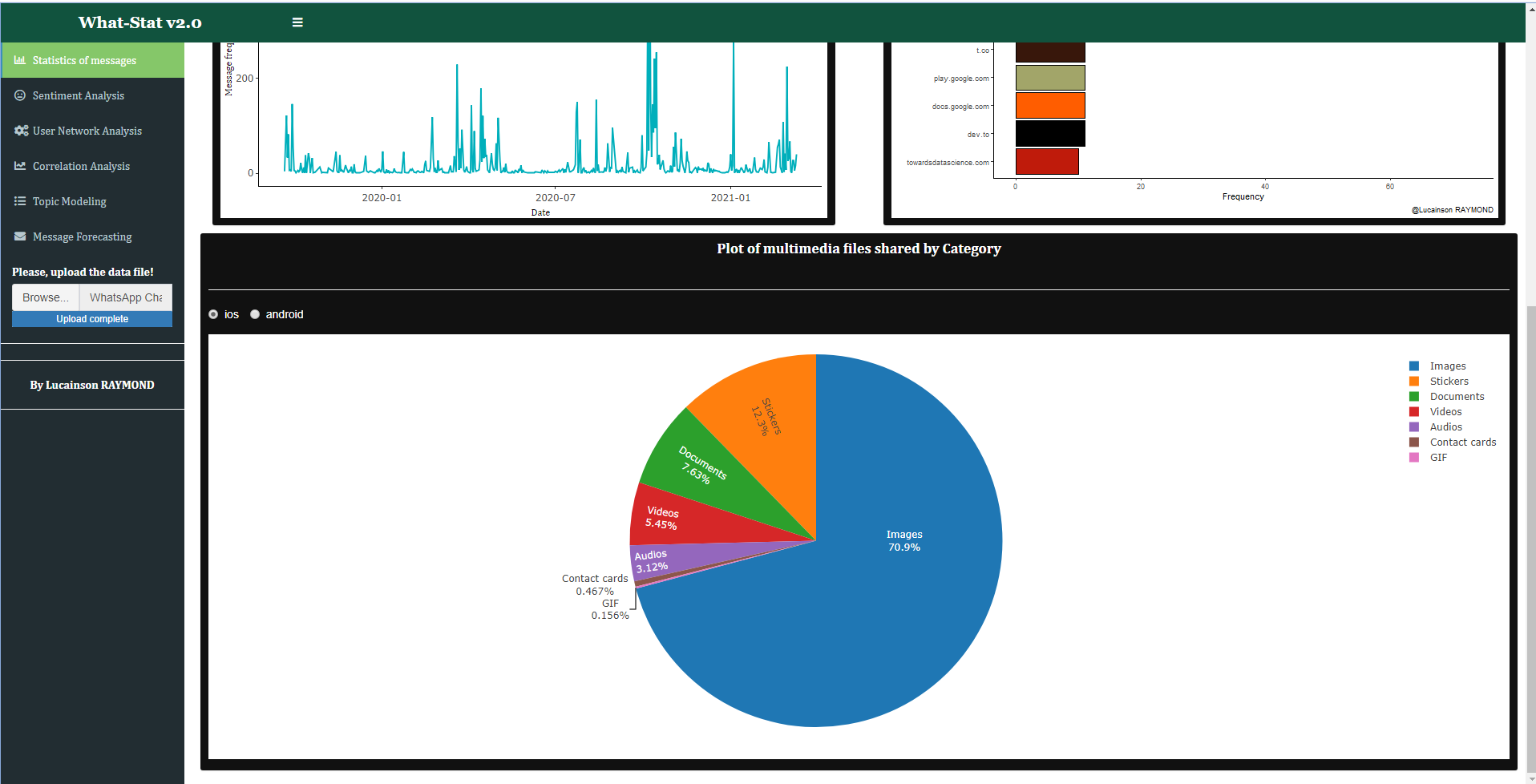
Users have also the opportunity to see statistics about the multimedia files shared.
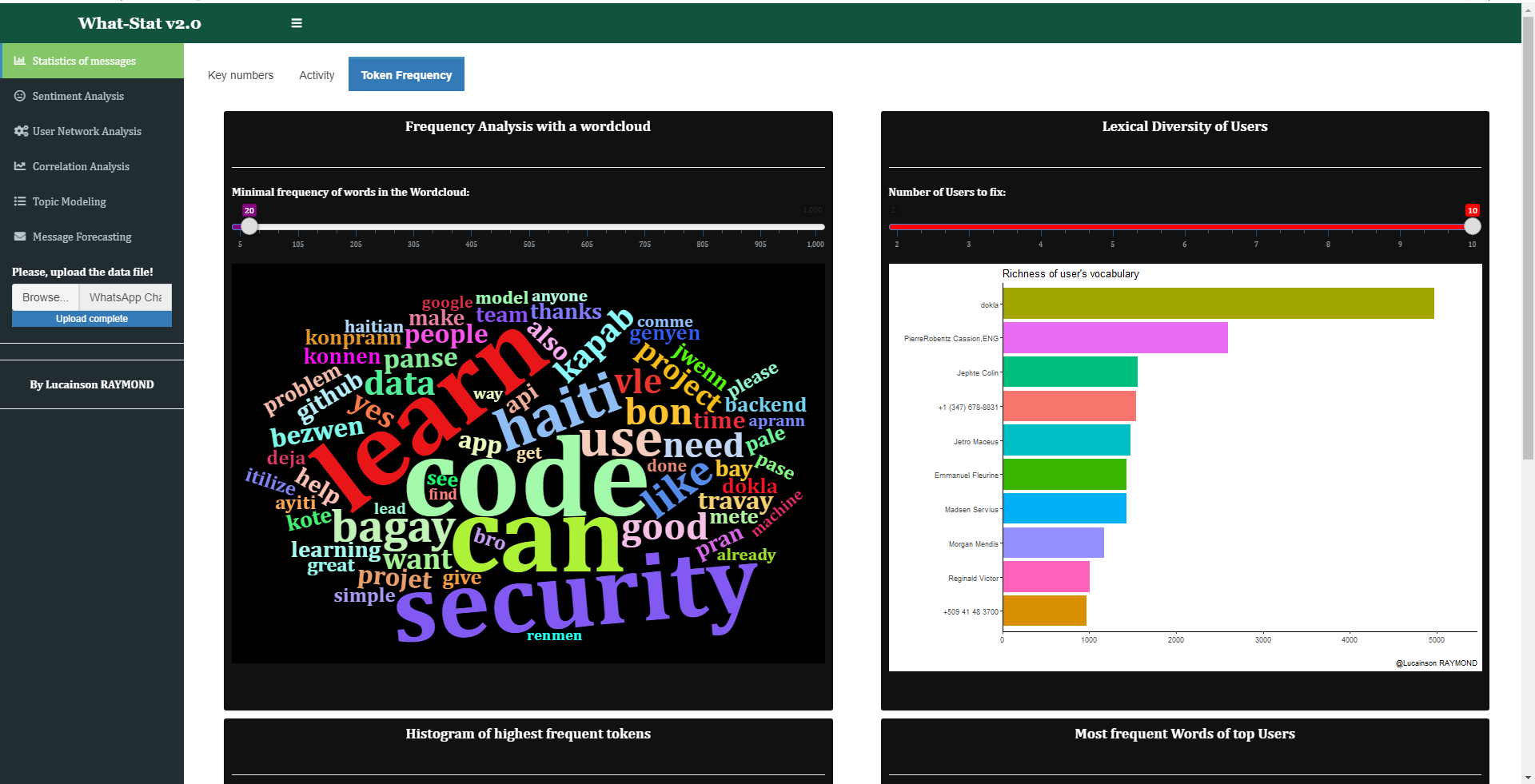
Fig.3
Users have the possibility to see also the most frequent words (overall and by top most active users). See below a little example.
Fig.4
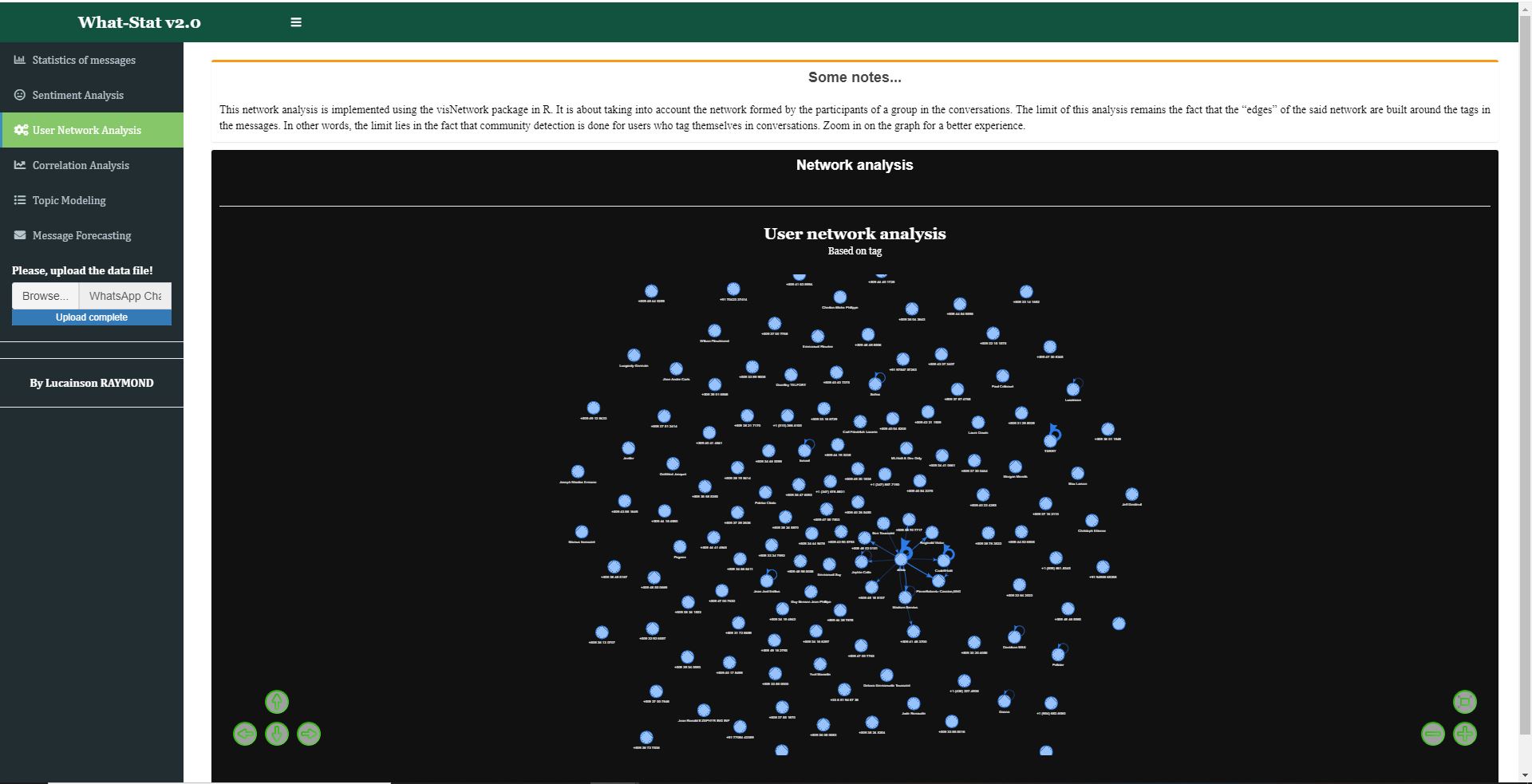
About the User network analysis part of the app. Note that it only works for chat group. As its name suggests, it lets discover communities formed by users in a group based on tag.
Fig.5
The app has a Sentiment analysis part. This results from the cross between the emojis contained in the different messages and the lexicon of feelings called Emoji Sentiment Ranking developed by a group of Russian developers (Kralj Novak P, Smailovic J, Sluban B, Mozetic I (2015) Sentiment of Emojis. PLoS ONE 10 (12): e0144296). The Emoji Sentiment Ranking maps the feelings of emojis most commonly used these days. Regarding the ranking, the classification process and analysis are detailed by the authors in this article: link for the article
The Correlation analysis is another great part. I let you discover it by yourself.
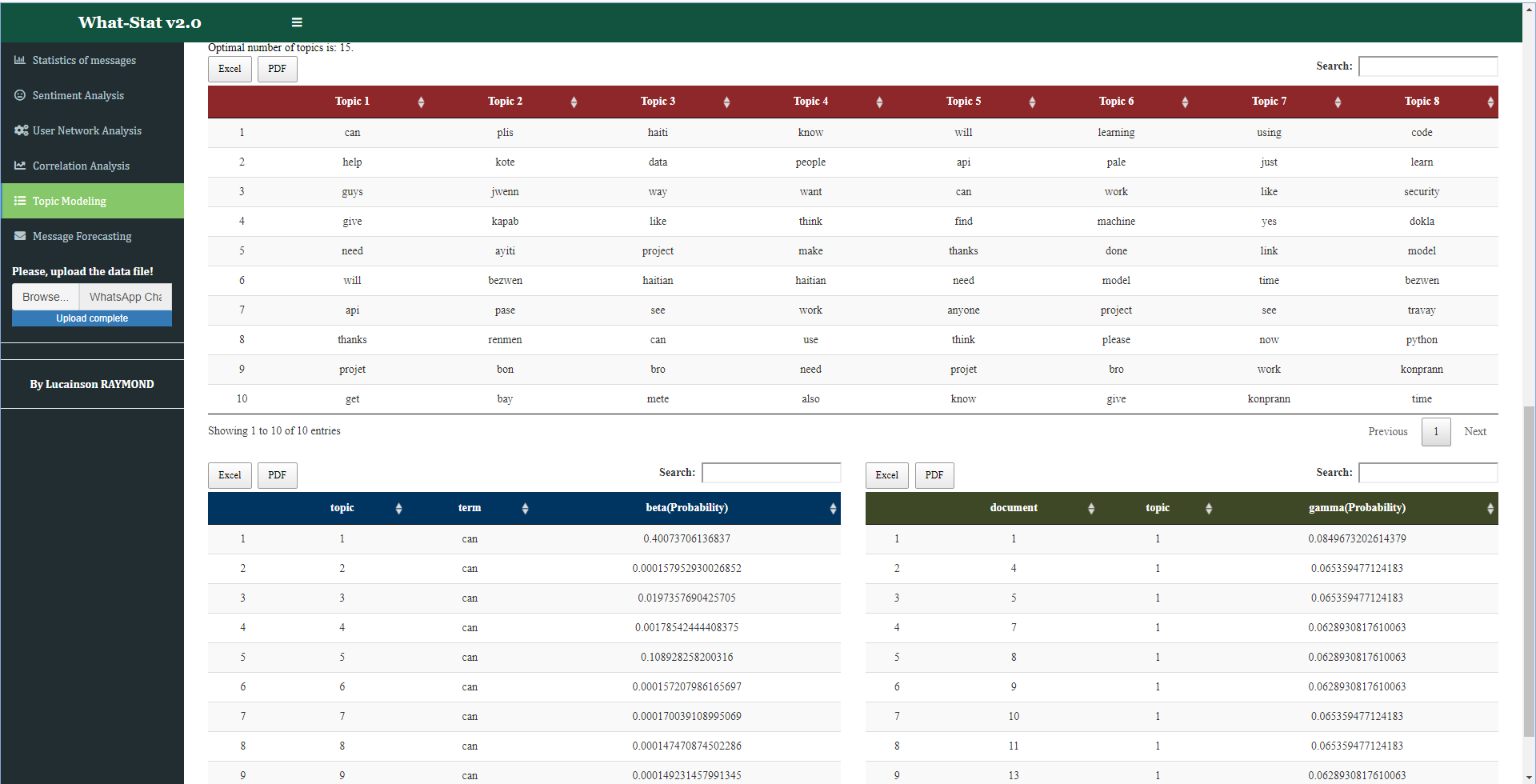
Through the app, you have the possibility to track the topics more likely (that is to say according to a certain probability) to be discussed across time. So we talk about "topic modeling". The topic modeling here is built with the LDA (Latent Dirichlet Allocation) model. A fundamental aspect of this modeling is the message generation system is based on a Markov chain, itself based on strings of n-grams (or sequences of words of length n) of the corpus. The LDA model here is based on the idea that each document in the corpus (or WhatsApp message, in this case) belongs to a number of subjects, the subjects themselves being composed of a small number of words which are used most often in each of them. The model is trained multiple times to determine the maximum likelihood that each document (WhatsApp message) belongs to each subject, which is based on the probability that each subject/ word appears in the document given its frequency.
Fig.6
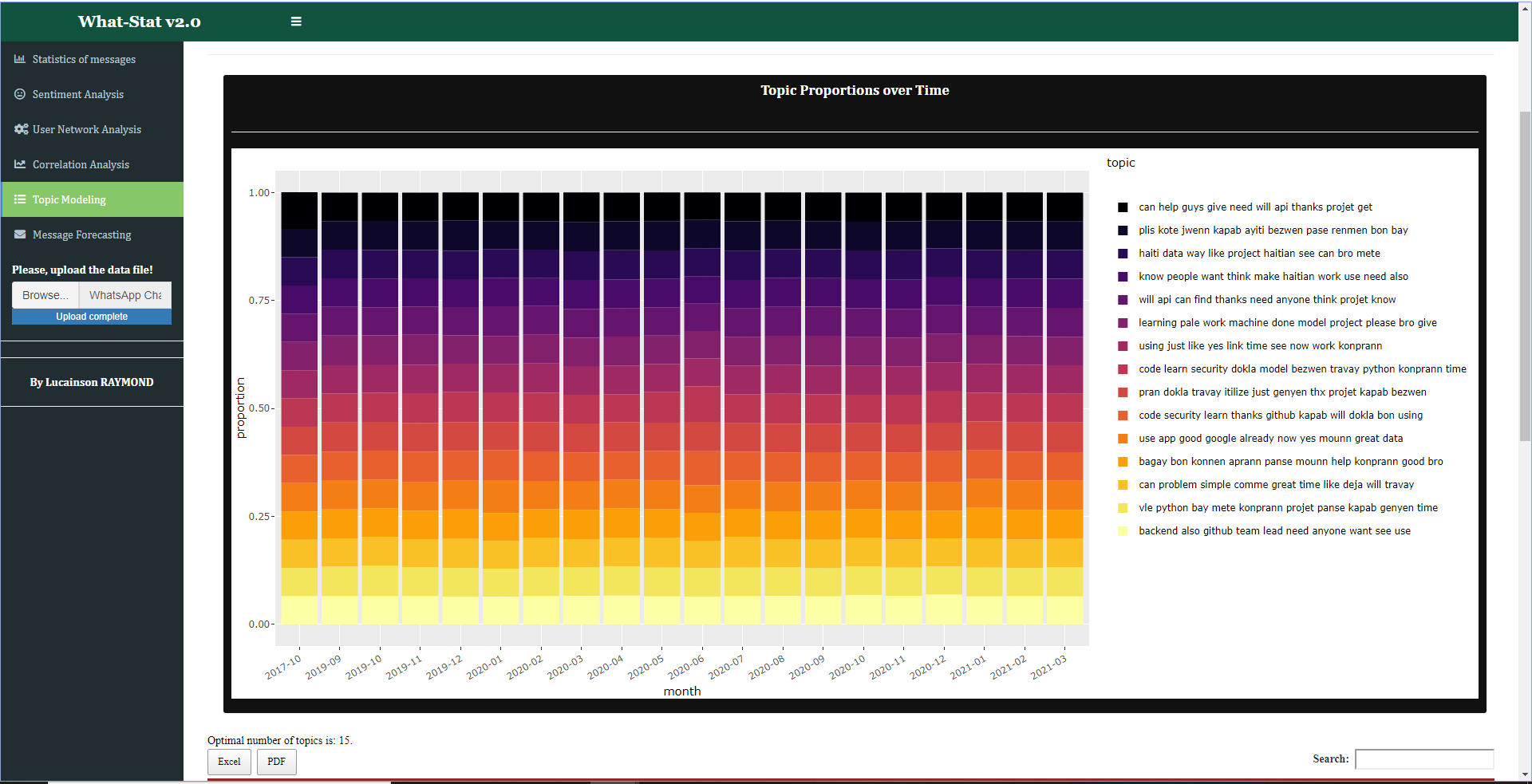
Fig.7
At last, you can make forecasts on the number of messages that will be exchanged within a ten (10) day horizon between the users. The app implements an ARIMA (Auto Regressive Integrated Moving Average) bagged-model described in Bergmeir et al. (2016). In this case, considering the original series (number of messages per day), a bootstrapped series is calculated with the Box-Cox and Loess-based decomposition (BLD) bootstrap. This is in order to escape the constraint of the probability distribution of said series. It is very difficult to describe the law of probability of WhatsApp message flow. So, with the bootstrap method, there is no need to test the normality of the series. In short, the optimal model is selected and estimated automatically using the Hyndman-Khandakar (2008) algorithm to select p and q and the Haslett and Raftery (1989) algorithm to estimate the d parameter. The Hyndman-Khandakar algorithm uses, among others, a combination of (KPSS) Kwiatkowski-Phillips-Schmidt-Shin test (unit root test), AKAIKE criterion minimization (AICc) & Maximum likelihood estimator (MLE) to obtain an optimal ARIMA model among all candidates (models). Note that one of the limitations of our model is that it gives certain prediction intervals (100%). But anyway, that's one of the eventual flaws in any bootstrap process.
Fig.8
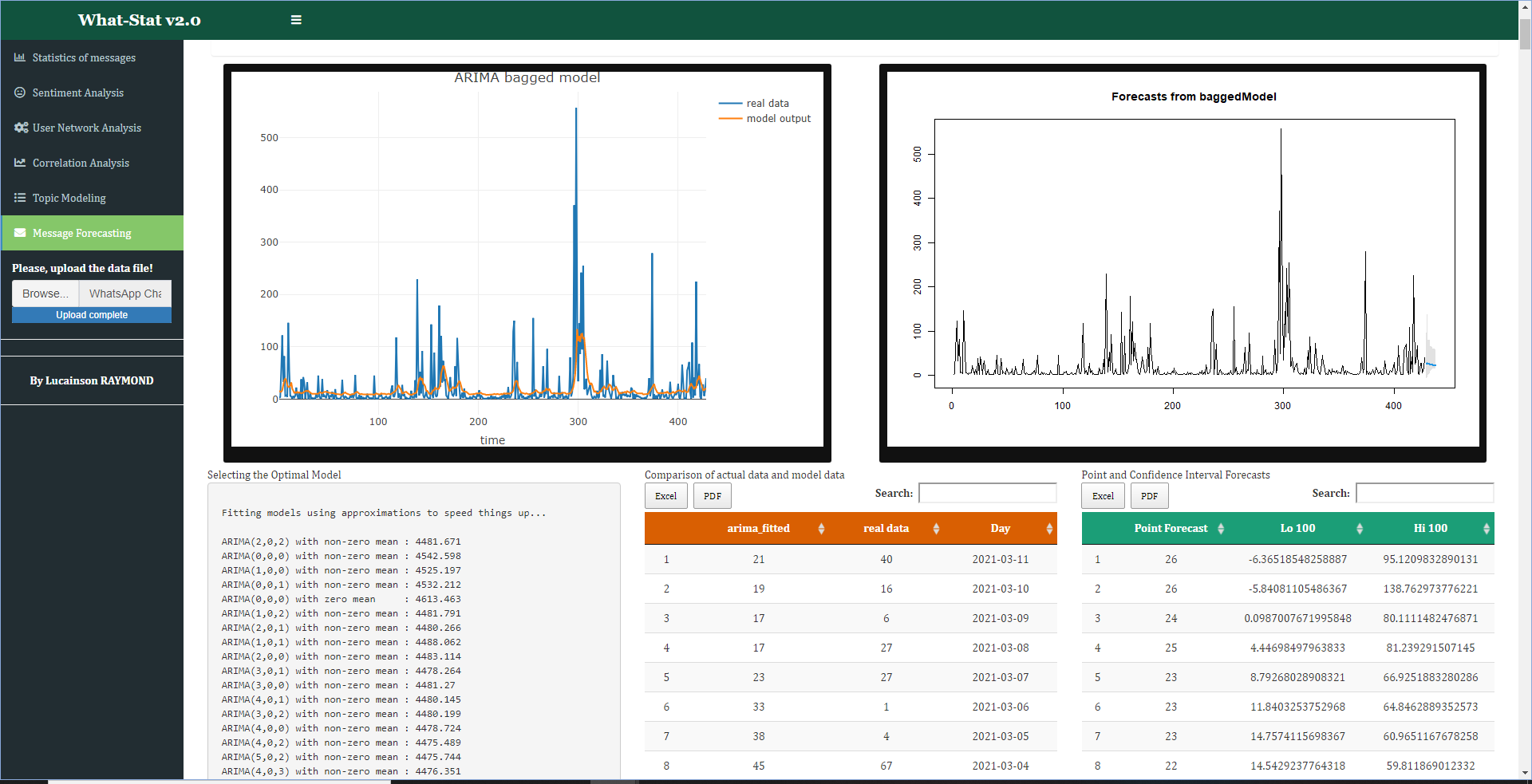
N.B The category of this app is Social Media Mining (SMM).
Keywords: WhatsApp; Natural Language Processing (NLP); Statistical analysis; bootstrap; Sentiment analysis; Network analysis; Correlation analysis; Topic modeling; Markov chain; Time series Analysis
Shiny app: https://lucainsonraymond.shinyapps.io/What-Stat/
Repo: GitHub - Lucainson/Shiny-contest-2021-what-Stat: This based-NLP app lets users perform statistical analysis on their own WhatsApp messages at a glance.
RStudio Cloud: Posit Cloud
Thumbnail:
Full image: