Hi all,
I'm working with an untidy excel file with multiple headers and I would love to learn how to parse the data with pivot_longer, if possible.
The data looks something like this:
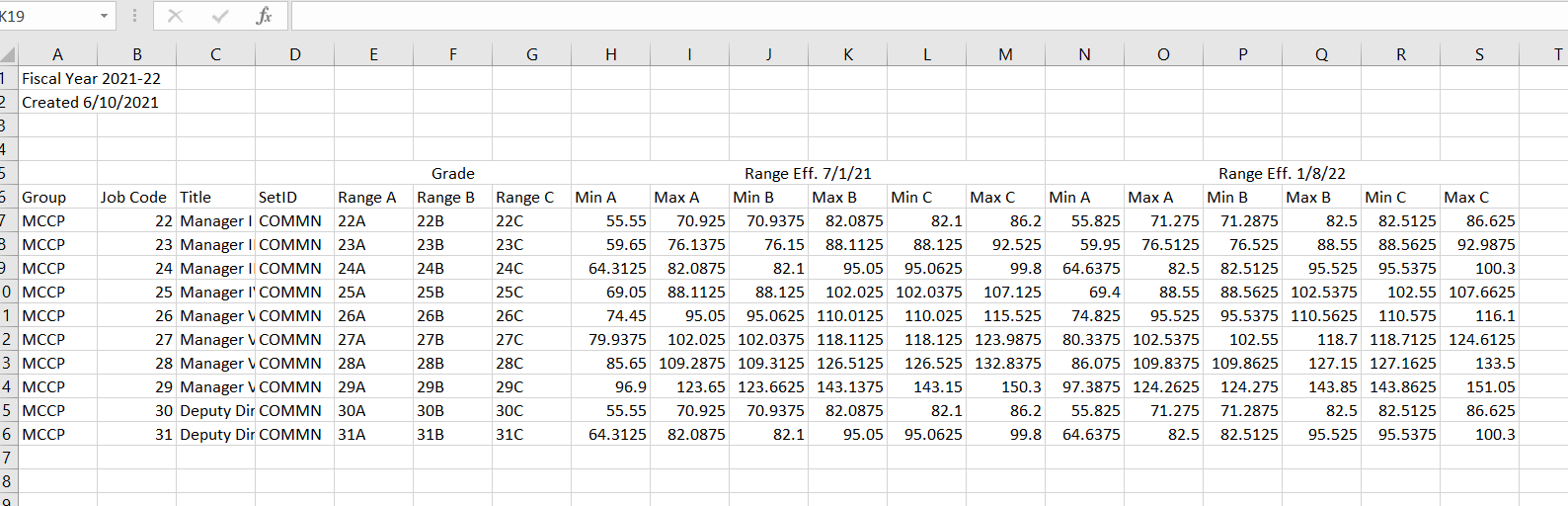
At first I thought I would be able to load the data and skip the first five rows with read_excel("data.xlsx", skip = 5), though that did not work as the Range eff. information is needed for functions elsewhere. I've used pivot_longer in the past for ggplot2 purposes, but I cannot wrap my head around how to use it here, especially since the sheet has merged cells.
The solution I came up with can be found below, but it'd be great to know if there is a more simple/tidy approach to this. Any insight would be greatly appreciated.
rangeratefunction <- function(nextcoladate) {
#enter date of next cola in YYYY-MM-DD format
nextcoladate <- as_date(nextcoladate)
rangerates <- read_excel("hourlyrates.xlsx", range = "Ranges!A6:H24")
rangerates <- bind_rows(rangerates, read_excel("hourlyrates.xlsx", range = "Ranges!A27:H74"))
rangecola1 <- bind_rows(read_excel("hourlyrates.xlsx", range = "Ranges!I6:N24"), read_excel("hourlyrates.xlsx", range = "Ranges!I27:N74"))
rangecola2 <- bind_rows(read_excel("hourlyrates.xlsx", range = "Ranges!O6:T24"), read_excel("hourlyrates.xlsx", range = "Ranges!O27:T74"))
rangerates <- if (today() < nextcoladate) {
bind_cols(rangerates, rangecola1)
} else {
bind_cols(rangerates, rangecola2)
}
rangerates <- rangerates %>% filter(SetID == "COMMN")
return(rangerates)
}