Hi all,
I am trying to scrap data from Coles website for one of my projects and I found examples for web scraping and tried to adapt the codes for my projects but didn't seem to work. Basically I am trying to get the product link on Coles website. The source codes look like below.
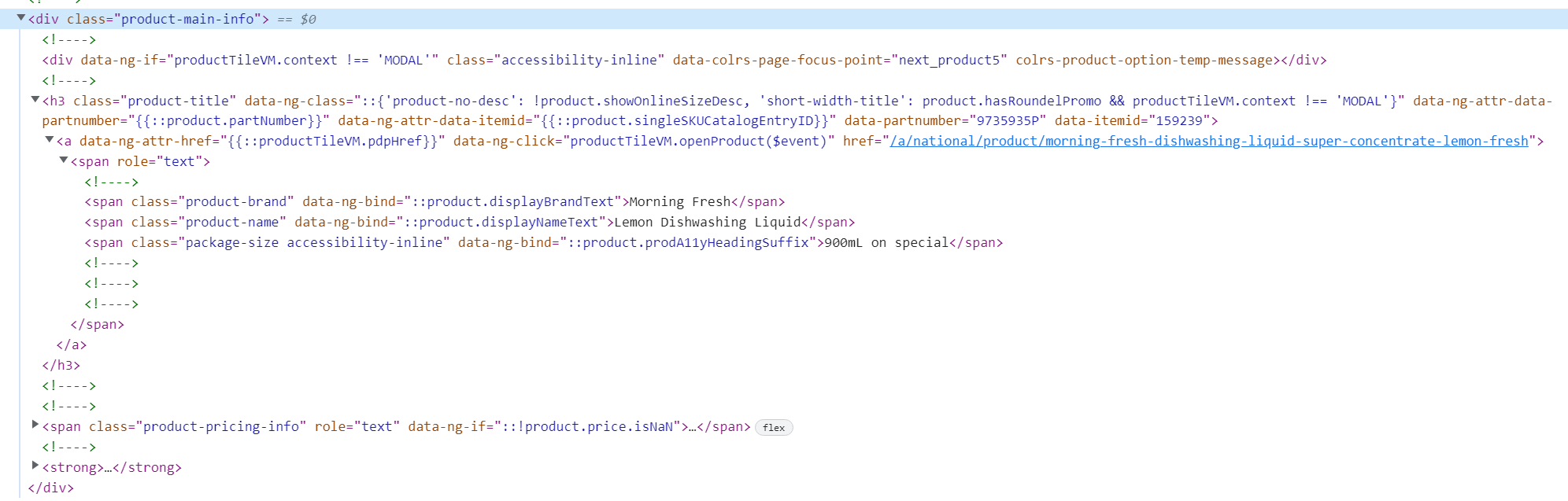
And here are my codes
coles <- "Browse our products to order your next shop | Coles"
productlink <- read_html(coles) %>%
html_elements(".product-main-info > a") %>%
html_attr("href") %>%
url_absolute(url) %>%
as_data_frame()
If anyone has insights into why it doesn't work, I'd much appreciate it.
Cheers,
Polly