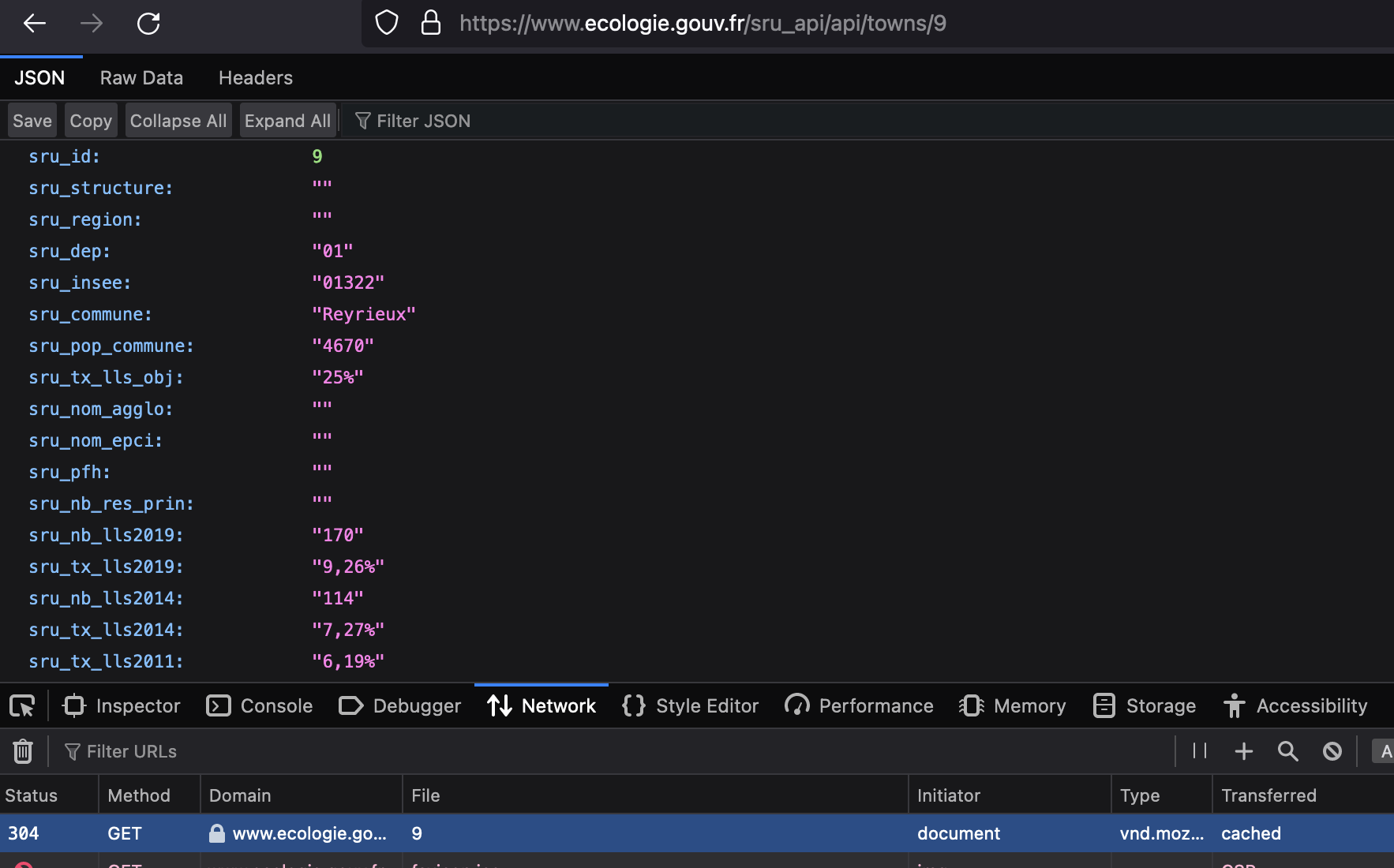
Hello,
I would like to get the name of the town as depicted in the capture below on the webpage
https://www.ecologie.gouv.fr/sru/?id=2
Thanks.
Hello,
I would like to get the name of the town as depicted in the capture below on the webpage
https://www.ecologie.gouv.fr/sru/?id=2
Thanks.
Its a dynamic website, not a static one;
so a headless browser (like chromote) would be needed.
library(rvest)
library(chromote)
# Start a new browser session
b <- ChromoteSession$new()
# Navigate to a webpage
b$Page$navigate("https://www.ecologie.gouv.fr/sru/?id=2")
b$Page$loadEventFired() # important step to let you know the page loaded
# Extract the page's HTML content
html <- b$Runtime$evaluate('document.documentElement.outerHTML')
content <- read_html(html$result$value)
(data <- html_nodes(content, "#titre-commune") %>% html_text())
Thanks, that works indeed but now, I have a problematic of time since I want to do this for 34000 cities.
The instruction b$Page$loadEventFired() takes a lot of time. Any way of improving the loop below ?
for (i in 2:100){
b$Page$navigate(paste("https://www.ecologie.gouv.fr/sru/?id=",i,sep=""))
b$Page$loadEventFired()
html <- b$Runtime$evaluate('document.documentElement.outerHTML')
content <- read_html(html$result$value)
commune =c(commune, html_nodes(content, "#titre-commune") %>% html_text())}
If this website have a public api you should use that, or you could perhaps contact the website about getting their data through other means.
Ok, thanks. I ended with the code below. The function test works pretty well for all values of i from 2 to 33000 (no matter) thanks to you. But when it comes to get all the pages with my loop, I get parsing errors and multiple identical lines in my dataframe. I tried to ignore the problematic lines with tryCatch but it doesn't fix the issue of multiple lines (and skips a lot of data). Can you help me on this ? Thanks.
library(rvest)
library(chromote)
library(jsonlite)
library(dplyr)
test=function(i){
b <- ChromoteSession$new()
p=b$Page$loadEventFired(wait_ = FALSE)
b$Page$navigate(paste("https://www.ecologie.gouv.fr/sru_api/api/towns/",i,sep=""),wait_ = FALSE)
b$wait_for(p)
html <- b$Runtime$evaluate('document.documentElement.outerHTML')
content <- read_html(html$result$value)
data_json=html_text(content)
df=fromJSON(data_json)
return(df)}
ma_liste <- list()
n=100
for (i in 2:n){
tryCatch({
ma_liste <- c(ma_liste, list(test(i)))
})
}
ma_liste
dataframe <- do.call(rbind, ma_liste)
dataframe <- as.data.frame(dataframe)
Whenever you see a webpage being dynamically generated, it's always a good idea to take a look at the network tab of the browser developer tools to see if you can figure where the data is coming from. In this case, it's https://www.ecologie.gouv.fr/sru_api/api/towns/autocomplete, and you can all the city records in a single step like this:
library(tidyverse)
json <- jsonlite::read_json("https://www.ecologie.gouv.fr/sru_api/api/towns/autocomplete")
tibble(json = json) %>%
unnest_longer(json) %>%
unnest_wider(json)
#> # A tibble: 35,366 × 2
#> id label
#> <int> <chr>
#> 1 2 Beynost (01)
#> 2 3 Dagneux (01)
#> 3 4 Ferney-Voltaire (01)
#> 4 5 Miribel (01)
#> 5 6 Montluel (01)
#> 6 7 Ornex (01)
#> 7 8 Prévessin-Moëns (01)
#> 8 9 Reyrieux (01)
#> 9 10 Saint-Denis-lès-Bourg (01)
#> 10 11 Saint-Genis-Pouilly (01)
#> # ℹ 35,356 more rows
Created on 2024-02-10 with reprex v2.0.2.9000
(There are almost certainly more efficient ways to do this transformation but this seemed plenty fast and was what immediately came to mind)
Ok thanks but two remarks :
What would you like to see differently compared to the data frame in my example?
I'd be happy to help you find the other data that you are looking for, but perhaps you could just explain what it is?
My initial post isn't clear enough ? Here is the kind of data I want for town with id=2 for instance:
https://www.ecologie.gouv.fr/sru_api/api/towns/2
But this is just for one town ! You managed to find a webpage where you have all the towns and id's but you don't have all the data related to each town ! What I want is a dataframe with one line per town with all these variables. I can easily get all these data for one town but when I'm looping for all towns, I get parsing errors and what's more, it's very slow.
The result should look like this :
# A tibble: 69 × 46
sru_id sru_structure sru_region sru_dep sru_insee sru_commune sru_pop_commune
<int> <chr> <chr> <chr> <chr> <chr> <chr>
1 2 "" "" 01 01043 Beynost 4557
2 3 "" "" 01 01142 Dagneux 4706
3 4 "" "" 01 01160 Ferney-Voltaire 9637
4 5 "" "" 01 01249 Miribel 9742
5 6 "" "" 01 01262 Montluel 7005
6 7 "" "" 01 01281 Ornex 4400
7 8 "" "" 01 01313 Prévessin-Moëns 7991
8 9 "" "" 01 01322 Reyrieux 4670
9 11 "" "" 01 01354 Saint-Genis-Pouilly 11892
10 12 "" "" 01 01419 Thoiry 6094
# ℹ 59 more rows
Hi,
Just wanted to chime in and suggest writing a script that gathers all the data you want and stores it into files on your machine. That is, download https://www.ecologie.gouv.fr/sru_api/api/towns/2 to a file like temp/2.json and loop through the rest of the id's similarly. Then you can separate out the problem id's and do some inspection a little faster I would think.
Get one or two working in a dataframe the way you want, then try to expand!
Your initial post talked about scraping a dynamic site. You now have a link to a JSON end point that you could load directly with jsonlite. Here's some code to get you started
library(tidyverse)
base_url <- "https://www.ecologie.gouv.fr/sru_api/api/towns/"
urls <- paste0(base_url, 2:10)
json <- purrr::map(urls, \(url) jsonlite::read_json(url), .progress = TRUE)
#> ■■■■■■■■■■■■■■ 44% | ETA: 3s
#> ■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 89% | ETA: 1s
tibble(json = json) %>%
unnest_wider(json)
#> # A tibble: 9 × 46
#> sru_id sru_structure sru_region sru_dep sru_insee sru_commune sru_pop_commune
#> <int> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 2 "" "" 01 01043 Beynost 4557
#> 2 3 "" "" 01 01142 Dagneux 4706
#> 3 4 "" "" 01 01160 Ferney-Volt… 9637
#> 4 5 "" "" 01 01249 Miribel 9742
#> 5 6 "" "" 01 01262 Montluel 7005
#> 6 7 "" "" 01 01281 Ornex 4400
#> 7 8 "" "" 01 01313 Prévessin-M… 7991
#> 8 9 "" "" 01 01322 Reyrieux 4670
#> 9 10 "" "" 01 01344 Saint-Denis… 5667
#> # ℹ 39 more variables: sru_tx_lls_obj <chr>, sru_nom_agglo <chr>,
#> # sru_nom_epci <chr>, sru_pfh <chr>, sru_nb_res_prin <chr>,
#> # sru_nb_lls2019 <chr>, sru_tx_lls2019 <chr>, sru_nb_lls2014 <chr>,
#> # sru_tx_lls2014 <chr>, sru_tx_lls2011 <chr>, sru_tx_lls2008 <chr>,
#> # sru_tx_lls2005 <chr>, sru_tx_lls2002 <chr>, sru_exo <chr>,
#> # sru_prel_brut <chr>, sru_maj_brut <chr>, sru_prel_brut_tot <chr>,
#> # sru_constat_car <chr>, sru_date_arrete <chr>, sru_tx_maj_prel_brut <chr>, …
Created on 2024-02-12 with reprex v2.0.2.9000
You will have considerably less problems with errors by loading the JSON directly, but if you do still have problems, I'd suggest following @joesho112358 and first writing a separate loop to download each json file first, before parsing them.
Still some errors and missing rows but thanks. I will try at first to save all the json pages in my own files and then deal with it without requiring internet.
n=100
base_url <- "https://www.ecologie.gouv.fr/sru_api/api/towns/"
urls <- paste0(base_url, 2:n)
read_json_safe <- possibly(jsonlite::read_json, otherwise = NULL)
json <- purrr::map(urls, read_json_safe, .progress = TRUE)
json <- Filter(Negate(is.null), json)
df <- bind_rows(json)
Error in `map()`:
ℹ In index: 9.
Caused by error in `open.connection()`:
! impossible d'ouvrir la connexion vers 'https://www.ecologie.gouv.fr/sru_api/api/towns/10'
Run `rlang::last_trace()` to see where the error occurred.
Message d'avis :
Dans open.connection(con, "rb") :
URL 'https://www.ecologie.gouv.fr/sru_api/api/towns/10': statut 'Failure when receiving data from the peer
With a GET request, I also have connection issues :
base_url <- "https://www.ecologie.gouv.fr/sru_api/api/towns/"
get_data <- function(url) {
response <- tryCatch(
curl_fetch_memory(url),
error = function(e) {
message("Erreur lors de la requête HTTP :", conditionMessage(e))
return(NULL)
}
)
return(response)
}
all_data <- list()
for (i in 2:10) {
url <- paste0(base_url, i)
response <- get_data(url)
if (!is.null(response) && response$status_code == 200) {
content <- rawToChar(response$content)
json_data <- jsonlite::fromJSON(content)
all_data[[i]] <- json_data
} else {
cat("Erreur lors de la requête HTTP pour la page", i, "\n")
}
}
df <- do.call(rbind, all_data)
print(df)
Erreur lors de la requête HTTP :Failure when receiving data from the peer
Erreur lors de la requête HTTP pour la page 5
Erreur lors de la requête HTTP :Failure when receiving data from the peer
Erreur lors de la requête HTTP pour la page 6
Erreur lors de la requête HTTP :Failure when receiving data from the peer
Erreur lors de la requête HTTP pour la page 7
Erreur lors de la requête HTTP :Failure when receiving data from the peer
Erreur lors de la requête HTTP pour la page 9
Erreur lors de la requête HTTP :Failure when receiving data from the peer
Erreur lors de la requête HTTP pour la page 10
Looks like you might need to remove && response$status_code == 200 from the check because it is responding with a 304 for me, but the data is there:
Ok, but the problem persist on my own computer. Since the connection was the problem, I demanded that the loop tries again for every failed iteration with trycatch and it works fine for me. I conclude that my problem is my proxy/firewall or something independent from the code you will all be able to provide me with. Now remains the problem of the speed of execution but that is less of a matter to me.
library(rvest)
library(chromote)
library(jsonlite)
library(dplyr)
library(progress)
test <- function(i) {
b <- ChromoteSession$new()
p <- b$Page$loadEventFired(wait_ = FALSE)
b$Page$navigate(paste("https://www.ecologie.gouv.fr/sru_api/api/towns/", i, sep = ""), wait_ = FALSE)
b$wait_for(p)
html <- b$Runtime$evaluate('document.documentElement.outerHTML')
content <- read_html(html$result$value)
data_json <- html_text(content)
df <- fromJSON(data_json)
b$close()
return(df)
}
start.time <- Sys.time()
ma_liste <- list()
n <- 100
pb <- progress_bar$new(total = n)
for (i in 2:n) {
pb$tick()
retry <- TRUE
while (retry) {
tryCatch({
ma_liste <- c(ma_liste, list(test(i)))
retry <- FALSE # Pas d'erreur, donc pas besoin de réessayer
}, error = function(e) {
message("", i, ": ", conditionMessage(e))
Sys.sleep(0.001) # Attendre un certain temps avant de réessayer
})
}
}
dataframe <- do.call(rbind, ma_liste)
dataframe <- as.data.frame(dataframe)
end.time <- Sys.time()
time.taken <- round(end.time - start.time,2)
time.taken
And the speed problem is fixed. I had forgotten to close each webpage after extraction of the data. Hence, my memory was full and the program was running slower and slower with all these googlechrome webpages opened. I just added b$close() and now, I have 4 iterations per second which is fine for me. I will try all your solutions later with that "trycatch" trick to see what is the fastest code. Thanks again.
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.
If you have a query related to it or one of the replies, start a new topic and refer back with a link.