Hi, I've gone through your code and made some notes below. Hope this is useful!
Generating URLs
There is a slightly quicker way of generating your URLs. To create a vector of consecutive numbers you can write <start>:<finish> instead of using seq(). I.e. 1:33 is equivalent to seq(from = 1, to = 33, by = 1). Also, paste0() automatically converts its input to character so you don't need to worry about that.
UK_MP_urls <- paste0("https://members.parliament.uk/members/Commons?page=", 1:33)
Function missing a return value
Your UK_MP_function() didn't have either an implicit or explicit return anywhere, so I changed that:
UK_MP_function <- function(x) {
MPstage_1 <- read_html(x)
MPstage_2 <- html_nodes(MPstage_1, "div.primary-info")
MPstage_3 <- html_text(MPstage_2)
return(MPstage_3)
}
sapply() vs lapply()
This line of code
unlist(sapply(UK_MP_URLs, UK_MP_function))
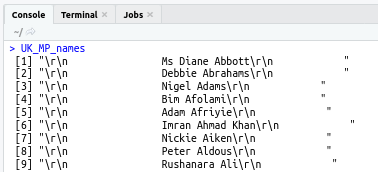
confused me a bit. The call to sapply() actually returns a matrix, not a list, so unlist() doesn't do anything here. I think you want lapply(), which returns a list. In this case it's a list of character vectors. The unlist() function then does what I think you intended and gives you a single long character vector.
UK_MP_names <- unlist(lapply(UK_MP_URLs, UK_MP_function))
Regex
Now to get to the main part of your question about regex. I used this:
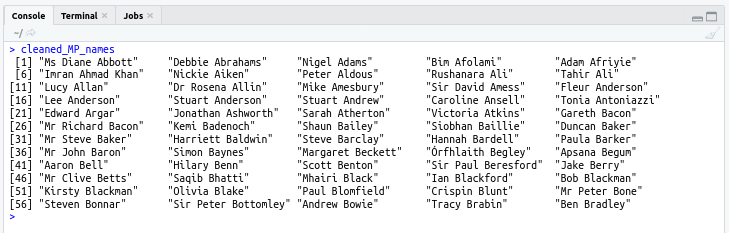
cleaned_MP_names <- stringr::str_extract(UK_MP_names, "([:alpha:]+ ?)+")
Which gets us this:
To break down what the regex is doing:
[:alpha:] matches any upper or lower-case letters. The + sign means "one or more of those", so "[:alpha:]+" will match (for example) the "Ms", "Diane" and "Abbott" in "Ms Diane Abbott".
Then we have a space followed by "?". The space matches a literal space, and the "?" means "zero or one of these". So "[:alpha:]+ ?" means "one or more letters, which may or may not be followed by a space". "[:alpha:]+ ?" matches "Ms ", "Diane " and "Abbott" (note the spaces after words are now matched).
Finally we wrap that whole thing in parentheses to form a group, and stick a "+" on the end again to say "one or more of these groups", giving the final regex "([:alpha:]+ ?)+". Verbally the regex is saying "find me one or more groups of letters that may or may not be followed by a space". The expression returns the longest matching string, i.e. the whole name.
If you've not seen regexr.com I'd recommend it, it's very handy. There's also an RStudio Cheatsheet on stringr and regex in R.
Hope this is useful - the complete script is below 
library(rvest)
UK_MP_urls <- paste0("https://members.parliament.uk/members/Commons?page=", 1:33)
UK_MP_function <- function(x) {
MPstage_1 <- read_html(x)
MPstage_2 <- html_nodes(MPstage_1, "div.primary-info")
MPstage_3 <- html_text(MPstage_2)
return(MPstage_3)
}
UK_MP_names <- unlist(lapply(UK_MP_urls, UK_MP_function))
cleaned_MP_names <- stringr::str_extract(UK_MP_names, "([:alpha:]+ ?)+")