I have been chasing an odd behaviour in a chapter of a bookdown book. The book used to build fine but suddenly I started getting an error at my select statement in a dplyr pipe chain: error in select... unused arguments... Well I know that error. We're old friends. That's what I get if I use select from dplyr with the MASS package loaded. I have no idea why MASS is loaded at that point in the book, but I'm pragmatic so just trying to build the dang thing. So I add a code block to unload MASS:
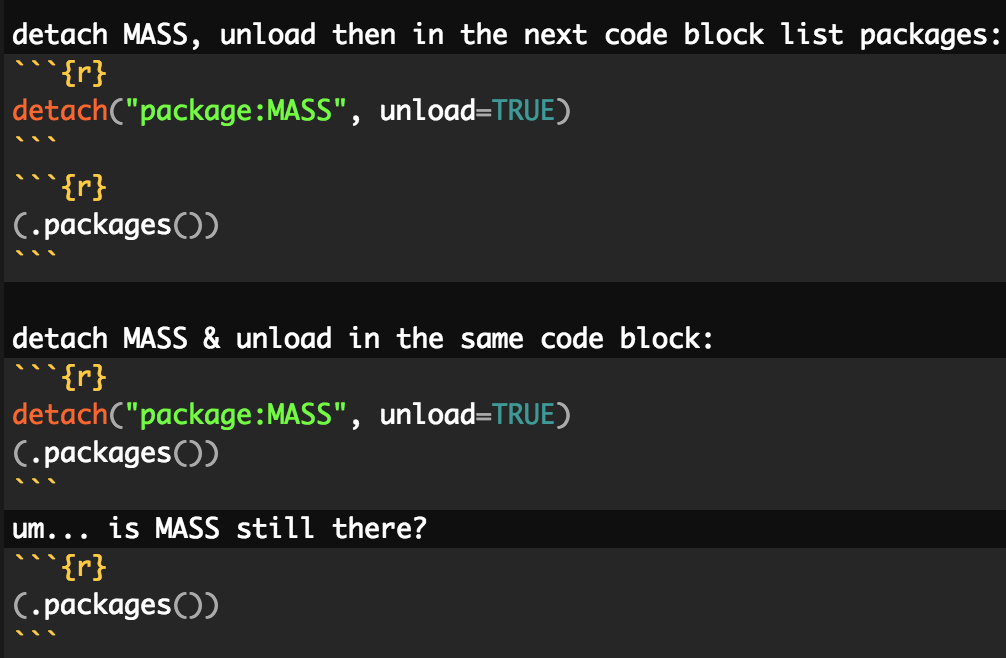
detach("package:MASS", unload=TRUE)
and I was shocked to discover I kept getting the same error. So I set up a little test case to see if unloading in the same code block matters. And it DID... but it shouldn't (I don't believe). And then after unloading, in the next cell block MASS is back like a bad penny!:
Here's the test I set up right in the middle of my book chapter. I'm doing screen shot because I can't get the tics to show right in this forum:
The output below shows that when I unload MASS in its own code block, the package is still very much loaded in the next code block. However if I unload in the same code block, then it's unloaded for that code block. But in the following code block it's back!!
Oddly enough, when I try to reprex this in a single page R Markdown document the behavior is as expected. It's only in my book where the behavior is borked. I have reproduced this on my Macbook Pro as well as Rstudio.server Linux. Here's the rstudio.server session info:
The problem I have is that I'm trying to write a document illustrating package loading and unloading and the surprise impacts of name clashes. The irony is palpable.
I can find nothing that loads MASS... however, MASS is explicitly loaded later in Ch 2. Watching the build scripts scroll past my bloodshot eyes it kind of looks like building the chapter results in the chapter being parsed twice. Is it possible that bookdown makes a pass over the chapter, loads MASS later in the chapter then makes a second pass without restarting the R session? I don't know why it would work this way, but it would explain why I see stuff scroll past on the build script twice sometimes... or at least think I do.
so I commented out the section that loaded MASS later in chapter 2. MASS still loaded. So there goes my "two pass theory" totally debunked. I have no idea what computers are or how they work. I'm considering a career change to blacksmithing.
How sure are you about the order of render? I guess I'm asking if you list the files in _bookdown.yml or let bookdown figure it out. Then again, I'm not entirely sure if the order in _bookdown.yml controls the order of render or just the order or presentation. Maybe @yihui can jump in and clear this all up.
What I don't understand ... if each file is truly being rendered in a fresh R session, why is there so much stuff in "other attached packages" and "loaded via a namespace" in a the first chunk? It should basically be a blank slate, yes?
Yeah, that's my thought as well. Somehow I'm pretty sure I'm not getting a blank slate for each chapter. But, oddly, I can't reproduce it in a simplified example when makes me think there's something in my project that's causing this behavior.
Is this book publicly accessible anywhere? I need to look at its source (I'm surprised that the reprex author hasn't asked for a reprex so far ).
BTW, I'm shocked that even an advanced R user like you doesn't know the rule of N+1 backticks when posting literal Rmd examples and had to use screenshots, which is something I remind Github users almost on a daily basis (https://yihui.name/en/2017/05/four-backticks-github/) because almost every single day, I see Github issues incorrectly formatted like this: https://github.com/rstudio/rmarkdown/issues/1464 (I even mentioned it in the issue template but few users seem to have understood or respected it).
As the self-appointed local avatar of n + 1 backtick enlightenment, I can confirm that since the original post was made, @jdlong has been advised on this point and now knows the true path. And for anybody else, it’s in our FAQ!
Great. Thanks! In the rare case of an Rmd example containing four backticks, you'll need at least five backticks to show the four backticks, i.e. if you need to show N backticks verbatim, use N+1 or more backticks outside. I just want to make it super clear that four means "three plus one", and it could be five, six, or bigger numbers depending on the content you want to display...
Trust me, I've tried to reprex. But when I make simple examples they all work as expected. Which, as best as I can tell, means my problem doesn't really exist
I shared the book with you via email from rstudio.cloud. If the past is my guide then I am sure you will discover that a missing semicolon or an extra space somewhere is the culprit.
Thanks to some serious hand-holding from @yihui, we discovered that in a few places I had, indeed, turned knitr caching on. The caching was causing MASS to load. I was able to fix this by commenting out the cache = TRUE statement in my knitr ops statement:
When knitr's caching is turned on, the packages loaded in the R session will be saved during knitting. The next time the document is compiled, these packages will be reloaded. This was a conservative strategy introduced in a very early version of knitr (perhaps in 2012). The reason was to prevent problems when users cache code chunks that load packages (e.g. via library()). They really shouldn't load packages in cached code chunks because cached chunks won't be executed in future (consequently, packages won't be loaded). In retrospect, this was a bad design decision in knitr. I should have just let them fail in this case, instead of reloading packages automatically.
I'm no computer scientist, but they let me hang out with them sometimes... My understanding from listening to them talk is that the three hardest problems in CS are:



 ).
).