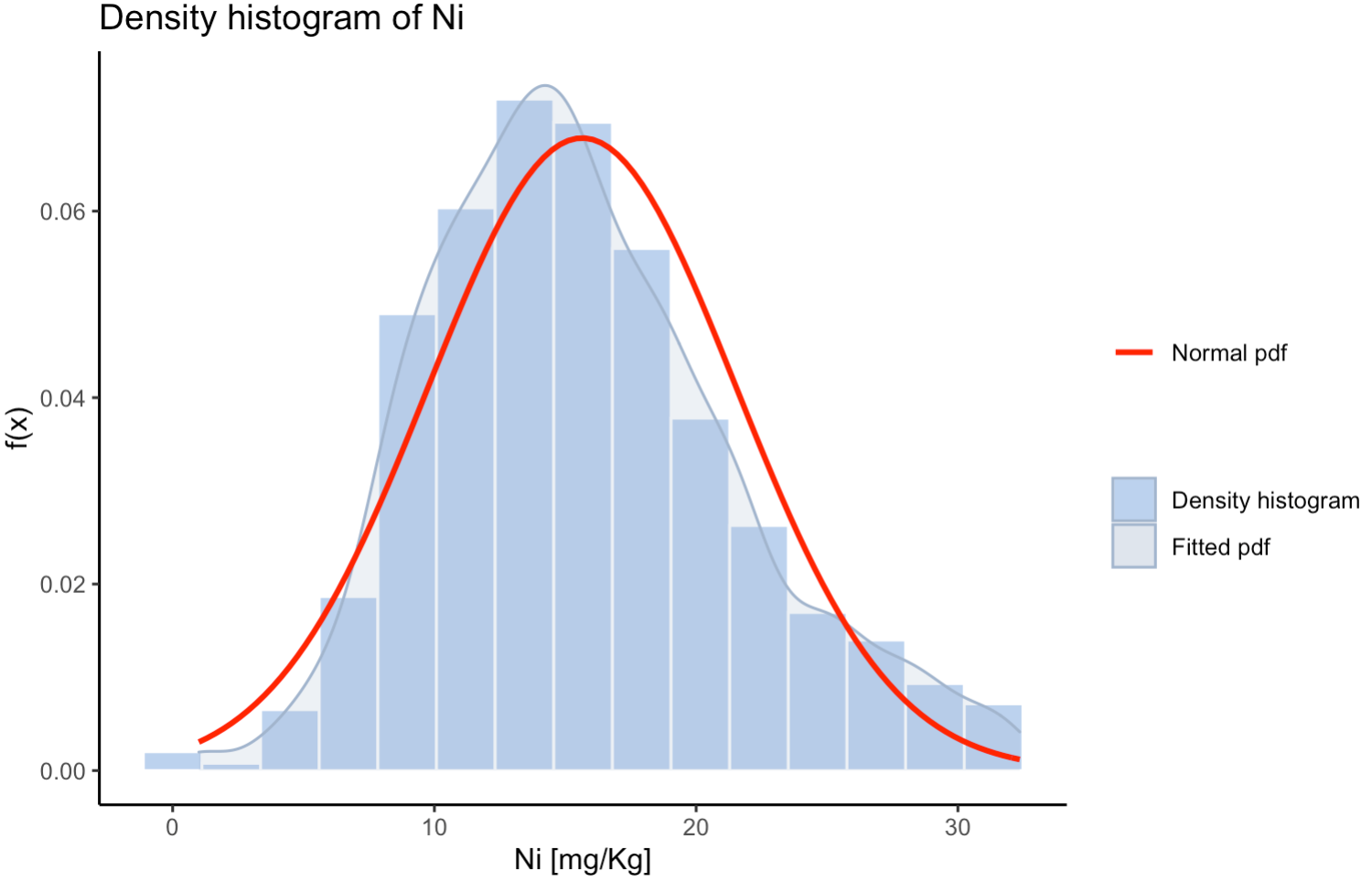
I'm currently working on a data set of heavy metals and I need to perform some transformation in order to make the data normal (follow a normal distribution). You can see here the distribution of the Ni data after deleting some outliers :
I'm guessing your sample size is relatively large, i.e. >50 ? link
The Shapiro–Wilk test is more appropriate method for small sample sizes ( <50 samples ) although it can also be handling on larger sample size while Kolmogorov–Smirnov test is used for n ≥50.
Exactly, ~3000 obs.
So I tried with a Kolmogorov–Smirnov test and even with a Lilliefors test, but result are still not even close from a normal distribution ... I don't know what to think.
I made a few tests with ks.test() function. For remind, Cdbx.Nii is my transformed Nickel data, so it is almost normal, with this distribution:
On histograms it is very hard to see small deviations from normality. It is much easier to use a Q-Q plot (with qqnorm() and qqline()), which makes it more obvious where the data is non-normal.
As for statistical tests, their power directly depends on the sample size, so with a huge sample like yours any slight deviation from normality will make the p-value ridiculously small.
Remember: the p-value is not a measure of how important an effect is, just of whether random noise could cause it; so with a big enough sample size any irrelevantly small effect will bring your p-value to basically 0.
Which brings me to the real point: you almost never need a normality test. This rant explains it better than than I can, and gives a paper to cite.
If the conditions of the CLT are met, your sample data will be approximately distributed. But not exactly (since the population has no reason to be normal), so a big enough sample size will give a small p-value. If you had a very small sample size and something very non-normal, a normality test would fail to reject the null (because too small sample size), and mislead you to conclude your data is normal. Normality tests are almost never relevant, the only difficulty is to convince the reviewers of that fact.