Hello everyone. I am new to data scrapping, trying to figure out how to scrape the results of a google search is the news section. My example website is on Silvio Berlusconi. I've been using Chrome developer tools and SelectorGadget as assistance tools.
I have tried this approach:
First, using the selector for the headline as in the following image:
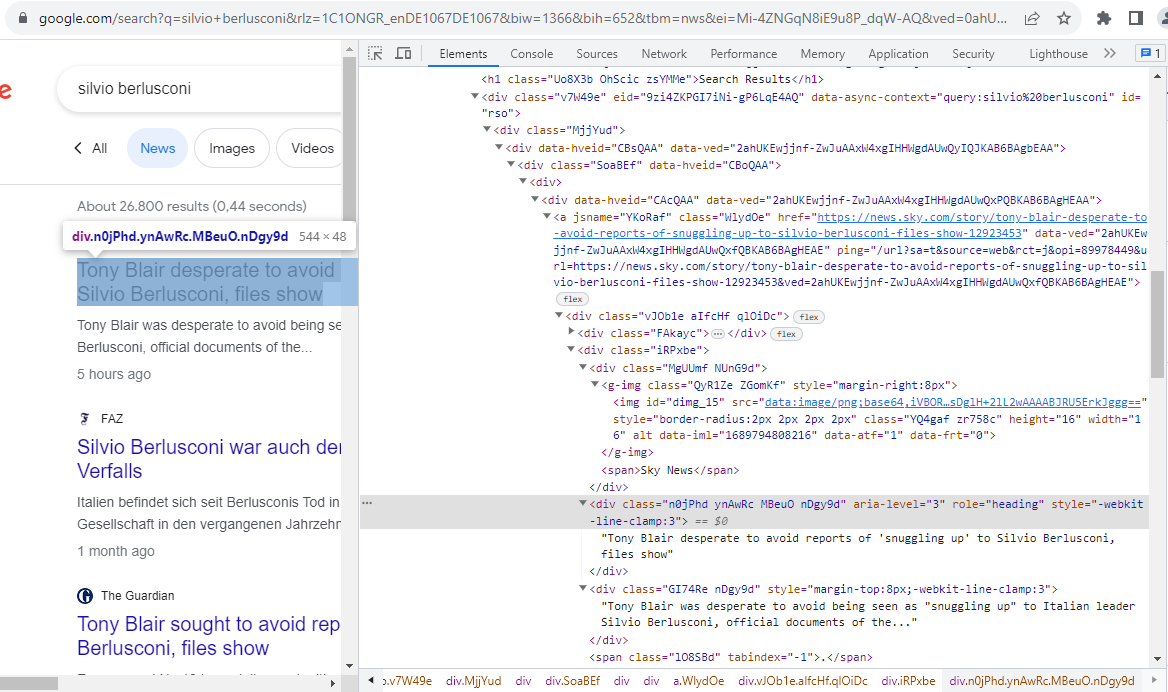
Then, applying the code as follows:
rm(list=ls())
set.seed(1234)
options(scipen=10000)
select <- dplyr::select
# loading the packages:
library(dplyr) # for pipes and the data_frame function
library(rvest) # webscraping
# extracting the whole website
google <- read_html("https://www.google.com/search?q=silvio+berlusconi&rlz=1C1ONGR_enDE1067DE1067&biw=1366&bih=652&tbm=nws&ei=Mi-4ZNGqN8iE9u8P_dqW-AQ&ved=0ahUKEwjRi8rxtpuAAxVIgv0HHX2tBU8Q4dUDCA0&oq=silvio+berlusconi&gs_lp=Egxnd3Mtd2l6LW5ld3MiEXNpbHZpbyBiZXJsdXNjb25pMgoQABiKBRixAxhDMgcQABiKBRhDMgcQABiKBRhDMgUQABiABDIFEAAYgAQyBRAAGIAEMgUQABiABDIFEAAYgAQyBRAAGIAEMgUQABiABEj3BlAAWABwAHgAkAEAmAFFoAFFqgEBMbgBDMgBAIgGAQ&sclient=gws-wiz-news")
# extracting the headlines
headlines <- google %>%
html_nodes("div.n0jPhd.ynAwRc.MBeuO.nDgy9d") %>%
html_text()
headlines
character(0)
So my question is, why is the output character 0? And how can I fix it?
I have tried with alternative combinations, such as only using each of the div names, or
# extracting the headlines
headlines <- google %>%
html_nodes("div.n0jPhd") %>%
html_nodes("div.ynAwRc") %>%
html_nodes("div.MBeuO") %>%
html_nodes("div.nDgy9d") %>%
html_text()
View(headlines)
, but the output has remained the same.
What am I missing?
Thank you in advance for any guidance, it will be very much appreciated. I