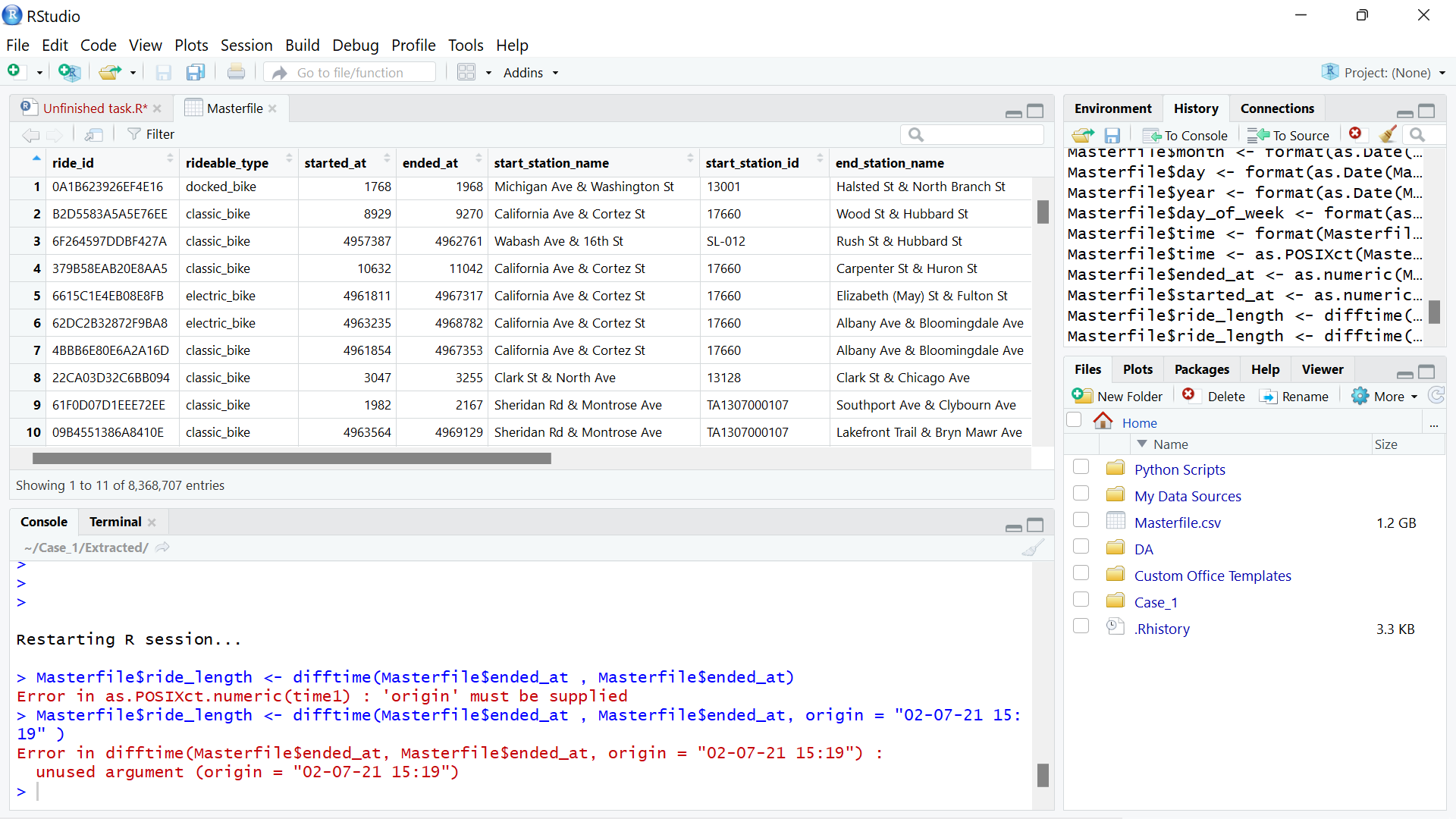
Currently I'm working on Divvy dataset Google capstone project. I am a novice in this field.
This Dataset contains data about the ride. I have combined 12 files of previous year to make a huge dataset.
Masterfile <- read.csv('Masterfile.csv')
I'm struggling to form a new column 'ride_length' which i can get by subtracting data of column "Started_at" and "Ended_it".
These columns contains date "02-07-21 14:44" and "02-07-21 15:19" in this format.
I even converted both the columns in Numeric.
This will only be the case if all start/end pairs are within the same day since the actual date is not being parsed (the dates are being parsed as %y%m%d), I think this is a dangerous approach since it can lead to unexpected results, for example:
difftime('02-08-21 00:19', '02-07-21 23:44')
#> Time difference of 30.02431 days
I think it is better to properly parse the character strings into date-time objects respecting the actual date format they are in (I'm assuming "%m-%d-%y).
library(dplyr)
d = data.frame(Started_at = c('02-07-21 14:44', '02-07-21 23:44'),
Ended_at = c('02-07-21 15:19', '02-08-21 00:19'))
d %>%
mutate(across(c(Started_at, Ended_at), as.POSIXct, format = "%m-%d-%y %H:%M"),
ride_length = difftime(Ended_at, Started_at))
#> Started_at Ended_at ride_length
#> 1 2021-02-07 14:44:00 2021-02-07 15:19:00 35 mins
#> 2 2021-02-07 23:44:00 2021-02-08 00:19:00 35 mins