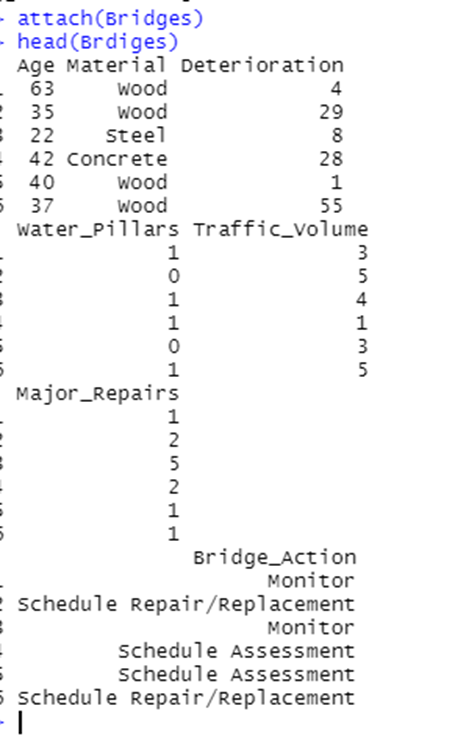
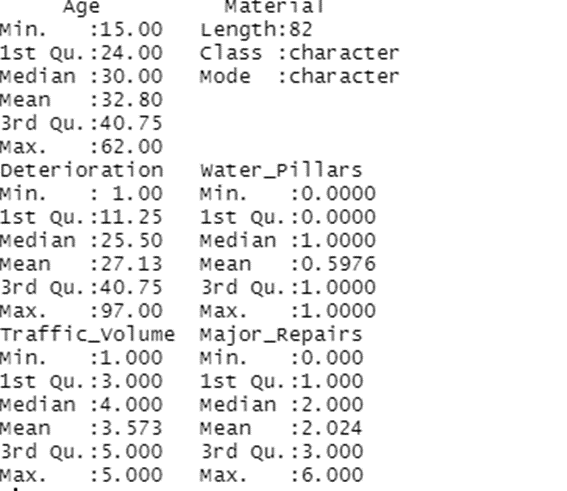
There are a few typos, but I corrected them in the next lines of code. I am in the Desktop WD, and my file names used in RStudio are correct - the typo on Bridges in one line, that I fixed.
You are making a lot of syntax errors, it seems you are copy pasting code from text and you are either not copying the complete command (missing closing parentheses) or copying too much (you should not start a command with call:)
The last error message you show implies you do not have a dataframe called Brigdes loaded into your current working environment.
As I said, if you need help with your specific code, please post a proper reproducible example (as explained on the link I gave you before).
And as a personal advice, you should not start looking for help asumming you have done everything right so far, be open to the possibility that you have made a mistake on previous steps or that you are lacking understanding of the subject.
I never assumed, stated, or implied I did everything right. I asked for assistance. I explained my reasoning and shared my code. I have received superb help in the past here in the discussion forums.
I do have a data frame Bridges and a Condition_Unknown as well, but if I am doing something wrong here I would love to know what; perhaps the way I am importing the two csvs?
If you do not want to help me, then that's fine; someome else will help me eventually.
I was referring to this. If you had imported the files correctly and you had a dataframe called Bridges imported into memory, then you would not be getting the last error message you have shown. So my point is, do not assume your previous step is correct and check again.
I'm not refusing to help you, you have some problem with your previous code but I can't see it because you are not showing it so I can only guess and try to make you figure it out by your own. I'm asking you for a reproducible example because that is the most effective (and polite) way of asking for coding related help, if we can reproduce your problem, then we can tell you exactly how to solve it, without guessing. I know it seems daunting at first but let me assure you that learning how to properly ask for help (with a reprex) will vastly payoff.
I'm sorry you fill that way, it is certainly not my intention, I'm only trying to provide honest advice for you to catch up with the coding language and the community good practices in general. Maybe you fill it that way because I'm not a native English speaker and in my head (maybe translated into Spanish) this doesn't sound rude or condescending.
lda(Bridge_Action ~ Age + Matrial +Deterioration + Water_Pillars + Traffic_Volume + Major_Repairs, data = Bridges)
Error in eval(predvars, data, env) : object 'Bridge_Action' not found
Here are my two imported files:
As you can see I do have the .csv files imported into my data frame and you can see my one Independent Variable and the various Dependent Variables
Now when I do code as below, the program will not run:
If you read the Bridges.csv file without header (header = FALSE) then the columns in the resulting Bridges dataframe are going to have generic column names rather than the ones on the original csv file. Unless you are renaming the columns with an additional step you are not showing, that is likely to be the cause of your problem.
Here you are showing a typo, the file you are showing is called ConditionUnknown.csv not ConditionsUnknown.csv and if you read it without header, you are likely to fall into the same issue as before.
I think you haven't understood what I was saying to you before, let me try again. Consider this example:
library(dplyr)
# Here I'm generating an analogous sample csv file from a built-in data set
# just to have something to work with
write.csv(iris, "sample.csv")
# Here I'm reading the csv file generated on the previous step, without considering
# headers, just like you did in your code.
sample_df <- read.csv("sample.csv", header = F)
# Now, notice how the column names are just generic names i.e. V1, V2, V3, ... etc
# And the actual column names are on the first row
head(sample_df)
#> V1 V2 V3 V4 V5 V6
#> 1 NA Sepal.Length Sepal.Width Petal.Length Petal.Width Species
#> 2 1 5.1 3.5 1.4 0.2 setosa
#> 3 2 4.9 3 1.4 0.2 setosa
#> 4 3 4.7 3.2 1.3 0.2 setosa
#> 5 4 4.6 3.1 1.5 0.2 setosa
#> 6 5 5 3.6 1.4 0.2 setosa
# If I try to select the last column by using the name `Species`, the code
# fails, because by reading without headers, that column got the generic `V6` name assigned
sample_df %>%
select(Species) %>%
head()
#> Error in `select()`:
#> ! Can't subset columns that don't exist.
#> ✖ Column `Species` doesn't exist.
# Now, if I read the csv file including headers, I get proper column names and
# the previous code doesn't fail
sample_df <- read.csv("sample.csv", header = T)
head(sample_df)
#> X Sepal.Length Sepal.Width Petal.Length Petal.Width Species
#> 1 1 5.1 3.5 1.4 0.2 setosa
#> 2 2 4.9 3.0 1.4 0.2 setosa
#> 3 3 4.7 3.2 1.3 0.2 setosa
#> 4 4 4.6 3.1 1.5 0.2 setosa
#> 5 5 5.0 3.6 1.4 0.2 setosa
#> 6 6 5.4 3.9 1.7 0.4 setosa
sample_df %>%
select(Species) %>%
head()
#> Species
#> 1 setosa
#> 2 setosa
#> 3 setosa
#> 4 setosa
#> 5 setosa
#> 6 setosa
That is exactly what I'm talking about, your column names are V1, V2, V3, etc, and the actual column names are stored as data on the first row of your data frame, that is why you can't reference them by name. Set headers as TRUE in your code to read the file properly
OK, now that you have the data frame properly read into your working environment, your previous code should work out of the box. Have in mind that since you are specifying the data argument inside the lda() function, it is actually not necessary to attach() the dataset, so your code should look like this:
library(MASS)
# Read the csv file
Bridges <- read.csv("Bridges.csv", header = TRUE)
# Train the model and store it on a variable
model <- lda(Bridge_Action ~ Age + Matrial + Deterioration + Water_Pillars + Traffic_Volume + Major_Repairs, data = Bridges)
# Inspect the model
summary(model)
Here is an example using a built-in data set just to prove it works
library(MASS)
model <- lda(Species ~ Sepal.Width + Petal.Width + Petal.Length + Petal.Width, data = iris)
summary(model)
#> Length Class Mode
#> prior 3 -none- numeric
#> counts 3 -none- numeric
#> means 9 -none- numeric
#> scaling 6 -none- numeric
#> lev 3 -none- character
#> svd 2 -none- numeric
#> N 1 -none- numeric
#> call 3 -none- call
#> terms 3 terms call
#> xlevels 0 -none- list