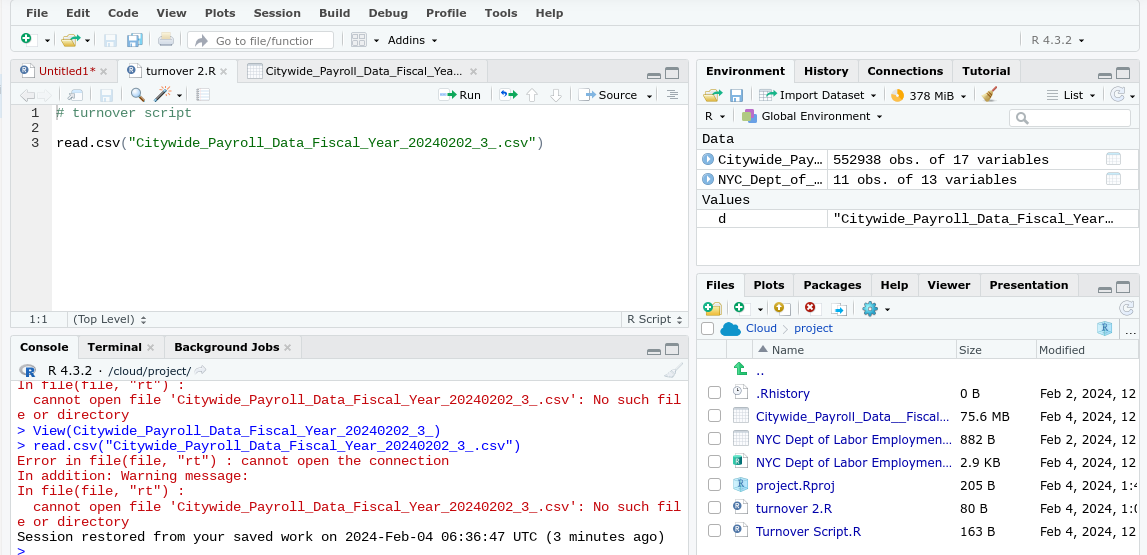
I am following instructions for both a YouTube tutorial and webpage which advises in order to upload csv file onto R, use read.csv. When I use the read.csv(file_name.csv) and run the code the error message I received back is "Error in file (file, "rt"): cannot open the connection
In addition: Warning message:
In file, (file, "rt"): cannot open file " .csv" No such file in directory"
** I tried to import the file using the import function in the Environment pane which was successful. I just don't understand why I am unable to use and reference the dataset in the script to run codes and assign a variables .
The error you are getting means that the read.csv() function cannot find the file you are telling it to open.
When you use the import function in the Environment tab, a command should appear in the console. What is that command and how is it different from your use of read.csv()?
I am a bit confused. When I uploaded the file, the exact dataset appeared and in the script section, as a table in separate tab. The command was view(dataset.csv) with the exact csv file that the error message keeps stating does not exist. I just uploaded a screenshot of my screen. Is there any chance you can make out what is occurring here? & where I am going wrong?
When I use the Import Dataset -> From Text (base) selection in the Environment tab and I choose the day.csv file in my current working directory, I see this in the console
> day <- read.csv("~/R/Play/day.csv")
> View(day)
I'm using the desktop version of RStudio, not the cloud version. Do you not see the read.csv() part of that?
You can run
dir()
in the console and see exactly what files are in your working directory. Do you see exactly the file name you are using in read.csv()?
I am able to assign a variable to the dataset. But moving forward do I need to always put the cloud project name and then the header=FALSE in the parentheses as well to run the code?
would work, but I could easily be wrong. Try it and see.
The header = FALSE part of the command tells R that the first row in the file is not a header row, so the columns will get default names. Whether you should use that or not depends on the structure of your file. It will be imported whether you set that to TRUE or FALSE but your column names and data types will be wrong if you make the wrong choice.
Nope for some reason that does not work here. When I take off the cloud & project, it returns the same error message I previously noted in the R console. But ahh thanks, I was wondering why it included the header portion. In the video I am following, the instructor did not have to write that code for it to run.