Hello everybody,
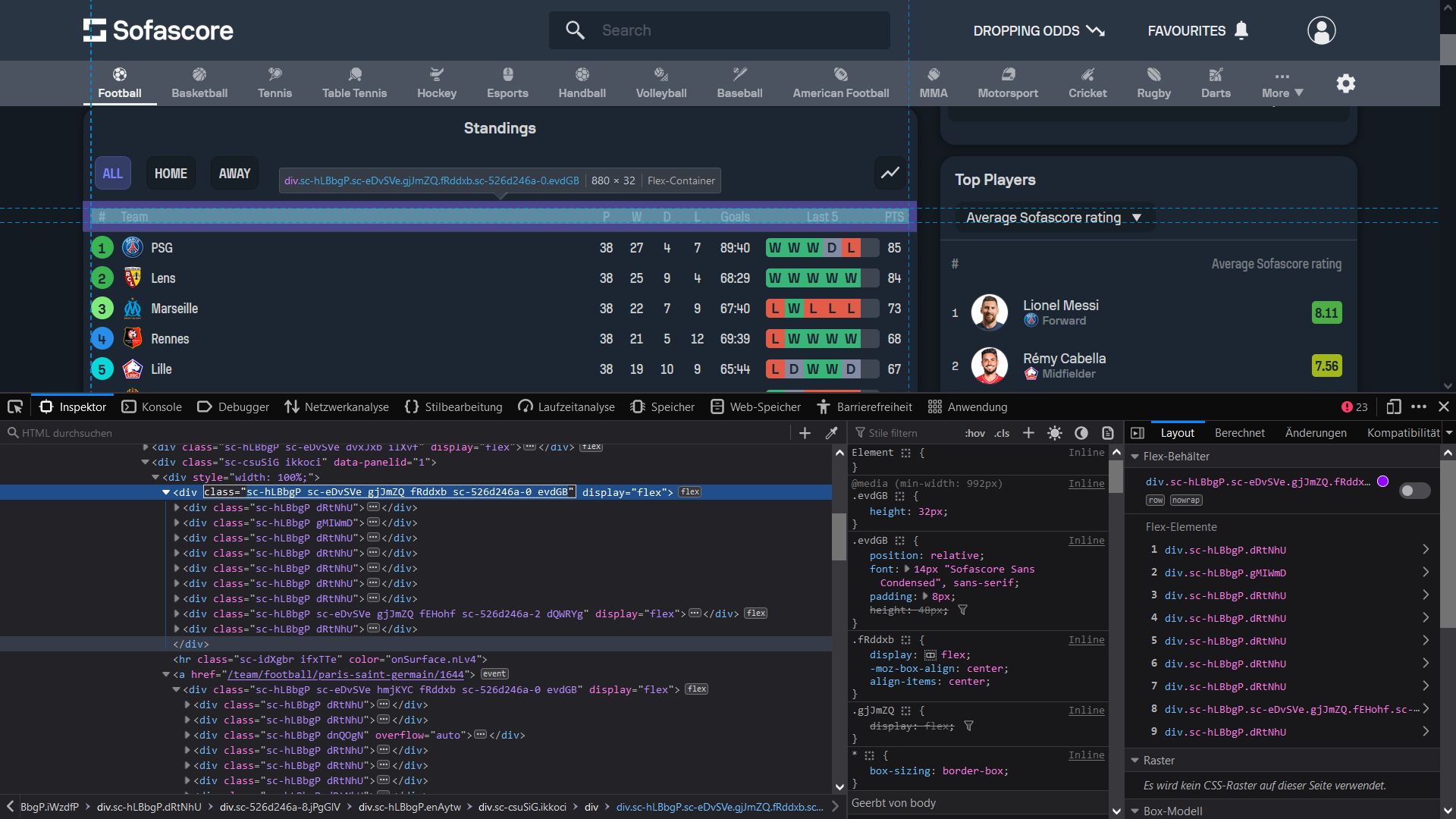
I am trying to scrape data from the following sports statistics page: https://www.sofascore.com/tournament/football/france/ligue-1/34#42273 (Season 22/23)
The table I want to scrape is the "Standings" table using the rvest package. I have come so far that I know that I can read out the contained HTML text based on certain class names. Now I would like to do exactly that on an example site about the french "Ligue 1" on sofascore.com. The <div> class name of the html elements I want to scrape is "sc-hLBbgP sc-eDvSVe gjJmZQ fRddxb sc-526d246a-0 evdGB" (as you can see in the screenshot) and I have tried to specify it in the html_elements() function but it just won't work properly.
My current code:
library(rvest)
URL <- "https://www.sofascore.com/tournament/football/france/ligue-1/34#42273"
HTML <- read_html(URL)
HTML %>%
html_elements("div") %>%
html_elements(".sc-hLBbgP sc-eDvSVe gjJmZQ fRddxb sc-526d246a-0 evdGB")
The result:
{xml_nodeset (0)}
Until the <div> part of the code the HTML code can still be read out but as soon as the class name is entered it ends up in an empty vector. What am I doing wrong that the html_elements() function won't get it hands on the text information in this <div> node?
With best regards
anyway01