I'm fairly new to R so excuse any shortsightedness here.
I have about 57 .xlsx files sitting in the same directory. They all have the same structure and formatting, with some of the cell ranges off by 1 or 2 between files, and I don't want to combine all of the data found in each file, I only want to combine specific cell ranges from each file into a Master Excel file as output later on.
This workflow will be something I spend a lot of time doing every month, so I'd like to write some R code to automate most of the manual work.
I need help figuring out a way to ingest all of the individual Excel files, selecting specific cell ranges based on 4 unique key values (the key values are the same cost codes across all files, but represent 4 different ranges (54, 55, 56, 58) in each file), combining them into a single dataframe, then pivoting from long to wide.
I basically need to isolate these 4 cell ranges and drop the rest of the file's data, then combine and pivot each file's extracted ranges into a wide format where each unique file represents one observation in the new dataframe. A new column that provides the original filename would be great too.
ANY help would be greatly appreciated.
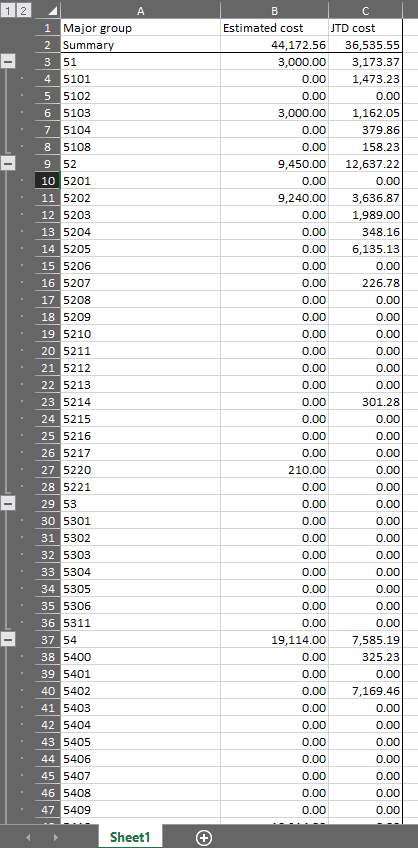
All data is Double. All data is found in 1 sheet. The 4 row ranges I need to keep are rows where the key value is 54, 55, 56 and 58. In every file.
After a day of researching, this is all I've got so far and I just can't make any progress:
# Loads your packages
library(readxl)
library(tidyr)
library(readr)
library(dplyr)
# Sets the file path for your files to be loaded from
setwd(directory)
# Creates a list in RStudio of all of the files for you to check against
my_files <- list.files(pattern = "*.xlsx")
read_excel('filename.xlsx', col_types = "numeric", col_names = TRUE,
range = "A38:C38", "A51:C51", "A75:C75", "A102:C102")
read_excel('filename', sheet =1, col_names = TRUE,
range = "A37:C37", "A50:C50", "A75:C75", "A102:C102")