Hi all,
I have a two-part question/problem:
- I have a fairly large data set that is 100K long and I'm trying to filter out entries based on a general set of character values that I want to keep. Essentially, if the letters
J,K,L, or SR/Sappear in thesightings$BestPodcolumn, I'd like to keep those entries, and entries that do not contain those letters, I'd like dropped. The problem is that I have over 200 different combinations ofJ|j|K|k|L|l|SR|SRS|Sr|srs|sRs|SRs...some even contain numbers and punctuation in between i.e.J12|J?K?|Lp?k4|SR?|K-19...and so on, and so it's impossible to come up with a pattern for efficient use withstringr. Thestr_detectfunction is somewhat helpful but I can't figure out a robust way to subset my data without accidentally losing entries. Here's an image of my df:
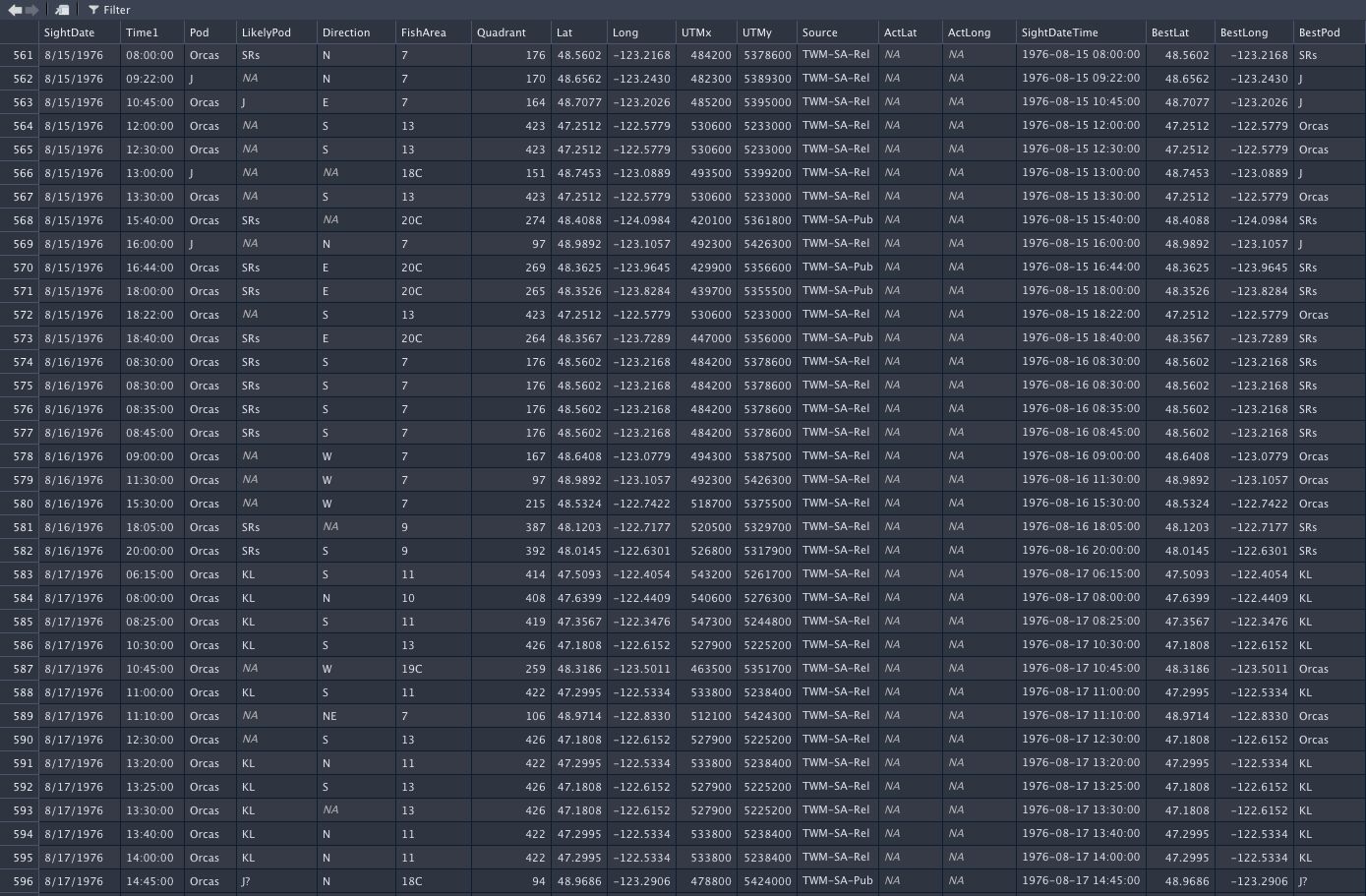
and this is a sample of my data:
SightDateTime BestLat BestLong BestPod
<dttm> <dbl> <dbl> <chr>
1 2011-07-15 15:11:00 48.4 -123. JKLp
2 2006-06-16 19:45:00 48.6 -123. J
3 2012-07-10 13:00:00 48.7 -123. JL
4 2007-08-01 19:00:00 48.6 -123. Orcas
5 2002-07-14 18:30:00 48.8 -123. J
6 2011-09-25 12:45:00 48.6 -123. JKL
and this is the dput:
structure(list(SightDateTime = structure(c(206832600, 204956700,
205804800, 205432200, 205349640, 207708600, 203877300, 199213200,
207710100, 197846580, 206334780, 204772200, 206905800, 206751900,
207174300, 199213500, 2.07e+08, 202773600, 203826420, 197917200
), tzone = "US/Pacific", class = c("POSIXct", "POSIXt")), BestLat = c(48.155,
48.6893, 47.6803, 48.5386, 48.4454, 47.5533, 48.6562, 48.7395,
47.5483, 48.155, 48.6089, 48.3526, 48.5602, 48.711, 48.5602,
48.7395, 48.8053, 48.7453, 47.9811, 47.7785), BestLong = c(-123.5999,
-123.0823, -122.5896, -122.9544, -123.0354, -122.4188, -123.243,
-123.3776, -122.4917, -123.5999, -123.2403, -123.8284, -123.2168,
-123.2655, -123.2168, -123.3776, -122.8315, -123.0889, -122.5625,
-122.8105), BestPod = c("Orcas", "K", "Orcas", "Orcas", "KpLp",
"JK", "Orcas", "Orcas", "JK", "KL", "JK", "Orcas", "KL-19", "J",
"Orcas", "Orcas", "Orcas", "Orcas", "J", "SRs")), row.names = c(NA,
-20L), class = c("tbl_df", "tbl", "data.frame"))
2 ) After dropping those non-J,K,L,or SR(+/-s w/case variation) I'd like to create three new columns J K L where there can be 3 possible values: 0 = FALSE (no J|K|L is not present in subsetted BestPod column) , 1 = TRUE (J|K|L is present in the subsetted column), or 2 = SR(+/-s w/case variations) is present in the subsetted BestPod column Again because those entries vary wildly I really only care about the value of "j", "k", "l", and "sr/s".
Sorry for the long and monumentous ask, but I'm not really sure how to go about tidying this data. Apologies if my examples/sample code are not working, please let me know if they need to be amended!
Any and all help would be so greatly appreciated. Thanks for your time!

