Hello! I'm an absolute beginner so I basically don't know anything. For my research I need to widen my dataset.
Right now I have all my data in DfAllDataLong
Which is set up like:
Farm | Lifeno | Lactation | WeekInMilk | AvgRuminatingtime | Cow (should be after lifeno but allright..) | AvgEatingTime | AvgInActivityTime | AvgLyingTime | Calcium | Ketosis | Uterus |
The WeekInMilk runs from week -6 op to 0 for everycow, so that is 7 rows per cow indeed. Thats because in the Avg...Time columns it gives the average time that the cow has spent eating per day in that week.
Now i need to get the dataset like:
Farm | Lifeno | Lactation | AvgEatingTimeWeek-6 | AvgEatingTimeWeek-5 | AvgEatingTimeWeek-....--> | AvgEatingTimeWeek-1 | AvgRuminatingTimeWeek-6 | AvgRuminatingTimeWeek-....--> | AvgRuminatingTimeWeek-1 | AvgLegActivityTimeWeek-6 | --> | AvgLegactivityTimeWeek-1 | (Etc for all the AVG Times | Calcium | Ketosis | Uterus|
So spread out up to 35 columns..
I have tried the tydir::spread, and if i try with only 1 of the AVG times mentioned above it 'kinda' works.
DfAllDataWide <- tidyr::spread(DfAllDataLong,
key = "WeekInMilk",
value = "AvgRuminatingTime")
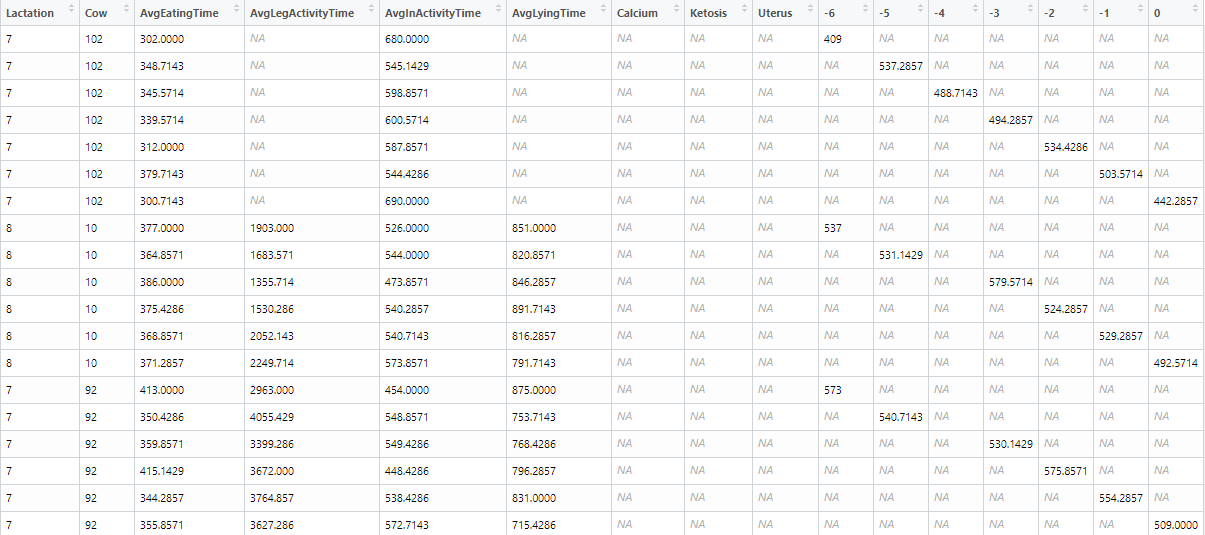
BUT i seem to only be able to do this with one of the behaviour times. When i try to do this again it says that the key "WeekInMilk" is deleted / not found ![]() So i now have no idea how to continue.
So i now have no idea how to continue.
There is probably a very simple solution but i cannot find it.. could you help me with this?
Thanks in advance!
 So im struggling in the way that I cannot really share the dataset.... So im not really sure i can make this reprex?
So im struggling in the way that I cannot really share the dataset.... So im not really sure i can make this reprex?