I found out something weird. Perhaps this is due to my lack of comprehension. But please hear me.
After some model screening with the train split of the data set and chosen a model to work with. At least there are two ways to continue right?
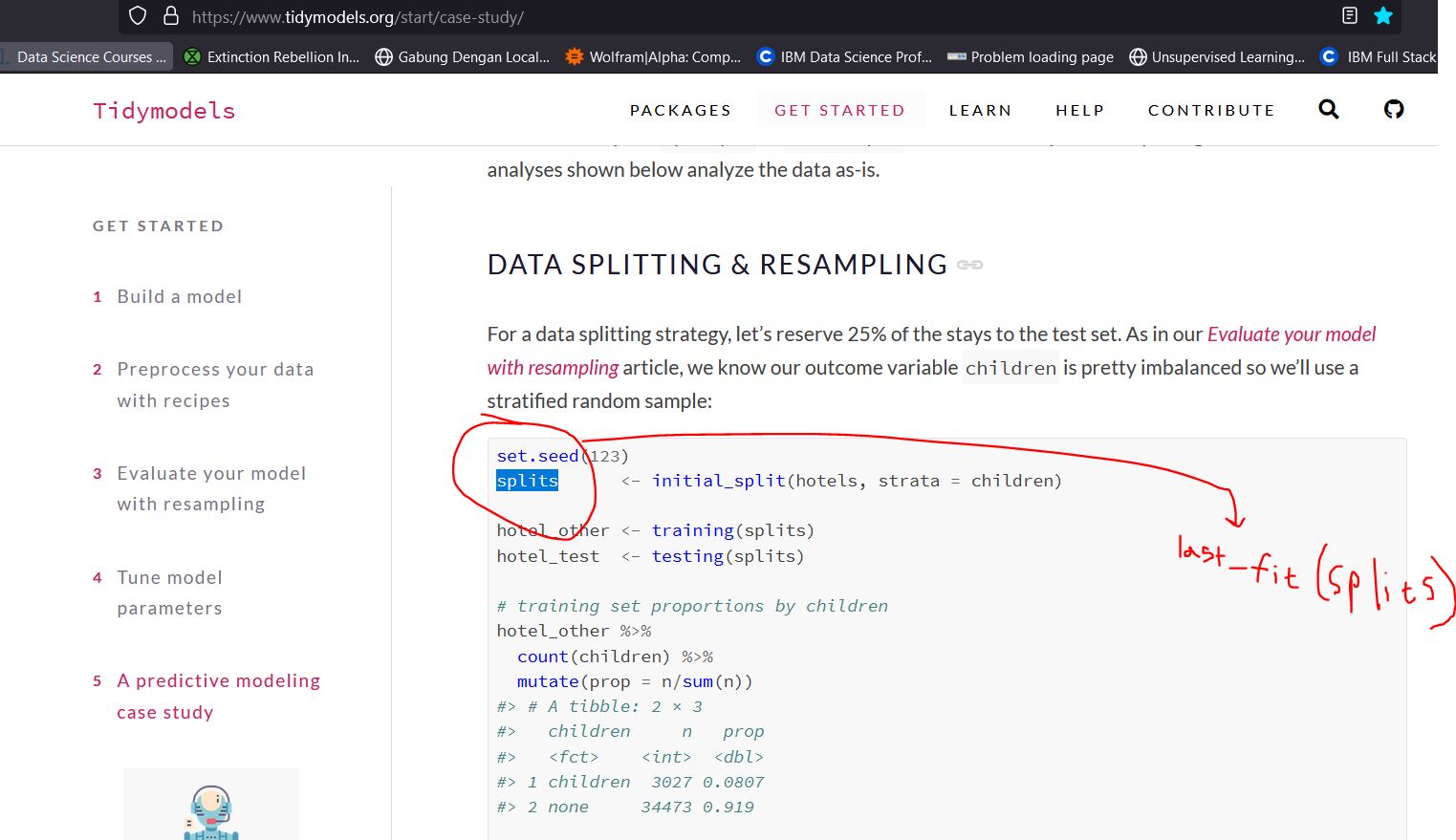
Let's say there's a data called Z, it was split into X for train, and Y for test.
Model screening happened in X.
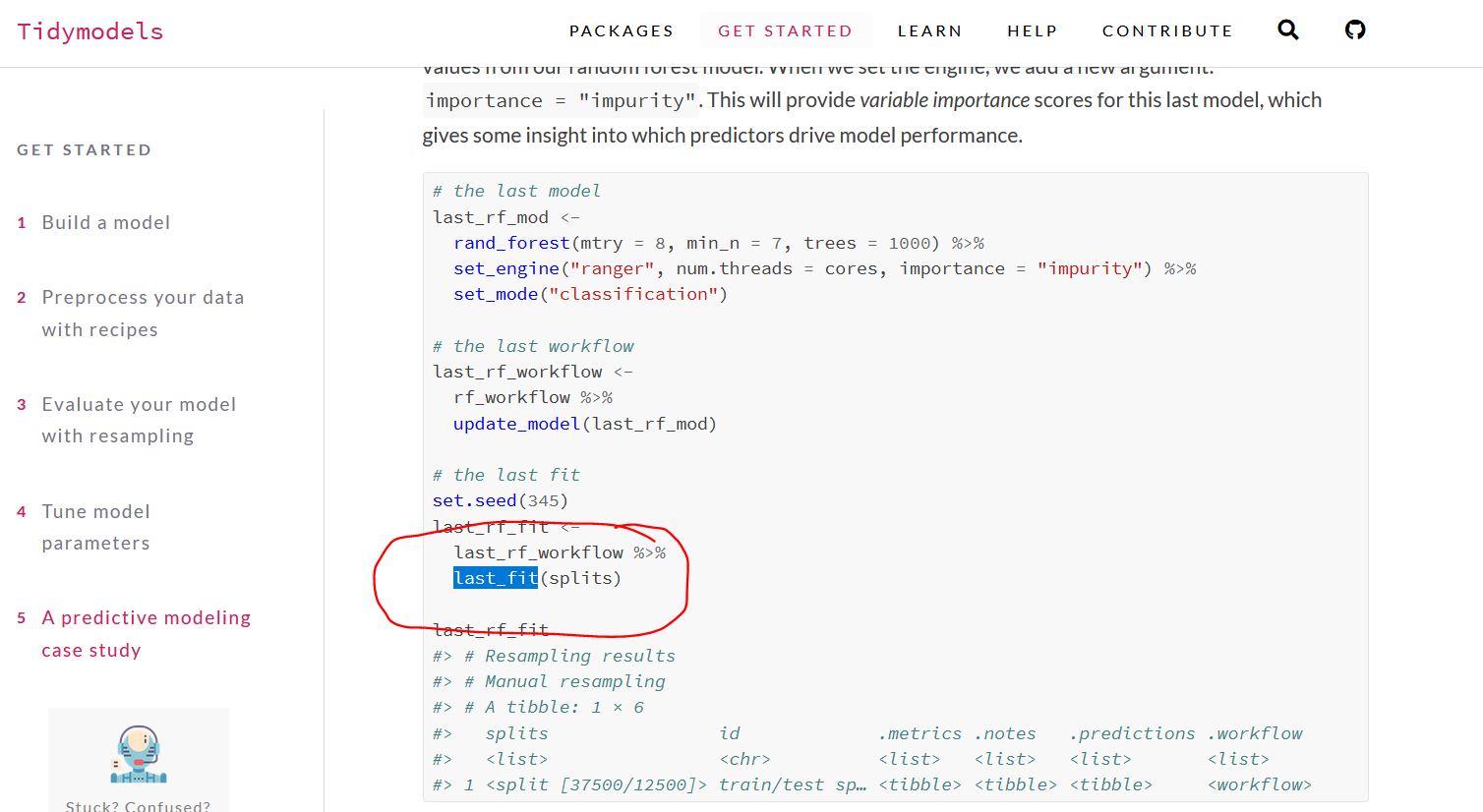
First is by applying the last_fit() function to the original data Z before it was split, then collect the metrics
Or, by applying fit to train data X with the best model, then apply predict to test data Y.
I found out that the two approach resulted in far different results. With last_fit, it's 70 something percent, while using fit to train, then predict to test, resulted in 20 something percent.
How would you do that? last_fit() takes a split object and in not intended to use the entire data set (Z, prior to splitting).
If you are using Z, then there is serious information leakage since you are using the data used to build a model to validate its performance. In that case, it's not a surprise that you get different results.
last_fit() will fit the model using the results of training(splits) (and not the whole hotels data frame).
Showing code (though maybe not in a screenshot) is always the best option to get accurate answers Speaking of which...
As for the difference between the results, can you please provide a minimal reprex (reproducible example)? The goal of a reprex is to make it as easy as possible for me to recreate your problem so that I can fix it: please help me help you!
If you've never heard of a reprex before, start by reading "What is a reprex", and follow the advice further down that page.
It was part of a case study test, so I'm not sure if I were allowed to share it.
In the end, I chose to use last_fit(), merely because it gave better result.
Maybe I will try this specific situation on other projects and ask it again here.