Is there a tidy way to swap columns and rows in a tibble?
For example if I start with
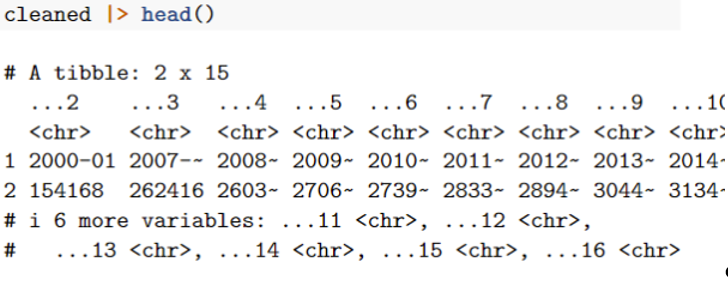
I'd like to end up with
Currently I am doing this with t() (transpose), but this seems terribly inelegant.
Is there a tidy way to swap columns and rows in a tibble?
For example if I start with
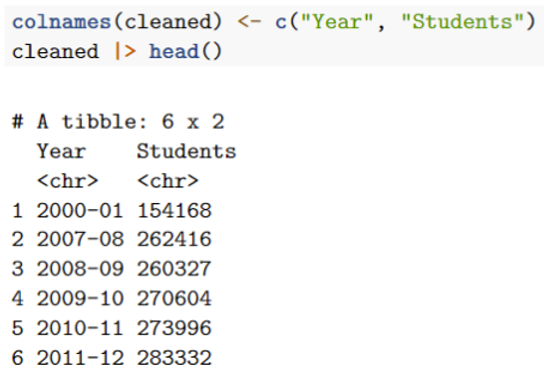
I'd like to end up with
Currently I am doing this with t() (transpose), but this seems terribly inelegant.
Would be great if you could provide a reproducible example, with code I and other users can copy, instead of a screenshot.
In the meantime, you may want to explore tidyr::pivot_longer(). It's not quite transposing, but it takes column names and turns them into vectors. If there are no columns that you want to keep between the old and new, though, simply transposing should work fine.
pivot_longer doesn't do the job, at least not in a way I can figure
"262416"), ...4 = c("2008-09", "260327"), ...5 = c("2009-10",
"270604"), ...6 = c("2010-11", "273996"), ...7 = c("2011-12",
"283332"), ...8 = c("2012-13", "289408"), ...9 = c("2013-14",
"304467"), ...10 = c("2014-15", "313415"), ...11 = c("2015-16",
"325339"), ...12 = c("2016-17", "332727"), ...13 = c("2017-18",
"341751"), ...14 = c("2018-19", "347099"), ...15 = c("2019-20\\1\\",
"162633"), ...16 = c("2020-21\\2\\", "14549")), row.names = c(NA,
-2L), class = c("tbl_df", "tbl", "data.frame"))
Fixed up version is
cleaned <- as_tibble(t(cleaned), .name_repair = "minimal")
colnames(cleaned) <- c("Year", "Students")
cleaned <- structure(list(Year = c("2000–01", "2007–08", "2008-09",
"2009-10", "2010-11", "2011-12", "2012-13", "2013-14", "2014-15",
"2015-16", "2016-17", "2017-18", "2018-19", "2019-20\\1\\", "2020-21\\2\\"
), Students = c("154168", "262416", "260327", "270604", "273996",
"283332", "289408", "304467", "313415", "325339", "332727", "341751",
"347099", "162633", "14549")), class = c("tbl_df", "tbl", "data.frame"
), row.names = c(NA, -15L))
Here's one approach, and I'll add comments later.
matrix(
data = 2001:2006 |> c(1:6),
ncol = 6,
byrow = T
) |>
as.data.frame() -> wide
wide
#> V1 V2 V3 V4 V5 V6
#> 1 2001 2002 2003 2004 2005 2006
#> 2 1 2 3 4 5 6
library(tidyverse)
wide |>
mutate(type = c('date', 'student')) |>
pivot_longer(V1:V6) |>
pivot_wider(names_from = type, values_from = value) |>
select(!name)
#> # A tibble: 6 × 2
#> date student
#> <int> <int>
#> 1 2001 1
#> 2 2002 2
#> 3 2003 3
#> 4 2004 4
#> 5 2005 5
#> 6 2006 6
This looks incredibly clever. I will forward to the comments and learning more.
Here's one approach, starting from a table similar to the one from your post. (Full reprex is as bottom of post.)
matrix(
data = 2001:2006 |> c(1:6),
ncol = 6,
byrow = T
) |>
as.data.frame() -> wide
wide
#> V1 V2 V3 V4 V5 V6
#> 1 2001 2002 2003 2004 2005 2006
#> 2 1 2 3 4 5 6
library(tidyverse)
wide |>
mutate(type = c('date', 'student')) |>
pivot_longer(V1:V6) |>
pivot_wider(names_from = type, values_from = value) |>
select(!name)
#> # A tibble: 6 × 2
#> date student
#> <int> <int>
#> 1 2001 1
#> 2 2002 2
#> 3 2003 3
#> 4 2004 4
#> 5 2005 5
#> 6 2006 6
And here is what is going on: If you try the pivot_longer() function by itself, it doesn't allow you to distinguish between dates and students,
wide |>
pivot_longer(V1:V6)
#> # A tibble: 12 × 2
#> name value
#> <chr> <int>
#> 1 V1 2001
#> 2 V2 2002
#> 3 V3 2003
#> 4 V4 2004
#> 5 V5 2005
#> 6 V6 2006
#> 7 V1 1
#> 8 V2 2
#> 9 V3 3
#> 10 V4 4
#> 11 V5 5
#> 12 V6 6
but if you first add new column that contains the future columns names date and student as values,
wide |>
mutate(type = c('date', 'student'))
#> V1 V2 V3 V4 V5 V6 type
#> 1 2001 2002 2003 2004 2005 2006 date
#> 2 1 2 3 4 5 6 student
pivot_longer()can turn them into a kind of label to distinguish between date and student values:
wide |>
mutate(type = c('date', 'student')) |>
pivot_longer(V1:V6)
#> # A tibble: 12 × 3
#> type name value
#> <chr> <chr> <int>
#> 1 date V1 2001
#> 2 date V2 2002
#> 3 date V3 2003
#> 4 date V4 2004
#> 5 date V5 2005
#> 6 date V6 2006
#> 7 student V1 1
#> 8 student V2 2
#> 9 student V3 3
#> 10 student V4 4
#> 11 student V5 5
#> 12 student V6 6
From here, you can know use pivot_wider to turn the labels into column names,
wide |>
mutate(type = c('date', 'student')) |>
pivot_longer(V1:V6) |>
pivot_wider(names_from = type, values_from = value)
#> # A tibble: 6 × 3
#> name date student
#> <chr> <int> <int>
#> 1 V1 2001 1
#> 2 V2 2002 2
#> 3 V3 2003 3
#> 4 V4 2004 4
#> 5 V5 2005 5
#> 6 V6 2006 6
and then remove the column name, which is no longer needed:
wide |>
mutate(type = c('date', 'student')) |>
pivot_longer(V1:V6) |>
pivot_wider(names_from = type, values_from = value) |>
select(!name)
#> # A tibble: 6 × 2
#> date student
#> <int> <int>
#> 1 2001 1
#> 2 2002 2
#> 3 2003 3
#> 4 2004 4
#> 5 2005 5
#> 6 2006 6
Created on 2024-04-11 with reprex v2.0.2
matrix(
data = 2001:2006 |> c(1:6),
ncol = 6,
byrow = T
) |>
as.data.frame() -> wide
wide
#> V1 V2 V3 V4 V5 V6
#> 1 2001 2002 2003 2004 2005 2006
#> 2 1 2 3 4 5 6
library(tidyverse)
wide |>
mutate(type = c('date', 'student')) |>
pivot_longer(V1:V6) |>
pivot_wider(names_from = type, values_from = value) |>
select(!name)
#> # A tibble: 6 × 2
#> date student
#> <int> <int>
#> 1 2001 1
#> 2 2002 2
#> 3 2003 3
#> 4 2004 4
#> 5 2005 5
#> 6 2006 6
# pivot longer by itself doesn't allow you to distinguish
# between dates and students
wide |>
pivot_longer(V1:V6)
#> # A tibble: 12 × 2
#> name value
#> <chr> <int>
#> 1 V1 2001
#> 2 V2 2002
#> 3 V3 2003
#> 4 V4 2004
#> 5 V5 2005
#> 6 V6 2006
#> 7 V1 1
#> 8 V2 2
#> 9 V3 3
#> 10 V4 4
#> 11 V5 5
#> 12 V6 6
# but if you add new column that contains the future
# columns names 'date' and 'student' as values:
wide |>
mutate(type = c('date', 'student'))
#> V1 V2 V3 V4 V5 V6 type
#> 1 2001 2002 2003 2004 2005 2006 date
#> 2 1 2 3 4 5 6 student
# pivot_longer can turn them into a kind of label to
# distinguish between date and student values
wide |>
mutate(type = c('date', 'student')) |>
pivot_longer(V1:V6)
#> # A tibble: 12 × 3
#> type name value
#> <chr> <chr> <int>
#> 1 date V1 2001
#> 2 date V2 2002
#> 3 date V3 2003
#> 4 date V4 2004
#> 5 date V5 2005
#> 6 date V6 2006
#> 7 student V1 1
#> 8 student V2 2
#> 9 student V3 3
#> 10 student V4 4
#> 11 student V5 5
#> 12 student V6 6
# from here, you can know use pivot_wider to turn
# the labels into column names
wide |>
mutate(type = c('date', 'student')) |>
pivot_longer(V1:V6) |>
pivot_wider(names_from = type, values_from = value)
#> # A tibble: 6 × 3
#> name date student
#> <chr> <int> <int>
#> 1 V1 2001 1
#> 2 V2 2002 2
#> 3 V3 2003 3
#> 4 V4 2004 4
#> 5 V5 2005 5
#> 6 V6 2006 6
# and then remove the column 'name', which is no longer needed
wide |>
mutate(type = c('date', 'student')) |>
pivot_longer(V1:V6) |>
pivot_wider(names_from = type, values_from = value) |>
select(!name)
#> # A tibble: 6 × 2
#> date student
#> <int> <int>
#> 1 2001 1
#> 2 2002 2
#> 3 2003 3
#> 4 2004 4
#> 5 2005 5
#> 6 2006 6
Created on 2024-04-11 with reprex v2.0.2
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.
If you have a query related to it or one of the replies, start a new topic and refer back with a link.