Hello all!
Please excuse my naivety this is something I'm fairly new to and a skill i'm trying to develop. I've followed a tutorial to build a function that counts the amount of words on the page of urls within a Gsheet.
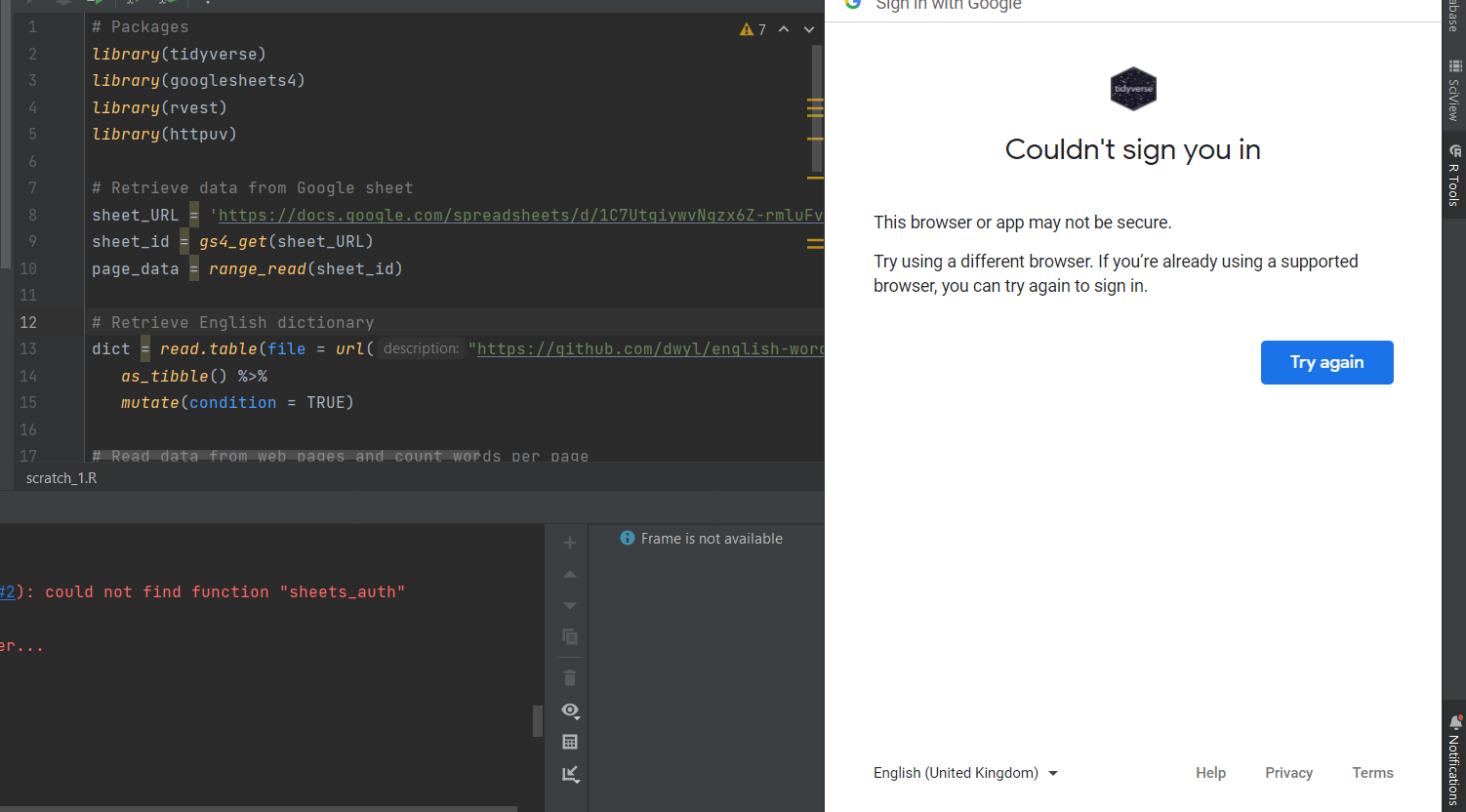
But, I'm repeatedly running into an issue in which Tidyverse is unable to authenticate and i'm receiving this message: "This browser or app may not be secure.
Try using a different browser. If you’re already using a supported browser, you can try again to sign in.".
I've done some research and some the historical fixes eluded to disabling 2-step verification or enabling less safe apps, which as far as I can see is no longer a function. So i'm pretty stumped, if anyone has discovered the solution i'd greatly appreciated any pointers towards where I can find a solution (or attempt to at least!):
Packages
library(tidyverse)
library(googlesheets4)
library(rvest)
library(httpuv)
Retrieve data from Google sheet
sheet_URL = 'https://docs.google.com/spreadsheets/d/1C7UtgiywvNgzx6Z-rmluFvej4TTHdFoX9peDLIK34nY/edit#gid=0'
sheet_id = gs4_get(sheet_URL)
page_data = range_read(sheet_id)
Retrieve English dictionary
dict = read.table(file = url("https://github.com/dwyl/english-words/raw/master/words_alpha.txt"), col.names = "words") %>%
as_tibble() %>%
mutate(condition = TRUE)
Read data from web pages and count words per page
words_per_page = page_data %>%
mutate(words = map(Page, ~return_words(web_page = .x))) %>%
mutate(words = words %>% unlist())
Output data to Google sheets
sheet_write(words_per_page, sheet = 'output', ss = sheet_id)
Functions
return_words = function(web_page){
words = web_page %>%
read_html() %>%
html_text() %>%
# clean words for table
tolower() %>%
str_remove_all(pattern = '"') %>%
str_remove_all(pattern = ",|:|\\.|\\\n") %>%
strsplit(' ') %>%
as_tibble('words') %>%
set_names("words") %>%
# join with English dictionary
left_join(dict) %>%
# keep only words from the english dictionary
filter(condition == TRUE) %>%
pull(condition) %>%
sum()
return(words)
}
Error image
Thank you!