hello all
I am new to R and RStudio so here goes..... ![]()
I am doing my thesis on sentiment analysis and wordcloud but am a bit stuck
Am not totally sure where my problem lies so will post a few things hoping that this will shed light on my issue
I have a file that has about 572 entries in 5 columns. Have reduced it to one column and was able to separate the words. Now I am trying to wordcloud the single entries so see how it looks and then sentiment it.
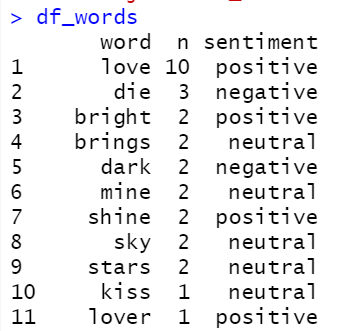
Below is the code that I am trying out
I have tried looping and even just the first entry but with no success
I really can't figure out where I am going wrong
Can someone help me please?
thanks and kind regards
Carlo
library(readxl)
data <- read_excel("C:\\Users\\XXXXX\\OneDrive\\Desktop\\ToPandas.xlsx")
data2 <-data$articlesDescription
data2
#install.packages("wordcloud2")
#install.packages("tidyverse")
#install.packages("tidytext")
#install.packages("stopwords")
#install.packages("stringr")
#install.packages("tm")
library(wordcloud2)
library(tidyverse)
library(tidytext)
library(stopwords)
library(stringr)
library(tm)
data2 <- strsplit(data2, " ")
data3 <- lapply(data2, function(x) gsub("[[:punct:]]", "", x))
data3
x <- data3[[1]]
library(plyr)
library(tibble)
df <- data3
df <- tolower(df)
df <- df %>% anti_join(stopwords)
view(df)
length(df)
for (i in 1:574){
x <- x %>%
anti_join(get_stopwords())%>%
unnest_tokens(word, text) %>%
count(words, sort = TRUE)
}