After downloading the caret package again and running it again, there was still an error. Could you please help me take a look? Thank you
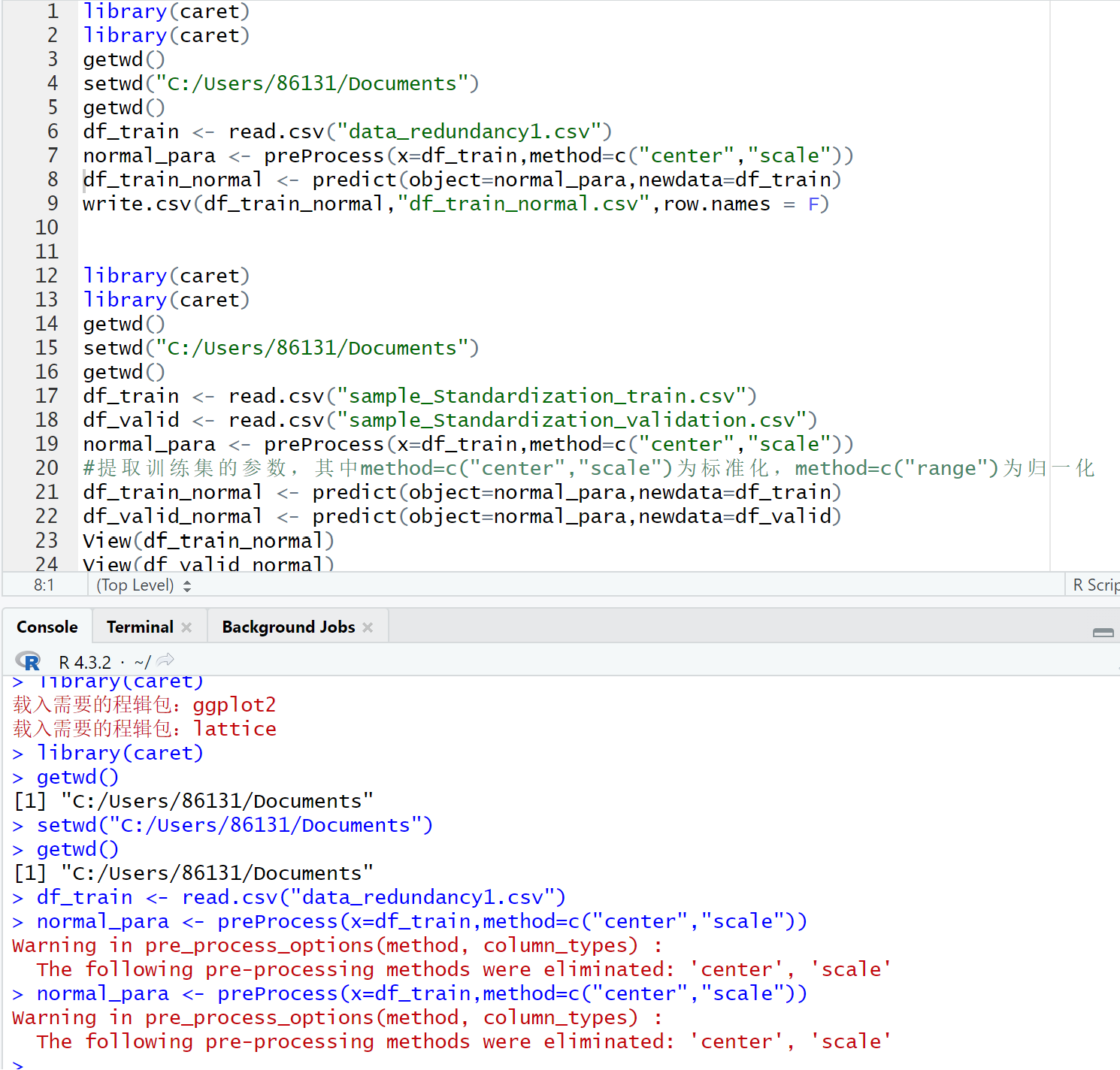
I can't be sure without seeing your data, but I suspect that all of the columns in df_train are characters and there are no numeric columns. Here is an example where the data originally works with preProcess() but then I change the data to characters and I get the same warning that you get.
library(caret)
TestDF <- data.frame(A = 1:4)
PreProcess1 <- preProcess(TestDF)
TestDF$A <- as.character(TestDF$A)
PreProcess2 <- preProcess(TestDF)
Warning in pre_process_options(method, column_types) :
The following pre-processing methods were eliminated: 'center', 'scale'
Run str(df_train) before you run preProcess() and check the data type of you columns.
The content in df_train is data. Please take a look at the image. After running the code, the data did not change. What is the reason for this?

It is hard to tell from an image. It looks like you have three rows of headers. The read.csv() function will treat the first row as a header and include the other rows as part of your data. That will make all of the values characters. Did you run str(df_train) as I suggested?
If you do have three rows of headers, try skipping the first two with
df_train <- read.csv("sample_Standardization_train.csv", skip = 2)
This topic was automatically closed 21 days after the last reply. New replies are no longer allowed.
If you have a query related to it or one of the replies, start a new topic and refer back with a link.