Morning Everyone! I listen to podcasts in different languages and I also read the accompanying transcript. Using R, I would like to copy the transcript, put all the words of the transcript in a list with a count, and then sort alphabetically. Thus, I would create the following.
INPUT
'My name is Max! Welcome to my podcast!! This is the first podcast!' (in reality this might be a four page pdf or word document)
OUTPUT
first 1
is 2
max 1
my 2
name 1
podcast 2
the 1
this 1
How do I do this in R please? Many thanks for your help in advance
library(tidyverse)
a <- tibble(
text = "My name is Max! Welcome to my podcast!! This is the first podcast!"
)
sapply(a, function(x) strsplit(x, split = " ")) %>%
unlist() %>%
tolower() %>%
as_tibble() %>%
mutate(value = str_replace_all(value, "[^[:alnum:]]", "")) %>%
count(value)
Thank you for the code, it works great for English words, do you know how I can use for other languages? So at the moment I want to do this for Russian, French and German. Any ideas?
I got the output below when I put Russian words through the code...
> a <- tibble(
+ text = "Привет, друзья! Меня зовут Макс и добро пожаловать на мой подкаст!
+ Да, наконец-то, наконец-то я запустил, я сделал свой подкаст!
+ Ухуууу! И я очень, очень, очень рад этому!"
+ )
> sapply(a, function(x) strsplit(x, split = " ")) %>%
+ unlist() %>%
+ tolower() %>%
+ as_tibble() %>%
+ mutate(value = str_replace_all(value, "[^[:alnum:]]", "")) %>%
+ count(value)
# A tibble: 22 x 2
value n
<chr> <int>
1 "" 4
2 "<U+0434><U+0430>" 1
3 "<U+0434><U+043E><U+0431><U+0440><U+043E>" 1
4 "<U+0434><U+0440><U+0443><U+0437><U+044C><U+044F>" 1
5 "<U+0437><U+0430><U+043F><U+0443><U+0441><U+0442><U+0438><U+043B>" 1
6 "<U+0437><U+043E><U+0432><U+0443><U+0442>" 1
7 "<U+0438>" 2
8 "<U+043C><U+0430><U+043A><U+0441>" 1
9 "<U+043C><U+0435><U+043D><U+044F>" 1
10 "<U+043C><U+043E><U+0439>" 1
# ... with 12 more rows
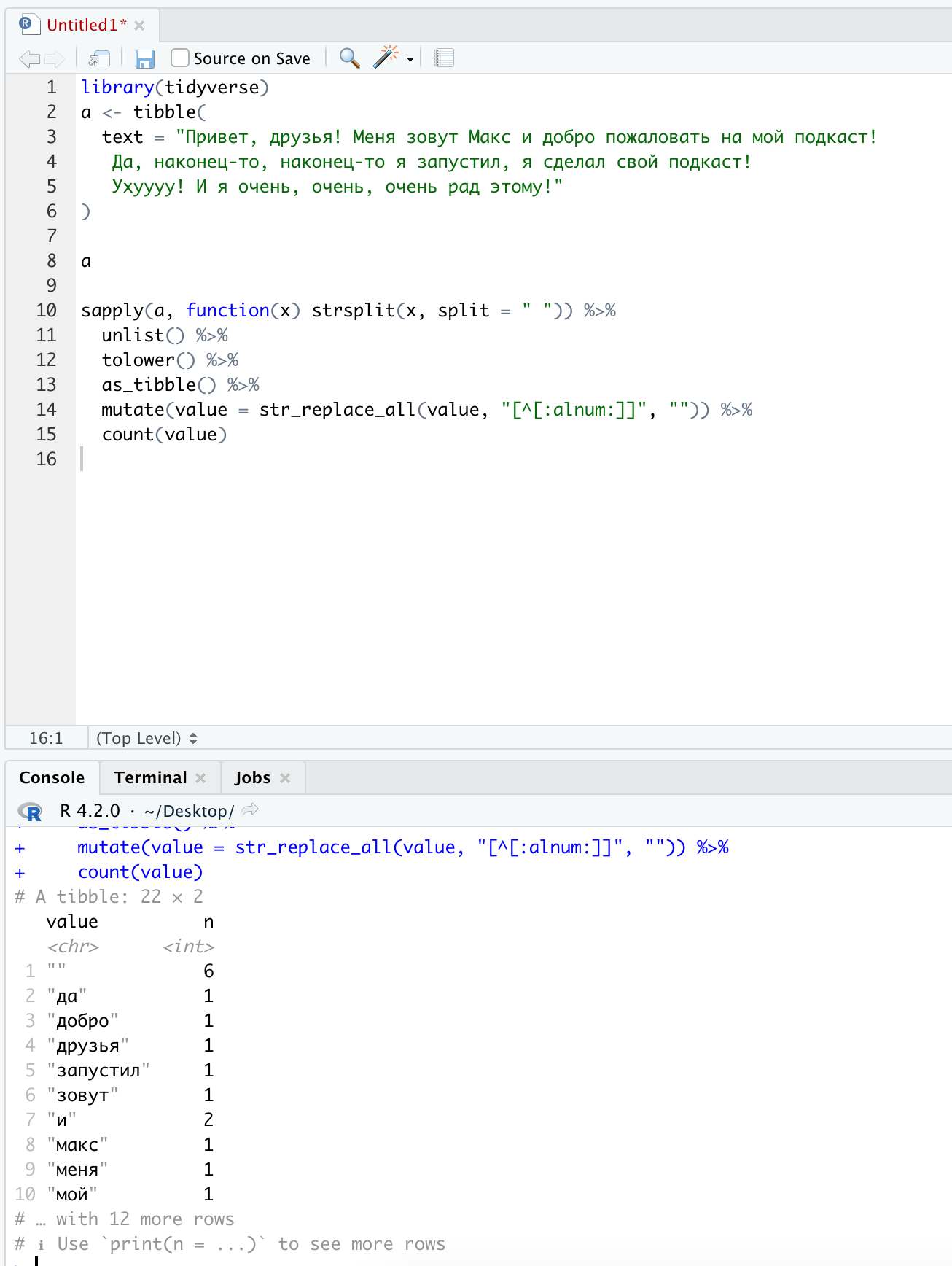
Mmm quite strange, because if I run the same code this is the result:
library(tidyverse)
a <- tibble(
text = "Привет, друзья! Меня зовут Макс и добро пожаловать на мой подкаст!
Да, наконец-то, наконец-то я запустил, я сделал свой подкаст!
Ухуууу! И я очень, очень, очень рад этому!"
)
a
sapply(a, function(x) strsplit(x, split = " ")) %>%
unlist() %>%
tolower() %>%
as_tibble() %>%
mutate(value = str_replace_all(value, "[^[:alnum:]]", "")) %>%
count(value)