Texas Parks & Wildlife Drive Time & Distance Calculator
Authors: Santiago Rodriguez
Abstract: Interactive Texas Parks & Wildlife resources with the ability to calculate drive time and distance.
Full Description: Years ago when I moved to Texas from South Florida I missed going fishing. I discovered that during winter months, Texas Parks & Wildlife (TPWD) stocks local fishing areas with trout. This was music to my ears. However, the static HTML table provided by TPWD wasn't conducive to getting outdoors. The problem with the static table is it only provides the fishing area and the city, and it's too tedious to search each location individually on Google Maps for example. So, I built a Shiny app for myself and hosted it on ShinyApps.io (link). The app was successful and I was able to go fishing. The main goal of this version was to help me find the nearest fishing location and to be able to sort and filter locations.
Recently, I decided to learn more about putting a Shiny app in production. I decided to focus on the TPWD trout POC I built years ago because I thought others could benefit from having a better interface to the trout stocking data. The scope of the app expanded beyond just the trout stocking data though as I realized that other TPWD resources were useful but not interactive. The static nature of the resources might deter some people from getting outdoors. So, I built this Shiny app.
The goal of this app is to help Texans interact with Texas Parks & Wildlife static online resources and to help Texans get outdoors.
Technical Details
Functionality:
- Interactive tables
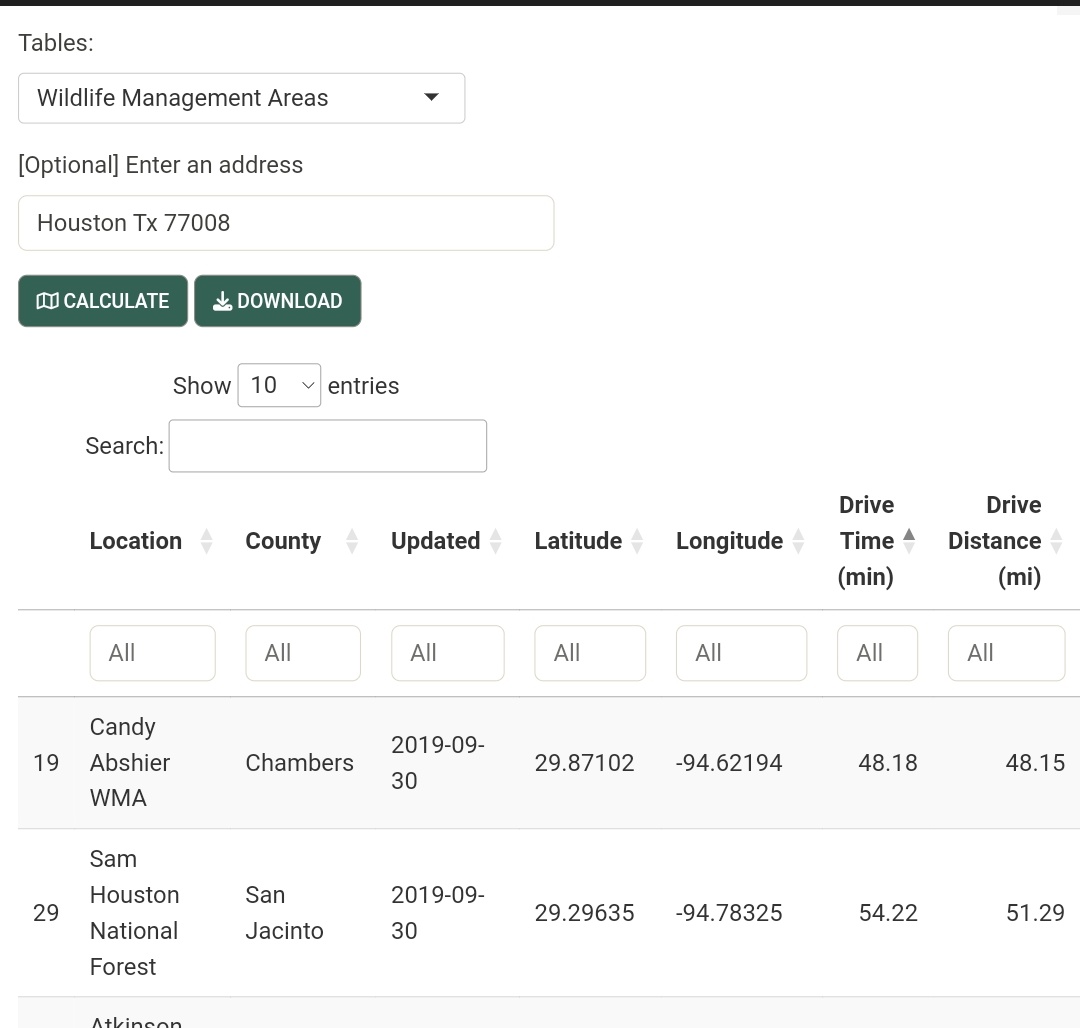
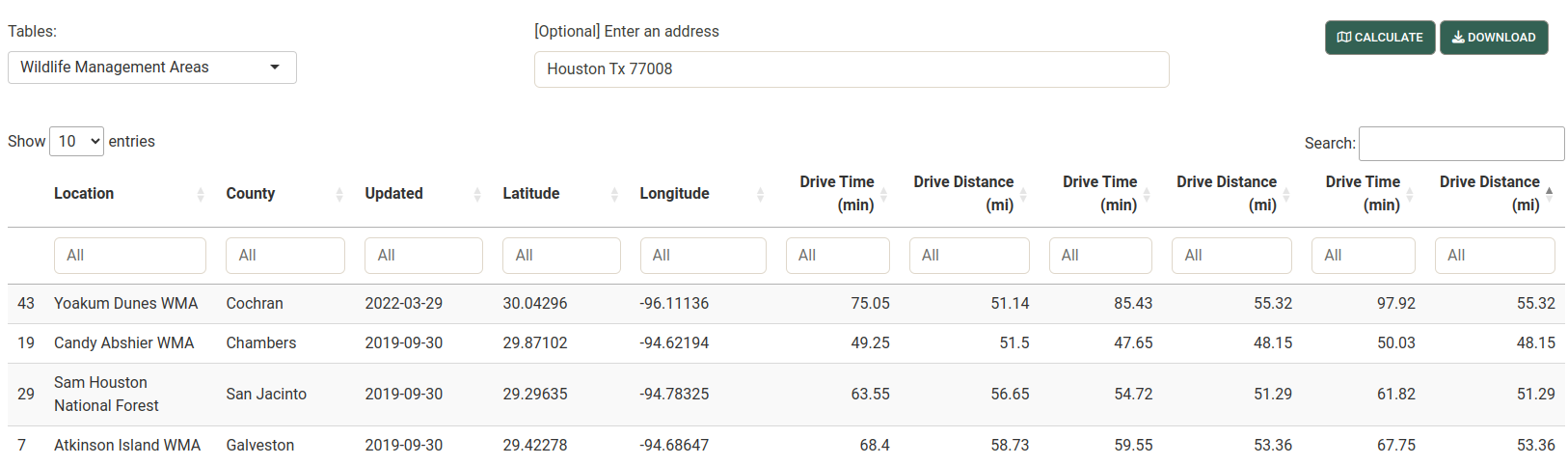
- Calculate drive time and distance
Tables:
- Boat ramps
- Catfish stocking information
- Parks (list of state parks)
- Trout stocking information (2023-2024 season, 2024-2025 season begins in November)
- Wildlife management areas
Hosting:
- AWS EC2 (free tier t2.micro)
Software:
- Shiny (R) built with the Rhino development framework
- HERE API for route calculation logic
- Docker
Architecture:
- data layer
- web app
Regarding the architecture of the app. There are two services, a data layer and a web app. The two services operate independently of each other. This has many benefits and a few drawbacks. The primary benefit is the app is lean and efficient. One drawback is it's possible, while unlikely, that the app is live but has no data to display.
The data layer was built using Julia and imports, transforms, and writes the data used by the app (as arrow files) to an AWS S3 bucket. The app imports the arrow files from the AWS S3 bucket using reactive inputs.
The app's only calculation is outsourced to the HERE API to obtain route info, which can be slow depending on the table size. Since the app is hosted on a free tier t2.micro instance (1 thread) there is no opportunity to use fancy optimizations, such as parallelization.
The separation of the data layer and the app also helps to include new tables without interrupting the app or UX. As tables are added the app auto updates the Tables selection.
Shiny app: https://tableswebapp.thealgo.group/
Repo: ShinyContest2024 / WebApp · GitLab
Thumbnail:

Full image: