I'm new to R, so I apologise in advance if I'm not clear enough or if my question is too naive.
I'm trying to analyse the data from a psycholinguistic study using linear mixed models, and my problem is that it takes hours to run maximal models. R's running and running for hours (even 72), and either nothing happens or I get the 'singular fit' warning. I have three IVs (a 2 x 2 x 3 design) and two DVs (reaction times, and accuracy). There were 35 participants and 40 items per condition.
Can you just tell on the top of their head what the problem might be?
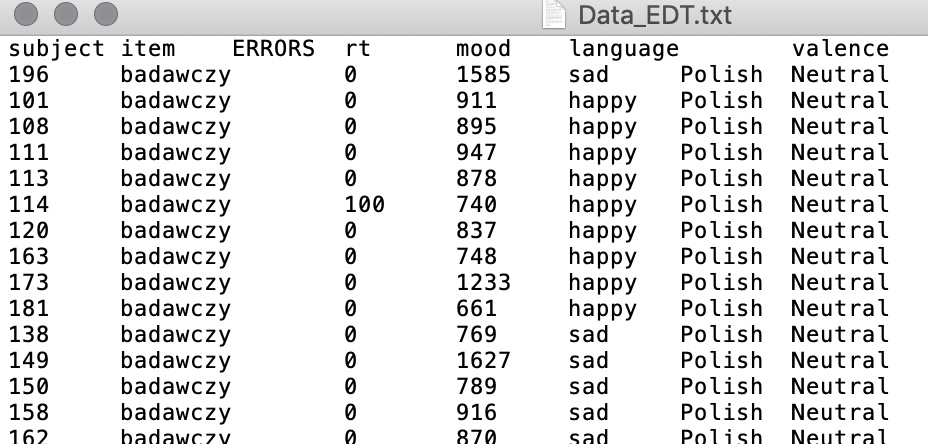
This is how the data is organised in the data file:
Next, it sounds like you understand the statistics of mixed effects models but the lme4 package is not behaving well with you data set. Would you be interested in trying to train the model with a mixed effect random forest approach?
Tree-Based Varying Coefficient Regression for Generalized Linear and Ordinal Mixed Models
Recursive partitioning for varying coefficient generalized linear models and ordinal linear mixed models. Special features are coefficient-wise partitioning, non-varying coefficients and partitioning of time-varying variables in longitudinal regression.
I have not used this package myself. This might help you narrow down whether there is something flawed in the data set if both techniques have problems training on it.