Hi,
I am using the NHANES package for the data, and CreateTableOne for the function to make a table such as this:
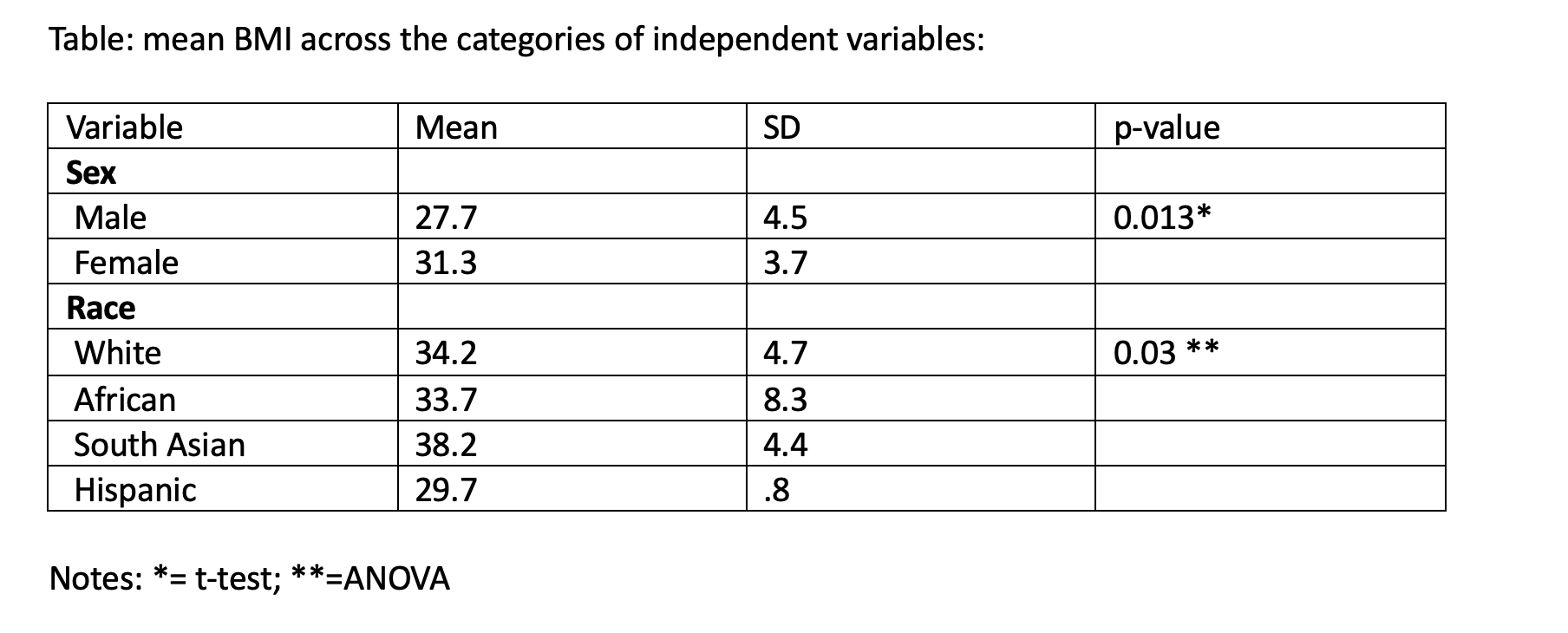
Variable Mean SD p-value
Sex
Male 27.7 4.5 0.013*
Female 31.3 3.7
Race
White 34.2 4.7 0.03 **
African 33.7 8.3
South Asian 38.2 4.4
Hispanic 29.7 .8
Notes: *= t-test; **=ANOVA
The method described in the help file is not for this kind of table, as it gives n and % only, and not mean and sd. I am wondering if there is any way to create a table like the above.
Here is what I tried so far:
> myVars <- c("HHIncomeMid","SleepTrouble", "HomeOwn", "Education")
> CreateTableOne(vars = myVars, data=NHANES )
Overall
n 10000
HHIncomeMid (mean (SD)) 57206.17 (33020.28)
SleepTrouble = Yes (%) 1973 (25.4)
HomeOwn (%)
Own 6425 (64.7)
Rent 3287 (33.1)
Other 225 ( 2.3)
Education (%)
8th Grade 451 ( 6.2)
9 - 11th Grade 888 (12.3)
High School 1517 (21.0)
Some College 2267 (31.4)
College Grad 2098 (29.1)
Please let me know if you have any idea.
Thanks in advance.
My quick reading of the {tableone} documentation suggests that it is fairly rigidly designed for a "Table 1" in a medical study report. I think you probably need to look at one of the more general packages that supply more flexibility. Such a table as you want should be fairly easily done in one of them, You might want to have a look at {gt}, {flextable}, { kableExtra}, {tinytable} and I imagine there are others.
Can you supply us with the final dataset that you are using? A handy way to supply data is to use the dput() function. Do dput(mydata) where "mydata" is the name of your dataset. For really large datasets probably dput(head(mydata, 100)) will do. Paste the output between
```
I recommend looking into the package gtsummary. The example below gets you almost there. I couldn't quite figure out how to do the ANOVA test but perhaps someone else can. Note the use of a reproducible example. I did this using the package reprex.
library(NHANES)
library(tableone)
data("NHANES")
myVars <- c("HHIncomeMid","SleepTrouble", "HomeOwn", "Education")
CreateTableOne(vars = myVars, data=NHANES )
#>
#> Overall
#> n 10000
#> HHIncomeMid (mean (SD)) 57206.17 (33020.28)
#> SleepTrouble = Yes (%) 1973 (25.4)
#> HomeOwn (%)
#> Own 6425 (64.7)
#> Rent 3287 (33.1)
#> Other 225 ( 2.3)
#> Education (%)
#> 8th Grade 451 ( 6.2)
#> 9 - 11th Grade 888 (12.3)
#> High School 1517 (21.0)
#> Some College 2267 (31.4)
#> College Grad 2098 (29.1)
library(gtsummary)
#> Warning: package 'gtsummary' was built under R version 4.4.1
#> #BlackLivesMatter
NHANES %>%
tbl_continuous(
variable = BMI,
include=c(Gender, Race1),
statistic = everything() ~ "{mean} ({sd})",
digits=everything()~1
) %>%
add_p(
list(Gender~"t.test"),
test.args = all_tests("t.test") ~ list(var.equal = TRUE)
)
This is brilliant! Thank you so much for the neat solution!
I have a follow-up question to this, does this method auto-decide the type of test e.g. t-test or anova, depending the number of categories in the row variables?