Hi RStudio Community,
I'm trying to replicate a summary table in R, which I have successfully created in Excel.
Goal:
- Create a summary table of 2 columns (
country, andtype), and summarize by the distinct count of another column :customer_id.
Given the following sample dataframe:
library(tidyverse)
customer_id <- c('A1', 'A1', 'A1', 'B2', 'B2', 'C3', 'C3', 'D4', 'D4', 'E5')
country <- c('Brazil', 'Brazil', 'Peru', 'Brazil', 'Costa Rica', 'Brazil', 'Peru', 'Brazil', 'Costa Rica', 'Hawaii')
type <- c('Arabica', 'Robusta', 'Excelsa', 'Arabica', 'Robusta', 'Arabica', 'Excelsa','Robusta', 'Excelsa', 'Arabica')
df <- data.frame(customer_id, country, type)
I want to pivot country and type to the rows, and create two summary columns:
distinct_count_of_customer_idpercentage_of_grand_total_distinct_count_of_customer_id
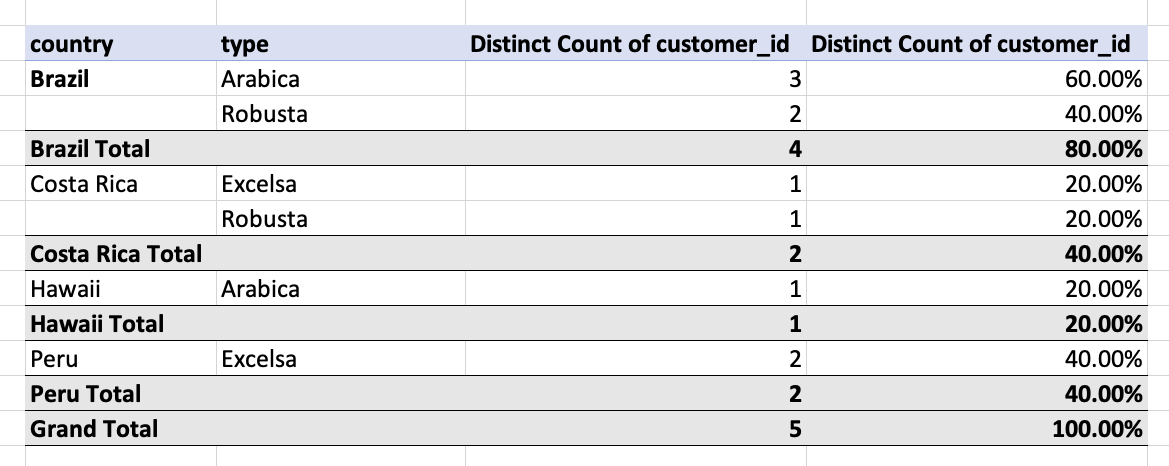
The attached screenshot from what I've done in Excel should help explain better what I'm trying to accomplish: a pivot table with country and type, summarized by the distinct count of customer ids in the customer_id column.
As you can see, there are 5 customers, so the grand total is 5. (And the grand total also sums to 100%)
I have tried various combinations of group_by(), summarize(), distinct(), and/or distinct_n()... but I just can't make it work after after a lot of research, and trial and error. Really appreciate any advice.