juudd
May 9, 2019, 3:55pm
1
Hello
How to sum the number of occurrences at each position in the fragment?
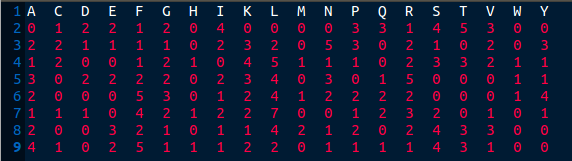
For fragment 1 I will have: TATLQAKA: 5 + 2 + 3 + 4 + 2 + 1 + 1 + 4 = 22
QCLKMLET 3 + 2 + 5 + 3 + 1 + 7 + 3 + 3 = 27
How to do it in R rather than in the hand.
Thank you very much if you have an idea!
1 Like
Welcome to the community!
I believe the following does what you want.
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
library(stringr)
df <- data.frame(Segments = c("TATLQAKA", "QCLKMLET", "EARKIFRF", "SKKELKEL", "CPVGFLGN", "VNTQPGFH", "GDGRGDIC", "IPSNFVSP", "EFFRGLNI", "SCTYQLAR"),
stringsAsFactors = FALSE)
str_split_fixed(string = df$Segments,
pattern = "",
n = 8) %>%
as.data.frame() %>%
mutate_all(.funs = list(counts = ~ table(.)[.])) %>%
select(ends_with("_counts")) %>%
mutate(scores = rowSums(x = .),
strings = df$Segments) %>%
select(strings, scores)
#> strings scores
#> 1 TATLQAKA 12
#> 2 QCLKMLET 14
#> 3 EARKIFRF 11
#> 4 SKKELKEL 10
#> 5 CPVGFLGN 13
#> 6 VNTQPGFH 10
#> 7 GDGRGDIC 10
#> 8 IPSNFVSP 10
#> 9 EFFRGLNI 14
#> 10 SCTYQLAR 16
Created on 2019-05-09 by the reprex package (v0.2.1)
juudd
May 10, 2019, 8:47am
3
Hello,
if it's possible to change
data.frame(Segments = c("TATLQAKA", "QCLKMLET", "EARKIFRF", "SKKELKEL", "CPVGFLGN", "VNTQPGFH", "GDGRGDIC", "IPSNFVSP", "EFFRGLNI", "SCTYQLAR"),
stringsAsFactors = FALSE)
by a segment list contained in a file like "segment.txt",
Think you
I'm not sure I understand what you're asking.
I'm guessing that you meant that you have the strings in a comma separated text file. Is that it?
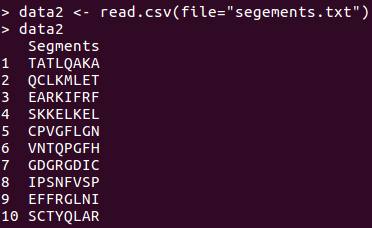
If so, then it can be done easily. First, suppose there's a text file named segment.txt in the working directory. It's contents are in this form:
"Segments"
"TATLQAKA"
"QCLKMLET"
"EARKIFRF"
"SKKELKEL"
"CPVGFLGN"
"VNTQPGFH"
"GDGRGDIC"
"IPSNFVSP"
"EFFRGLNI"
"SCTYQLAR"
Then, read that file in R using read.csv and use the rest of the code.
By the way, I found that strsplit can be used in this instead of stringr::str_split_fixed. Hence, being biased, let me post that solution too (essentially they are same).
library(package = "dplyr")
dataset <- read.csv(file = "segment.txt",
stringsAsFactors = FALSE)
do.call(what = rbind,
args = strsplit(x = dataset$Segments,
split = "")) %>%
as.data.frame() %>%
mutate_all(.funs = ~ table(.)[.]) %>%
mutate(strings = dataset$Segments,
scores = rowSums(.[-9]))
Now, if your question is answered, will you please consider marking this thread as solved?
If you don't know how to do it, please take a look at this thread:
If your question has been answered, don't forget to mark the solution!
How do I mark a solution?
Find the reply you want to mark as the solution and look for the row of small gray icons at the bottom of that reply. Click the one that looks like a box with a checkmark in it:
[image]
Hovering over the mark solution button shows the label, "Select if this reply solves the problem". If you don't see the mark solution button, try clicking the three dots button ( ••• ) to expand the full set of options.
When a solution is chosen, the icon turns green and the hover label changes to: "Unselect if this reply no longer solves the problem". Success!
system
May 17, 2019, 2:58pm
6
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.