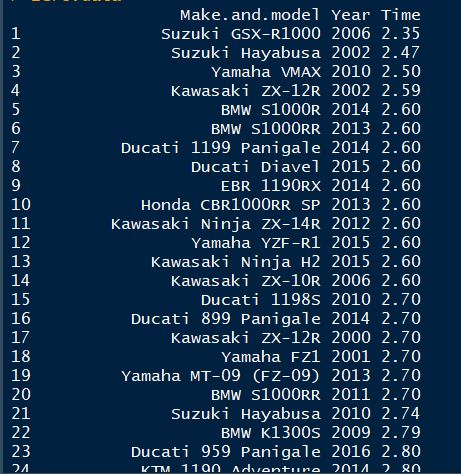
Dear All,
I am trying to subset some particular rows in the data with the picture attached. My goal is to (1) List the "Make.and.model" with model names ending with 'R'.
(2) List the "Make.and.model" that might be smaller than 'liter' bikes (engine size < 1000 cc), based on their name. I want to achieve this by first, excluding motorcycles with 1 in the name (these will mostly be 1000+ numbers). From that set of names, I will now select those with numbers in range 2-9 in their names.
Please, how do I achieve these?
As @mishabalyasin mentioned, it will be much easier to help you with a reprex. However, a general suggestion would be to take a look at the stringr package and its Regular Expression helpers (likely for use in combination with tidyr, or a similar tool for helping you separate out multiple variables from a single column, which is what you have right now). See, for example, the section on separating multiple vars in the Tidy data vignette:
Once you've done that (which is the majority of the work), you'll be able to begin to subset data. For example, if you got a reliable displacement figure (I don't know how accurate you want to be, for example, the Diavel is 1200cc, which isn't in the name — R can also mean different things depending on the make) you could use dplyr::filter() to select rows with engine displacements >= 1000.
Great! Can you share your solution here as well? It is very likely that someone else might have similar problem in future, so it will be helpful to have it in one place.
Sure!
So for the first part of my problem, this is how I got it done sqldf("select * from data where variable like '%R' ").
This is the second part of the problem and the code:
# selecting those with numbers with 1
data$variable[grepl("[1]", data$variable)]
# dropping those with numbers with 1
exlud <- data$variable[!grepl("[1]", data$variable)]
exlud
# those with numbers between 2-9
exlud[grepl("[2-9]", exlud)]