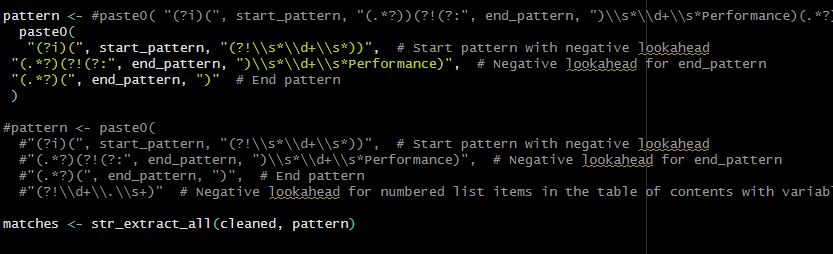
Sorry I should have used gregexec(), not regexec().
regexec() gives you the position of the match:
match_start
#> [[1]]
#> [1] 11
#> attr(,"match.length")
#> [1] 4
#>
#> [[2]]
#> [1] 1
#> attr(,"match.length")
#> [1] 4
For example here you get a list of length 2, because there are 2 input letters in text, and, if using gregexec() each one is a vector of the starting positions of all the matches:
text <- c("Hello greeting random word dear")
start_words = c("dear", "hello", "greeting")
gregexec(paste(start_words, collapse = "|"), text, ignore.case = TRUE)
#> [[1]]
#> [,1] [,2] [,3]
#> [1,] 1 7 28
#> attr(,"match.length")
#> [,1] [,2] [,3]
#> [1,] 5 8 4
#> attr(,"useBytes")
#> [1] TRUE
#> attr(,"index.type")
#> [1] "chars"
You can see you have a list of length 1 because there is a single element in text, and you have matches at positions 1, 7, and 28 (and their lengths are 5, 8, and 4 characters).
Then in my map(), I use start[which.min(start)], which means take the starts, and keep the first one. That was also a bit of a mistake, it's just as easy to take the min() directly:
text <- c("as Hello greeting random word dear")
start_words = c("dear", "hello", "greeting")
match_start <- gregexec(paste(start_words, collapse = "|"), text, ignore.case = TRUE)
min(match_start[[1]])
#> [1] 4
Here the min is 4, because "Hello" starts on the 4th character of the string.
So the idea is to use gregexec() to find the positions of all the start and end words, then use min() and max() to select the most relevant ones, and finally use substr() to extract the text between these positions. Depending on whether you want to include the start and end word, you might have to play with the length of the match too. For example, to exclude the start word:
> match <- match_start[[1]]
> first_start_word <- which.min(match)
> first_start_word
[1] 1
> pos_first_start_word <- match[first_start_word]
> length_first_start_word <- attr(match, "match.length")[first_start_word]
> pos_first_start_word
[1] 4
> length_first_start_word
[1] 5
>
> substr(text,
+ start = pos_first_start_word + length_first_start_word,
+ stop = nchar(text))
[1] " greeting random word dear"
So the nice thing is that you can run gregexec() only for start words, then only for end words, see if one of them is the problem. Then you can manually check the start and end positions to ensure they make sense before running substr() on them. And if needed you can subset these matches to find which one is problematic.
purrr::map() or pmap() are equivalents to lapply(), it's a way to run a function on each element of a list. My code above was:
res <- purrr::pmap(list(match_start, match_end, text),
\(start, end, txt){
substr(txt,
start = start[which.min(start)],
stop = end[which.max(end)])
})
it could be rewritten as:
n <- length(text)
stopifnot(length(match_start) == n)
stopifnot(length(match_end) == n)
res <- vector(mode = "list", length = n)
for(i in seq_len(n)){
start <- match_start[[i]]
end <- match_end[[i]]
txt <- text[[i]]
res[[i]] <- substr(txt,
start = start[which.min(start)],
stop = end[which.max(end)])
}
there are some advantages of using map(), for example you can easily ask for a progress bar, but if you're not familiar with {purrr}, a for loop is fine too.