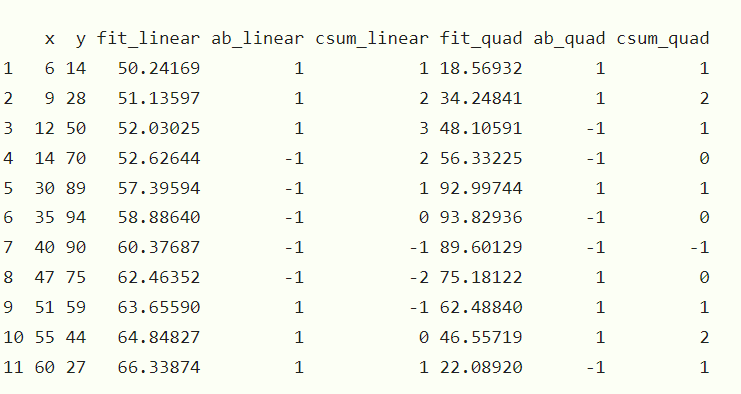
Here's some sample data that is obviously quadratic, and code to calculate cumsum in linear and quadratic cases. I'm not sure what to do next with K-S.
df <- data.frame(x=c(6, 9, 12, 14, 30, 35, 40, 47, 51, 55, 60),
y=c(14, 28, 50, 70, 89, 94, 90, 75, 59, 44, 27))
linear <- lm(df$y ~ df$x)
summary(linear)
df$fit_linear <- fitted(linear)
df$ab_linear <- ifelse(df$fit_linear >= df$y, 1, -1)
df$csum_linear <- cumsum(df$ab_linear)
plot(df$x, df$y, pch=16, cex = 1.3, col = "blue", main = "Linear")
abline(lm(df$y ~ df$x), col="firebrick1")
quad <- lm(df$y ~ df$x + I(df$x^2))
summary(quad)
df$fit_quad <- fitted(quad)
df$ab_quad <- ifelse(df$fit_quad >= df$y, 1, -1)
df$csum_quad <- cumsum(df$ab_quad)
df
bo <- quad$coefficient[1]
b1 <- quad$coefficient[2]
b2 <- quad$coefficient[3]
equation = function(x){bo+b1x+b2x^2}
plot(df$x, df$y, pch=16, cex = 1.3, col = "blue", main = "Quadratic" )
curve(equation, from=0, to=3500, n=10000, add=TRUE, col="firebrick1")