library(tidyverse)
library(tibble)
# Some random data
# make reproducible
set.seed(42)
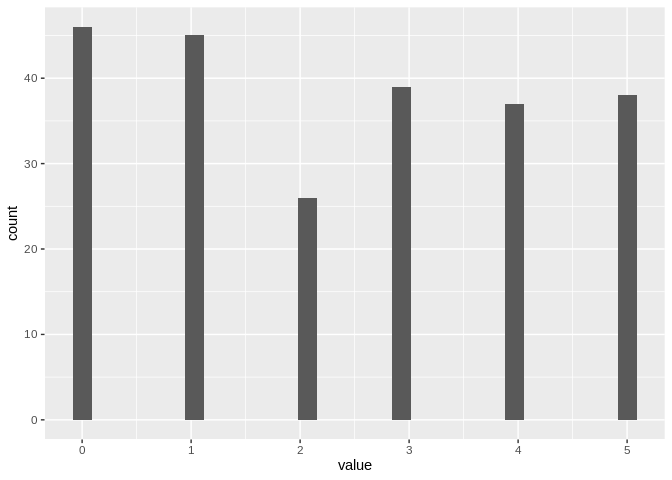
my_data1 <- sample(0:5,231, replace = TRUE)
#convert to tibble
my_data1 <- enframe(my_data1)
my_data
#> Error in eval(expr, envir, enclos): object 'my_data' not found
# Visualize it
ggplot(my_data1, aes(value)) + geom_histogram()
#> `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
# repeat with different seed
set.seed(137)
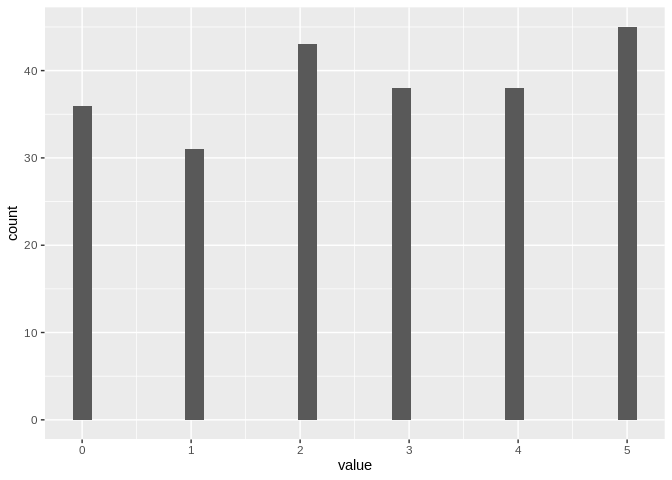
my_data2 <- sample(0:5,231, replace = TRUE)
#convert to tibble
my_data2 <- enframe(my_data2)
my_data2
#> # A tibble: 231 x 2
#> name value
#> <int> <int>
#> 1 1 2
#> 2 2 1
#> 3 3 4
#> 4 4 5
#> 5 5 2
#> 6 6 4
#> 7 7 2
#> 8 8 2
#> 9 9 3
#> 10 10 1
#> # … with 221 more rows
# Visualize it
ggplot(my_data2, aes(value)) + geom_histogram()
#> `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
# Is that normal?
shapiro.test(my_data1$value)
#>
#> Shapiro-Wilk normality test
#>
#> data: my_data1$value
#> W = 0.89123, p-value = 7.393e-12
shapiro.test(my_data2$value)
#>
#> Shapiro-Wilk normality test
#>
#> data: my_data2$value
#> W = 0.90426, p-value = 5.438e-11
# Compare the runs
run1 <- rle(my_data1$value)
summary(run1)
#> Length Class Mode
#> lengths 186 -none- numeric
#> values 186 -none- numeric
run2 <- rle(my_data2$value)
summary(run2)
#> Length Class Mode
#> lengths 198 -none- numeric
#> values 198 -none- numeric
# roughish measure of correlation
cor(run1$lengths,run2$lengths[1:186])
#> [1] 0.1323134
The short answer is that it depends on the function that generates your data. It's usually unknown. If it is normal (randomly) distributed, the probability p(x) for any row givenx in the previous row is the same as given any other value in the previous row, 0.1666667, given your data.
Another way of saying this is that
The dice have no memory
This is the number one hardest concept for a newcomer to statistics to internalize.