Hello,
I would like to divide my data based on the median into high risk and low risk data based on total_perTMB . I would like them to be in one column matched on the base tumour_sample_barcode
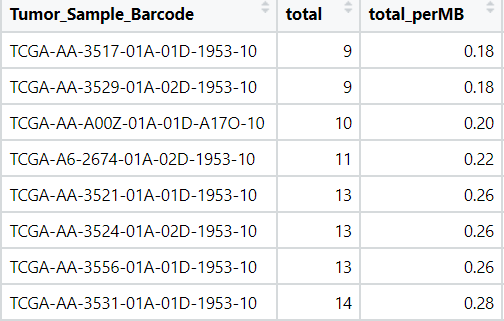
It seems you want to categorise each entry by where its above or below the median. If thats the case this should point you towards a possible approach
(yourdata <- data.frame(tumorcode=letters[1:6],
total_perMb=(1:6)^2/1000))
library(tidyverse)
(solved <- mutate(yourdata,
above_median = total_perMb> median(total_perMb)))This topic was automatically closed 21 days after the last reply. New replies are no longer allowed.
If you have a query related to it or one of the replies, start a new topic and refer back with a link.