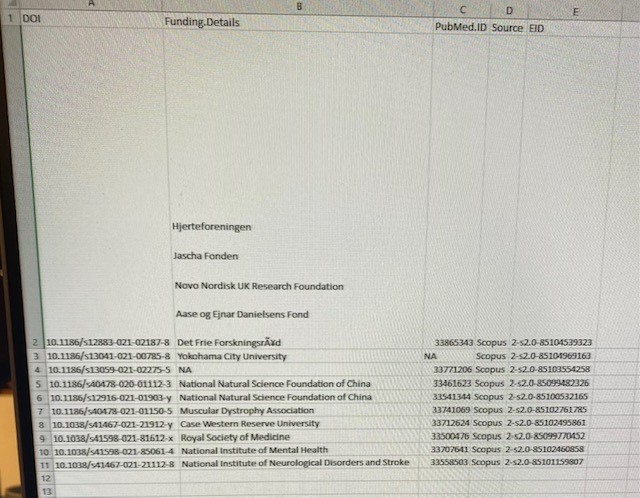
I have an issue splitting information, separated with soft returns (link breaking) in cells to obtain a new row below it containing the information from all the other cells, and only one of the information in the line breaked cell. I am a new user, and after a whole day on internet trying to find a solution I gave up
I looked into the following packages: stringr, tidyverse and tidyr
But maybe that is the wrong place
I would like to have 1 funding detail per row, so the rest of the row should be copied.
E.g. line 2 all information should stay the same, except only 1 funding organization
New line should contain all information, exept second funding organization of line 2, etc.
This seems to be Excel. Is the goal to load this Excel file into R, process it, then export it back to Excel? Then this should work:
library(tidyverse)
my_excel <- readxl::read_excel("Book1.xlsx")
my_excel
#> A tibble: 2 x 5
#> DOI Funding.Details Pubmed.ID Source EID
#> <chr> <chr> <chr> <chr> <chr>
#> 1 a "fa\r\nfb\r\n\r\nfc\r\n" b c d
#> 2 e "ff\r\n" g h i
my_excel <- my_excel |>
tidyr::separate_rows(Funding.Details) |>
filter(nchar(Funding.Details) > 0 )
my_excel
#> A tibble: 4 x 5
#> DOI Funding.Details Pubmed.ID Source EID
#> <chr> <chr> <chr> <chr> <chr>
#> 1 a fa b c d
#> 2 a fb b c d
#> 3 a fc b c d
#> 4 e ff g h i
writexl::write_xlsx(my_excel, "Book1_expanded.xlsx")
Where \r\n is the newline on Windows, it would look slightly different on MacOS (\r) or Linux (\n).
Thank you very much for your solution, reads like it might work as well.
In the meantime, someone else suggested another solution (enclosed), which I tried and it worked.
The original dataframe consists of 23 columns, >10.000 entries ....