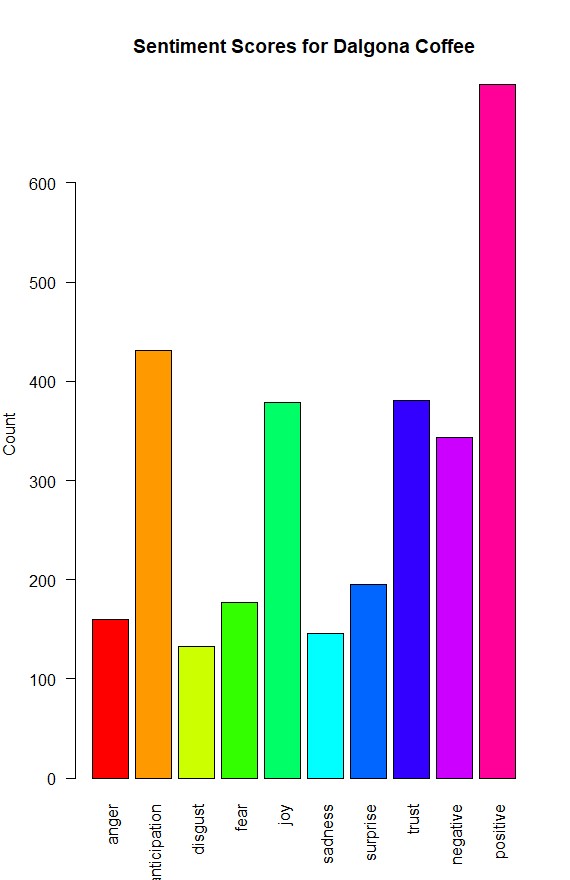
How do I make another graph/word cloud that shows the count of specific words that are included in "positive" and "negative"?
#read csv
dalgona= read.csv("dalgona.csv")
Dalgona = data.frame(dalgona)
#Cleaning
corpus = iconv(dalgona$Content)
corpus = Corpus(VectorSource(corpus))
corpus = tm_map(corpus, tolower)
corpus = tm_map(corpus, removePunctuation)
corpus = tm_map(corpus, removeNumbers)
cleanset = tm_map(corpus, removeWords, stopwords('english'))
removeURL = function(x)gsub('http[[:alnum:]]*','',x)
cleanset = tm_map(cleanset, content_transformer(removeURL))
cleanset = tm_map(cleanset, stripWhitespace)
#Term Document Matrix
tdm = TermDocumentMatrix(cleanset)
tdm = as.matrix(tdm)
tweets = iconv(dalgona$Content, to = 'UTF-8')
s = get_nrc_sentiment(tweets)
#barplot
barplot(colSums(s), las =2, col = rainbow(10), ylab ='Count', main ='Sentiment Scores for Dalgona Coffee')