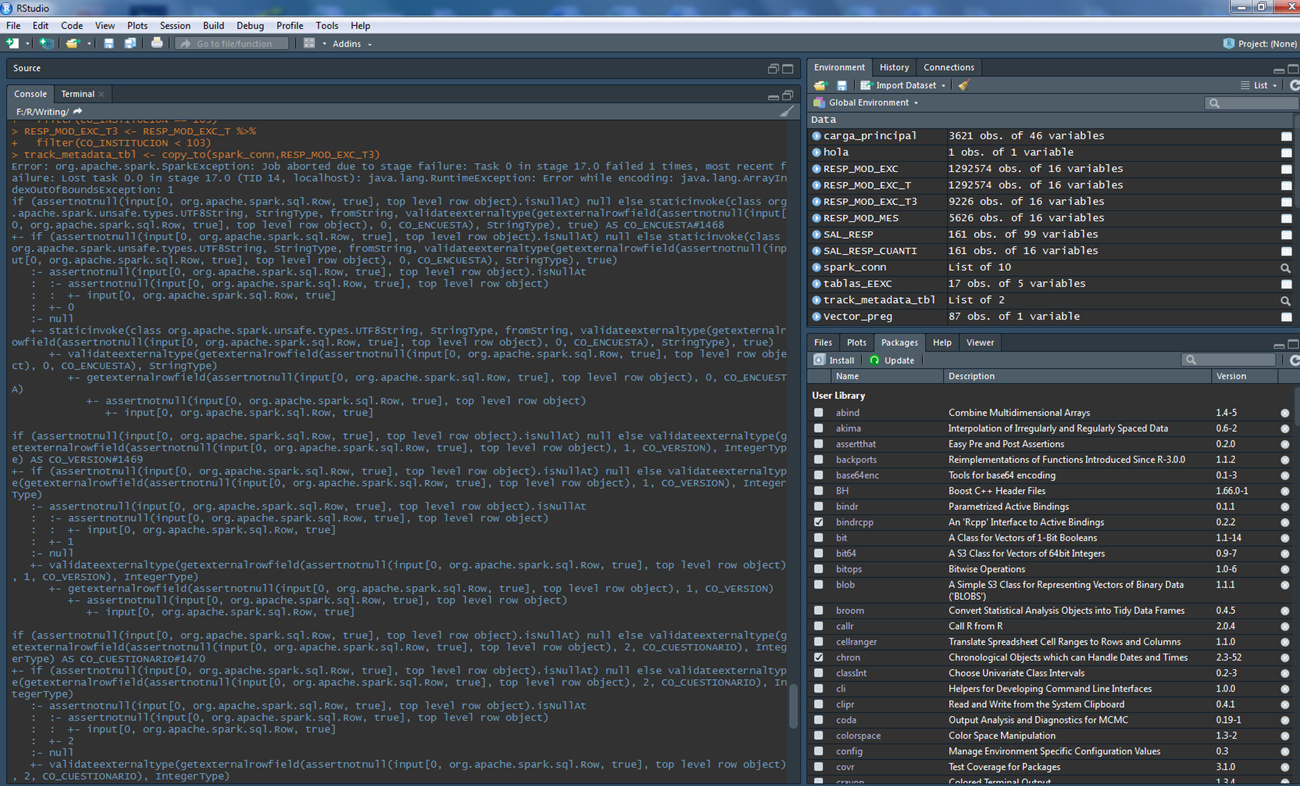
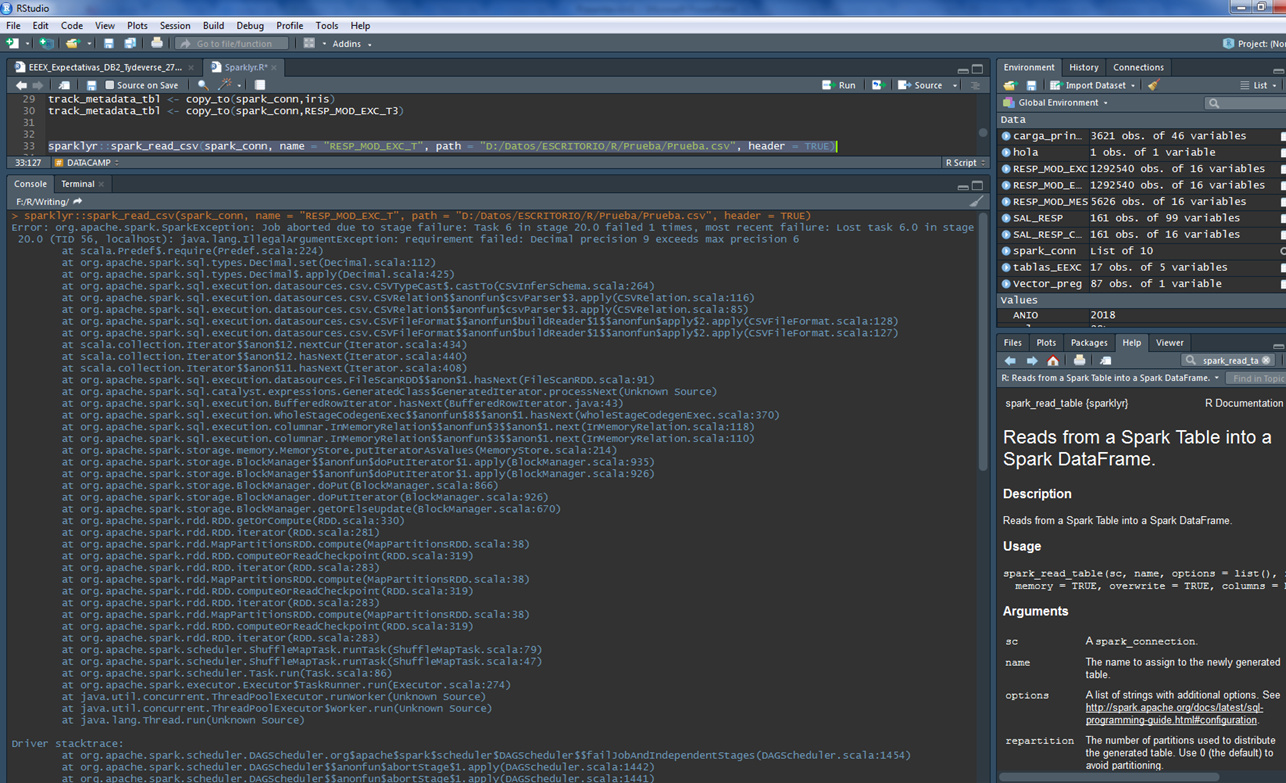
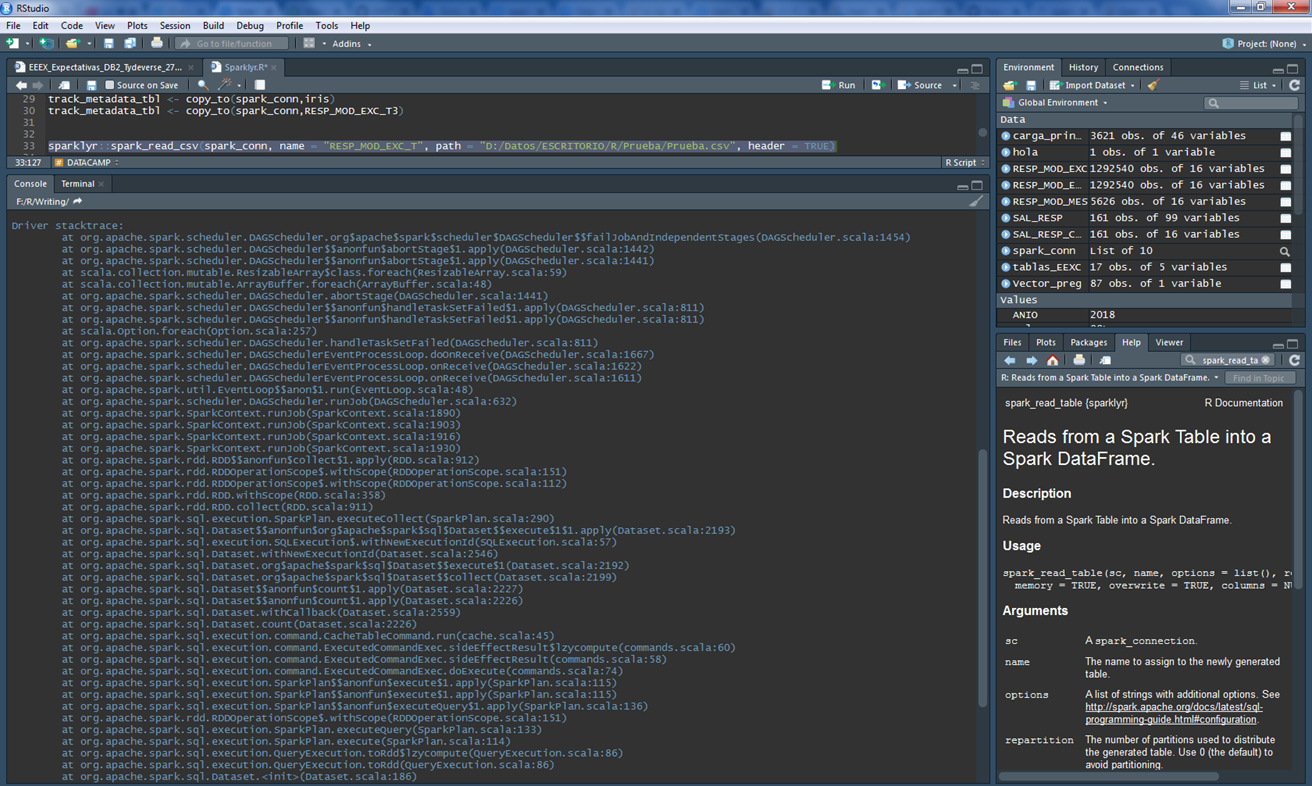
Hi Javier I´m using Sparklyr 2.0.1 take a look the following two examples, the first don´t work but the last one works very well, I really don´t know what´s going on:
> # Connect to your Spark cluster
> spark_conn <- spark_connect("local")
* Using Spark: 2.0.1
>
> # Print the version of Spark
> spark_version(spark_conn)
[1] ‘2.0.1’
> ##################### Example 1 ########################
>
> # Filter Dataset
> RESP_1 <-read_csv("D:/Datos/ESCRITORIO/R/Prueba/Prueba.csv",col_names = T)
Parsed with column specification:
cols(
CO_ENCUESTA = col_character(),
CO_VERSION = col_integer(),
CO_CUESTIONARIO = col_integer(),
CO_CLAVE_RESP = col_double(),
FE_PERIO_REF = col_date(format = ""),
FE_RECEPCION = col_date(format = ""),
CO_INSTITUCION = col_integer(),
CO_APLICACION = col_character(),
CO_ROL_INFORMANTE = col_integer(),
CO_CLAVE_INF = col_integer(),
CO_CIUDAD = col_integer(),
CO_REGION = col_integer(),
CO_ESTADO = col_integer(),
CO_PREGUNTA = col_character(),
CO_CORREL_RESPUEST = col_integer(),
TX_RESPUESTA = col_character()
)
|===============================================================================================================| 100% 219 MB
>
> #Dim RESP_MOD_EXC_T
> dim(RESP_1)
[1] 1292540 16
>
> #Size RESP_MOD_EXC_T
> object_size(RESP_1)
119307832
Error: org.apache.spark.SparkException: Job aborted due to stage failure: Task 6 in stage 4.0 failed 1 times, most recent failure: Lost task 6.0 in stage 4.0 (TID 16, localhost): java.lang.IllegalArgumentException: requirement failed: Decimal precision 9 exceeds max precision 6
at scala.Predef$.require(Predef.scala:224)
at org.apache.spark.sql.types.Decimal.set(Decimal.scala:112)
at org.apache.spark.sql.types.Decimal$.apply(Decimal.scala:425)
at org.apache.spark.sql.execution.datasources.csv.CSVTypeCast$.castTo(CSVInferSchema.scala:264)
at org.apache.spark.sql.execution.datasources.csv.CSVRelation$$anonfun$csvParser$3.apply(CSVRelation.scala:116)
at org.apache.spark.sql.execution.datasources.csv.CSVRelation$$anonfun$csvParser$3.apply(CSVRelation.scala:85)
at org.apache.spark.sql.execution.datasources.csv.CSVFileFormat$$anonfun$buildReader$1$$anonfun$apply$2.apply(CSVFileFormat.scala:128)
at org.apache.spark.sql.execution.datasources.csv.CSVFileFormat$$anonfun$buildReader$1$$anonfun$apply$2.apply(CSVFileFormat.scala:127)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:434)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:440)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:91)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$8$$anon$1.hasNext(WholeStageCodegenExec.scala:370)
at org.apache.spark.sql.execution.columnar.InMemoryRelation$$anonfun$3$$anon$1.next(InMemoryRelation.scala:118)
at org.apache.spark.sql.execution.columnar.InMemoryRelation$$anonfun$3$$anon$1.next(InMemoryRelation.scala:110)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsValues(MemoryStore.scala:214)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:935)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:926)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:866)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:926)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:670)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:281)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:319)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:283)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:319)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:283)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:319)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:283)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:79)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:47)
at org.apache.spark.scheduler.Task.run(Task.scala:86)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:274)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1454)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1442)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1441)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1441)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:811)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:811)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:811)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:1667)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1622)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1611)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:632)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1890)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1903)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1916)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1930)
at org.apache.spark.rdd.RDD$$anonfun$collect$1.apply(RDD.scala:912)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:358)
at org.apache.spark.rdd.RDD.collect(RDD.scala:911)
at org.apache.spark.sql.execution.SparkPlan.executeCollect(SparkPlan.scala:290)
at org.apache.spark.sql.Dataset$$anonfun$org$apache$spark$sql$Dataset$$execute$1$1.apply(Dataset.scala:2193)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:57)
at org.apache.spark.sql.Dataset.withNewExecutionId(Dataset.scala:2546)
at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$execute$1(Dataset.scala:2192)
at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$collect(Dataset.scala:2199)
at org.apache.spark.sql.Dataset$$anonfun$count$1.apply(Dataset.scala:2227)
at org.apache.spark.sql.Dataset$$anonfun$count$1.apply(Dataset.scala:2226)
at org.apache.spark.sql.Dataset.withCallback(Dataset.scala:2559)
at org.apache.spark.sql.Dataset.count(Dataset.scala:2226)
at org.apache.spark.sql.execution.command.CacheTableCommand.run(cache.scala:45)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:60)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:58)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:74)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:115)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:115)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:136)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:133)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:114)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:86)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:86)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:186)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:167)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:65)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:582)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at java.lang.reflect.Method.invoke(Unknow
but in this example works:
##################### Example 2 ########################
> # Filter Dataset
> RESP_3 <-read_csv("D:/Datos/ESCRITORIO/R/Prueba/Prueba.csv",col_names = T) %>%
+ filter(CO_INSTITUCION ==3)
Parsed with column specification:
cols(
CO_ENCUESTA = col_character(),
CO_VERSION = col_integer(),
CO_CUESTIONARIO = col_integer(),
CO_CLAVE_RESP = col_double(),
FE_PERIO_REF = col_date(format = ""),
FE_RECEPCION = col_date(format = ""),
CO_INSTITUCION = col_integer(),
CO_APLICACION = col_character(),
CO_ROL_INFORMANTE = col_integer(),
CO_CLAVE_INF = col_integer(),
CO_CIUDAD = col_integer(),
CO_REGION = col_integer(),
CO_ESTADO = col_integer(),
CO_PREGUNTA = col_character(),
CO_CORREL_RESPUEST = col_integer(),
TX_RESPUESTA = col_character()
)
|===============================================================================================================| 100% 219 MB
>
> write_csv(RESP_3,"D:/Datos/ESCRITORIO/R/Prueba/RESP_3.csv")
>
> RESP_3 <-read_csv("D:/Datos/ESCRITORIO/R/Prueba/RESP_3.csv",col_names = T)
Parsed with column specification:
cols(
CO_ENCUESTA = col_character(),
CO_VERSION = col_integer(),
CO_CUESTIONARIO = col_integer(),
CO_CLAVE_RESP = col_integer(),
FE_PERIO_REF = col_date(format = ""),
FE_RECEPCION = col_date(format = ""),
CO_INSTITUCION = col_integer(),
CO_APLICACION = col_character(),
CO_ROL_INFORMANTE = col_integer(),
CO_CLAVE_INF = col_integer(),
CO_CIUDAD = col_integer(),
CO_REGION = col_integer(),
CO_ESTADO = col_integer(),
CO_PREGUNTA = col_character(),
CO_CORREL_RESPUEST = col_integer(),
TX_RESPUESTA = col_character()
)
>
> #Dim RESP_MOD_EXC_T
> dim(RESP_3)
[1] 2901 16
>
> #Size RESP_MOD_EXC_T
> object_size(RESP_3)
287904