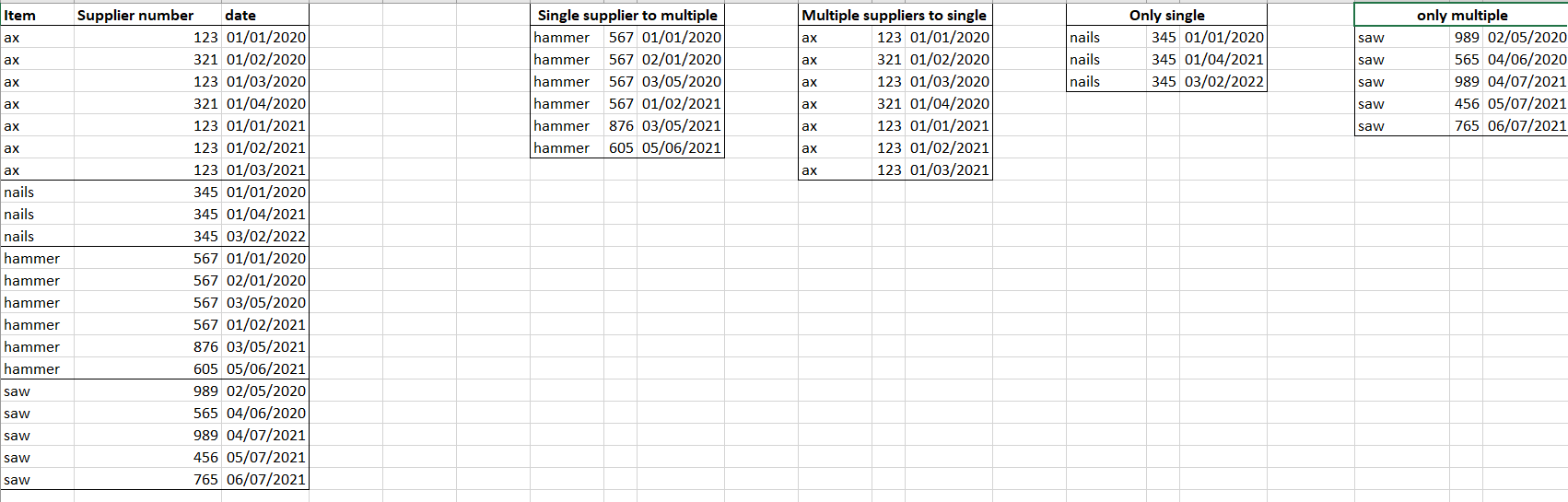
It would help if you shared your data e.g. with dput(), so that we can directly work with it. See here for instructions about making a reprex.
So I just re-typed some minimal example, with fake data:
library(tidyverse)
df <- tibble(item = rep(c("ax","nail","hammer","saw"), each = 3),
supplier_number = c(1,2,2,
3,3,3,
3,3,4,
5,5,6),
date = c("01/01/2020","01/02/2020","01/01/2021",
"01/01/2020","01/02/2020","01/01/2021",
"01/01/2020","01/02/2020","01/01/2021",
"01/01/2020","01/01/2021","01/02/2021")) |>
mutate(date = as.Date(date, "%m/%d/%Y"))
df
#> # A tibble: 12 x 3
#> item supplier_number date
#> <chr> <dbl> <date>
#> 1 ax 1 2020-01-01
#> 2 ax 2 2020-01-02
#> 3 ax 2 2021-01-01
#> 4 nail 3 2020-01-01
#> 5 nail 3 2020-01-02
#> 6 nail 3 2021-01-01
#> 7 hammer 3 2020-01-01
#> 8 hammer 3 2020-01-02
#> 9 hammer 4 2021-01-01
#> 10 saw 5 2020-01-01
#> 11 saw 5 2021-01-01
#> 12 saw 6 2021-01-02
So, first thing, I'll take this data, extract the year from the date, and, for each item, find out what is the first year for which we have data. Then I'll filter the data frame to only keep the first year, and count the number of rows: this tells me how many suppliers we had on the first year.
first_year <- df |>
mutate(year = lubridate::year(date)) |>
group_by(item) |>
filter(year == min(year)) |>
ungroup() |>
select(item, supplier_number) |>
distinct() |>
group_by(item) |>
summarize(nb_suppliers_first_year = n())
first_year
#> # A tibble: 4 x 2
#> item nb_suppliers_first_year
#> <chr> <int>
#> 1 ax 2
#> 2 hammer 1
#> 3 nail 1
#> 4 saw 1
Similarly, I can find out how many suppliers we had on the other years: this time I'll filter the data frame to keep only, for each item, the rows which do NOT correspond to the first year:
later_years <- df |>
mutate(year = lubridate::year(date)) |>
group_by(item) |>
filter(year != min(year)) |>
ungroup() |>
select(item, supplier_number) |>
distinct() |>
group_by(item) |>
summarize(nb_suppliers_later_years = n())
later_years
#> # A tibble: 4 x 2
#> item nb_suppliers_later_years
#> <chr> <int>
#> 1 ax 1
#> 2 hammer 1
#> 3 nail 1
#> 4 saw 2
Now that I have this data for each item, I can re-inject that into the initial dataframe:
df2 <- df |>
left_join(first_year,
by = "item") |>
left_join(later_years,
by = "item")
df2
#> # A tibble: 12 x 5
#> item supplier_number date nb_suppliers_first_year nb_suppliers_later~
#> <chr> <dbl> <date> <int> <int>
#> 1 ax 1 2020-01-01 2 1
#> 2 ax 2 2020-01-02 2 1
#> 3 ax 2 2021-01-01 2 1
#> 4 nail 3 2020-01-01 1 1
#> 5 nail 3 2020-01-02 1 1
#> 6 nail 3 2021-01-01 1 1
#> 7 hammer 3 2020-01-01 1 1
#> 8 hammer 3 2020-01-02 1 1
#> 9 hammer 4 2021-01-01 1 1
#> 10 saw 5 2020-01-01 1 2
#> 11 saw 5 2021-01-01 1 2
#> 12 saw 6 2021-01-02 1 2
At this point, we're done, we can simply filter, for example to keep the rows where the number of suppliers first year is 1 and there are more than 1 suppliers in the other years (and we can do something similar for all your combinations of interest):
df2 |>
filter(nb_suppliers_first_year == 1,
nb_suppliers_later_years > 1)
#> # A tibble: 3 x 5
#> item supplier_number date nb_suppliers_first_year nb_suppliers_later_y~
#> <chr> <dbl> <date> <int> <int>
#> 1 saw 5 2020-01-01 1 2
#> 2 saw 5 2021-01-01 1 2
#> 3 saw 6 2021-01-02 1 2
Created on 2022-05-10 by the reprex package (v2.0.1)