Hey there,
I´ve created a dataframe for work which includes a bunch of different company. First cloumn is the name of the company, so now I want to add a second one which contains the sector this company appears in. I´ve already created a list with the kind of sector and which company does fit into that specific one. For Example sector "Industrials" includes "3M|Abbott|....". I was looking for a stringr solution, but can´t get it work. Is there any easy way to match my first coloumn with my list of sectors and letting it add into a second coloumn? First: 3M Second: Industrial and so on with every company.
Already thanks for every answer!
Can you provide a reprex (FAQ: How to do a minimal reproducible example ( reprex ) for beginners )? It is hard to know exactly what your data looks like and then we can see if the solution works on a subset of your data.
###pdf documents into data###
files<-list.files(pattern="pdf$", full.name=TRUE)
###split data and match the text###
filestextdataframe<-data.frame(Document=files,text = sapply(files, function(x) paste0(pdf_text(x), collapse = " ")))
###select only sentences including privacy"
corpus_privacy_sentences <- corpus(filestextdataframe$text)
tok_privacy_sentences <- tokens_select(tokens(corpus_privacy_sentences, what = "sentence"), pattern = "privacy", valuetype = "regex", selection = "keep")
###finished data,frame###
Table<-data.frame(Company= str_extract(filestextdataframe$Document, "3M|Abbott|AbbVie|Accenture|Adobe|ADP|AdvancedMicroDevices|alphabet|Altria|amazon|AmericanExpress|Amgen|Anthem|apple|AppliedMaterials|AT&T|BerkshireHathaway|BlackRock|Boeing|Booking|Bristol-MyersSquibb|Broadcom|Caterpillar|CharlesSchwab|Charter|Chevron|Cigna|Cisco|Citi|CocaCola|Comcast|Costco|CrownCastle|CVSHealth|Danaher|Deere|DukeEnergy|EliLilly|Exxon|facebook|Fidelity|GeneralElectric|GileadSciences|HomeDepot|Honeywell|Intel|Intuit|IntuitiveSurgical|Johnson&Johnson|JP|Lam|Linde|LockheedMartin|Lowe's|Mastercard|McDonalds|Medtronic|Merck|MicronTechnology|Mondelez|MorganStanley|Netflix|Nexteraenergy|Nike|NVIDIA|OracleCorporation|P&G|PayPal|PepsiCo|Pfizer|PhilipMoris|Prologis|Qualcomm|Raytheon|S&P|Salesforce|Servicenow|Starbucks|Stryker|T-Mobile|Target|Tesla|TexasInstruments|Thermo_Fisher_Scientific|TJX|UnionPacificCoporation|UnitedHealthGroup|UPS|Verizon|Visa|Walmart|WaltDisney|WellsFargo"),
Report=str_extract(filestextdataframe$Document, "annual|transcript|quarterly"),
Quartal=str_extract(filestextdataframe$Document, "annual|q1|q2|q3|q4"),
Date=str_extract(filestextdataframe$Document, "2015|2016|2017|2018|2019|2020|2021"),
Text=sapply(files, function(x) paste0(pdf_text(x), collapse = " ")),
privacy=sapply(tok_privacy_sentences, function(x) paste(as.character(x), collapse = " ")),
sector= ) ###new coloumn with matching sectors
####sector table###
sector_data<-list(
industrials=c("3M","Boeing","Caterpillar","Deere","GeneralElectric","Honeywell","LockheedMartin","Raytheon","UnionPacificCoporation","UPS"),
health_care=c("Abbott","AbbVie","Amgen","Anthem","Bristol","Cigna","CVSHealth","Danaher","EliLilly","GileadSciences","IntuitiveSurgical","Johnson&Johnson","MedTronic","Merck","Pfizer","Stryker","Thermo_Fischer_Scientific","UnitedHealthGroup"),
cummunication_services=c("Alphabet","AT&T","Charter","Comcast","Facebook","Netflix","T-Mobile","Verizon","WaltDisney"),
information_technology=c("Accenture","Adobe","Adobe","AdvancedMicroDevices","Apple","AppliedMaterials","Broadcom","Cisco","Fidelity","Intel","Intuit","Lam","Mastercard","MicronTechnology","NVIDIA","OracleCorporation","PayPal","Qualcomm","Salesforce","Servicenow","TexasInstruments","Visa"),
consumer_discretionary=c("Amazon","Booking","HomeDepot","Lowes","McDonalds","Nike","Starbucks","Target","Tesla","TJX"),
utilities=c("DukeEnergy","Nexteraenergy"),
financials=c("AmericanExpress","BerkshireHathaway","BlackRock","CharlesSchwab","Citi","JP","MorganStanley","S&P","WellsFargo"),
materials=c("Linde"),
real_estate=c("CrownCastle","Prologis"),
consumer_staples=c("Altria","CocaCola","Costco","Mondelez","P&G","PepsiCo","PhilipMoris","Walmart"),
energy=c("Chevron","Exxon"))
thats the code I got so far, sorry it´s a bit messy, don´t know how to post it properly tbh.
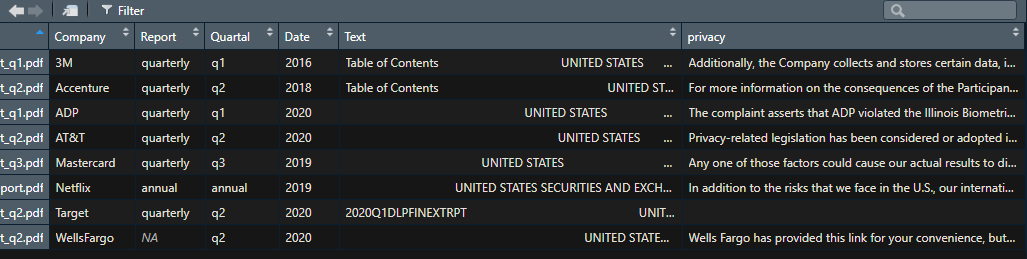
Hi @ricdob ,
I cannot replicate all of your code since it uses your local files.
I can only use your sector_data list.
But you can try to adapt the code below:
sector_data<-list(
industrials=c("3M","Boeing","Caterpillar","Deere","GeneralElectric","Honeywell","LockheedMartin","Raytheon","UnionPacificCoporation","UPS"),
health_care=c("Abbott","AbbVie","Amgen","Anthem","Bristol","Cigna","CVSHealth","Danaher","EliLilly","GileadSciences","IntuitiveSurgical","Johnson&Johnson","MedTronic","Merck","Pfizer","Stryker","Thermo_Fischer_Scientific","UnitedHealthGroup"),
cummunication_services=c("Alphabet","AT&T","Charter","Comcast","Facebook","Netflix","T-Mobile","Verizon","WaltDisney"),
information_technology=c("Accenture","Adobe","Adobe","AdvancedMicroDevices","Apple","AppliedMaterials","Broadcom","Cisco","Fidelity","Intel","Intuit","Lam","Mastercard","MicronTechnology","NVIDIA","OracleCorporation","PayPal","Qualcomm","Salesforce","Servicenow","TexasInstruments","Visa"),
consumer_discretionary=c("Amazon","Booking","HomeDepot","Lowes","McDonalds","Nike","Starbucks","Target","Tesla","TJX"),
utilities=c("DukeEnergy","Nexteraenergy"),
financials=c("AmericanExpress","BerkshireHathaway","BlackRock","CharlesSchwab","Citi","JP","MorganStanley","S&P","WellsFargo"),
materials=c("Linde"),
real_estate=c("CrownCastle","Prologis"),
consumer_staples=c("Altria","CocaCola","Costco","Mondelez","P&G","PepsiCo","PhilipMoris","Walmart"),
energy=c("Chevron","Exxon"))
library(tidyverse)
#transform your list into a dataframe:
sector_data <- sector_data %>%
enframe() %>%
unnest_longer(value) %>%
rename('industry' = 'name', "company" = 'value')
#create bogus sample data (I use some company names from sector_data)
set.seed(6546)
sample_data <- tibble(
company = sample(sector_data$company, 20),
sales = rnorm(20, 10000, 8000)
)
#then you can do a left_join
sample_data %>% left_join(sector_data, by = "company")
Hope it helps.
Thanks a lot it fixed some of my issues, but not the main part. Maybe I just had some problems writing it down specificly. I´d like to add the coloumn industry, which you did with the leftjoin command, into the main Data.Frame from the beginning. The one that you couldn´t use because of the missing pdf data files I´m using. Also the one which I uploaded as a JPG. Just want to everything have in one DF.
Sorry I´m kinda new to R, not knowing specific vocabulary or commands ![]()
Don't be sorry, it takes time to get up to scratch, but you'll be surprised it comes quite quickly.
I'm not sure by what you mean with "from the beginning".
Or maybe I forgot to assign the changed dataframe (with added column) to the dataframe itself.
If so, try this:
#same as previously, transform list into a dataframe (I just uppercased the column names to match the example in your screenshot)
sector_data <- sector_data %>%
enframe() %>%
unnest_longer(value) %>%
rename('Industry' = 'name', "Company" = 'value')
#this time you assign the changed Table to the Table object itself
Table <- Table %>% left_join(sector_data, by = "Company")
But let me know if I didn't get your question right.
If you plan on doing more with R, you can check this must-read book: https://r4ds.had.co.nz/
And this one has a very smooth learning curve: R for Excel Users
1 Like
Thanks a lot, I had to adjust my main table a little but, but managed to get it work with your code! ![]()
Also thanks for the fourther information about R, gonna read the book for sure!
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.
If you have a query related to it or one of the replies, start a new topic and refer back with a link.