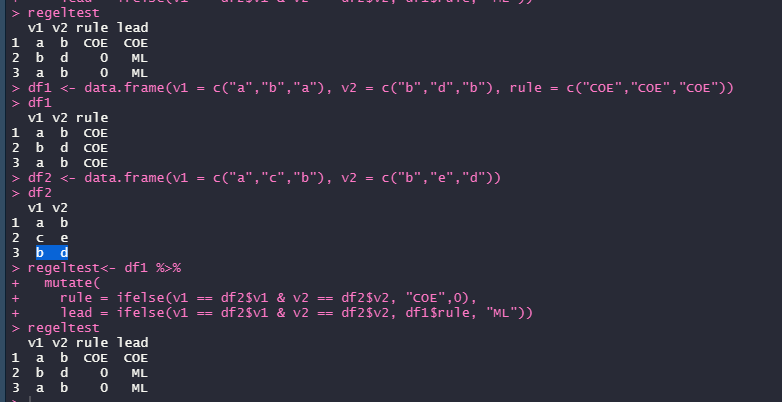Hi Rcommunity
got 2 dataframes:
df1<- structure(list(v1 = c("a", "b", "a"), v2 = c("b", "d", "e"),
rule = c("COE", "COE", "COE")), class = "data.frame", row.names = c(NA,
-3L))
df2 <- structure(list(v1 = c("a", "c", "g"), v2 = c("b", "e", "d")), class = "data.frame", row.names = c(NA,
-3L))
Im trying to match the rows in df1 and df2 , the code:
regeltest<- df1 %>% mutate(
rule = ifelse(v1 %in% df2$v1 & v2 %in% df2$v2, "COE",0),
lead = ifelse(v1 %in% df2$v1 & v2 %in% df2$v2, df1$rule, "ML"))
so when v1 and v2 match in both df1 and df2 it mutates COE and otherwise 0, same for lead
the correct answer should look like:
correct <- structure(list(v1 = c(2, 3, 2), v2 = c(3, 4, 5), rule = c("COE",
"0", "0"), lead = c("1", "ML", "ML")), class = "data.frame", row.names = c(NA,
-3L))